







前言
首先,说两个常识:
1、非结构化数据处理、存储、价值挖掘成本高于传统结构化数据。
2、一旦数据的计算与存储成本上升到一个超过实际业务价值的临界点,数据就从宝藏,变成了电子垃圾,价值无法被挖掘。
关于如何降本,Milvus提供了以下几种办法:高效索引降低计算开销、冷热数据降低内存开销、向量数据湖复用企业已有基础设施等等。
除此之外,向量量化技术也是我们做成本控制时的重要手段。
一般来说,非结构化数据会在切片后被转化为一组高维向量。其中,高维向量本身,又通常由数百个浮点数组成(如 768 维 FP32 向量占用约 3 KB),据此线性推算如果用 HNSW索引(一种流行的 ANN 算法)来处理 10 亿个 768 维 FP32 向量,将需要超过 3TB 内存。
但对于向量检索而言,使用全精度的 FP32本质上是一种冗余。
相应的,在工程实现上,我们可以通过量化技术,将原始向量进行压缩,去除冗余信息。其中,压缩最极致的形式是 1-bit 量化,也叫二值量化(Binary Quantization),它将每个维度的浮点值压缩为 1 个比特,整体内存占用是 FP32精度的 1/32 ,同时降低内存带宽需求,大幅提升整体吞吐量。
但传统二值量化的问题是:召回率通常较低,难以满足生产需求。
近期,Milvus 通过集成 RaBitQ 技术实现了突破——在保持高召回率的同时,**同时实现 1-bit 量化,**查询吞吐量(QPS)提升至原来的 3 倍。
**一句话概括RabitQ的革命性,Not only RBQ, but also Revolutionary binary quantazition,既实现了一比特的极度量化,又能保证高 recall。**接下来,我们将深入解析我们在 Milvus 及 Zilliz Cloud(全托管 Milvus 服务)中实现 RaBitQ 的工程实践。
01
为什么说RaBitQ才是最好的向量量化算法
在解读RaBitQ之前,我们需要先理解一句话:高维数据的随机性会带来高度的确定性。
这背后是一个基础的高维几何概念:高维向量空间遵循测度集中”(Concentration of Measure)现象。而基于测度集中,我们会发现一些神奇的现象,举例来说:
- 当向量 x 是 3 维时, x[0] (高维向量
x的第一个坐标分量)会位于区间 [−1,+1] 内。 - 但是当 x 是 1000 维时,测度集中现象告诉我们 x[0] 以很高的概率会落在这个范围内。由于 D 很大,这其实对 x[0] 提供了一个更紧的约束范围。
也就是说,我们既没有读取任何数据,也没有进行任何计算,就会发现高维向量空间中,维度越高, x[0] 的不确定性越低:其可能的取值范围从 [−1,1] 缩小到了 。
这使得我们可以舍弃大量原始的数值精度,同时仍然保留足够的相对结构信息,以实现准确的最近邻搜索。
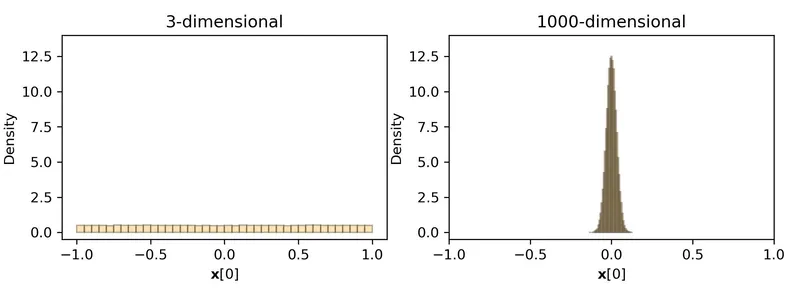
对于在单位球面上均匀分布的随机单位向量而言:在三维空间中,单个维度的取值呈均匀分布;但在 1000 维空间中,每个维度的取值会高度集中于零。(来源:https://dev.to/gaoj0017/quantization-in-the-counterintuitive-high-dimensional-space-4feg)
基于这一高维性质,RaBitQ 的核心思想是采用角度信息编码替代精确坐标存储。具体实现分为两步:
- 向量归一化:以参考点(如数据集质心)为基准对数据向量进行归一化处理,保留方向特征
- 超立方体投影:将归一化后的向量映射到高维超立方体的最近顶点,每个维度仅需 1 位存储
这种方法也自然扩展为 IVF_RaBitQ:在该架构下,归一化是相对于最近的聚类中心进行的,从而提升了局部区域的编码精度。
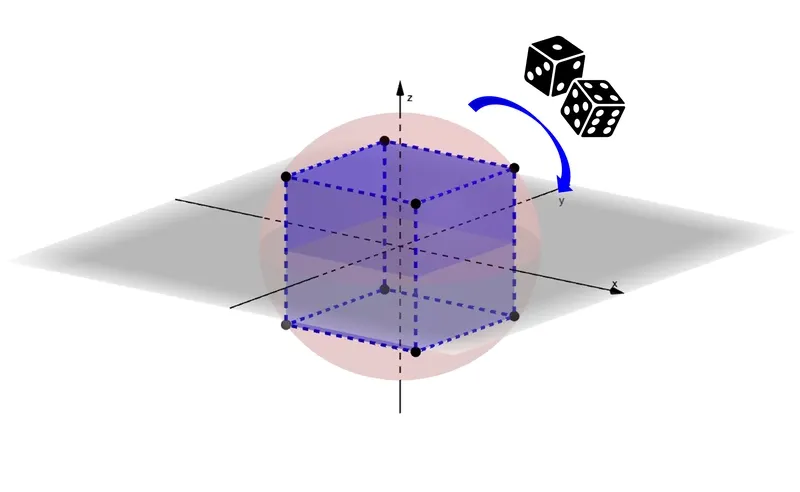
可以通过在超立方体上寻找与原向量最接近的近似向量来对其进行压缩,因为这样每个维度仅需 1 bit 进行存储。(来源:https://dev.to/gaoj0017/quantization-in-the-counterintuitive-high-dimensional-space-4feg)
为了确保即使在高度压缩的表示下仍能保持搜索的可靠性,RaBitQ 还引入了一个具有理论基础的无偏距离估计器,用于估算查询向量与已量化向量之间的距离,从而在实现最小化重构误差的同时保障了召回率(recall)。
除此之外,RaBitQ还具备以下核心优势:
- 训练轻量:仅需确定各维度符号位,仅需判断向量各维分量的符号即可完成编码,无需复杂参数优化
- 硬件友好:在搜索阶段,利用现代 CPU 的按位运算指令(如 popcount)加速搜索
- 生态兼容:可与 FastScan、随机旋转预处理等技术栈无缝集成
以上优化组合,使得RaBitQ 相比于市面上其他向量数据库的实现的**二值量化(Binary Quantization)的压缩算法(**比如Qdrant 、weaviate的 Binary Quantization),能够以极低的精度牺牲为条件,实现高吞吐、低延迟的向量搜索。
02
Milvus 工程实践:如何落地 RaBitQ?
虽然 RaBitQ 的核心原理相对简单,也附有参考实现
(见 https://github.com/gaoj0017/RaBitQ)
但要把它真正落地到像 Milvus 这样面向生产的分布式向量数据库里,依然会碰到不少工程细节需要权衡和优化。我们已经在 Knowhere(Milvus 底层的高性能向量检索引擎)中完成了 RaBitQ 的落地实现,并把一个性能更优的版本贡献给了 FAISS 社区。以下是几个关键设计点:
- 辅助数据的存储与计算策略RaBitQ 要求每个向量额外携带两个浮点值,以及一个可选常数的第三值,第三个可选常数既可以在查询时动态计算,也可以在训练/索引阶段预先生成并存储。在 Knowhere 中,我们选择在构建索引时提前计算并保存这第三个值,把运行时的开销降到最低,以最大化查询吞吐和响应速度。而FAISS 社区版则偏向于在搜索时动态计算这个常数,以减少内存占用;两种方案分别在存储成本和运行速度上做出了不同的权衡。
- 基于现代 CPU 指令集的距离计算加速RaBitQ 的距离度量核心是对二进制向量做按位 popcount。Knowhere 针对支持 AVX-512 的硬件(如 Intel Ice Lake 系列或 AMD Zen 4 及以上)专门启用了
VPOPCNTDQ指令路径,大幅提升了二值距离计算速度,通常能达到默认实现的几倍性能。
- 多级标量量化 (SQ1–SQ8) 支持为了进一步降低计算与内存开销,Knowhere 和 FAISS 都集成了对查询向量的 1-8 位标量量化方案(SQ1–SQ8)。实测表明,即便下至 4 位量化,也能在显著降低算力需求的同时,保持良好的检索召回率,对需要极高吞吐的场景非常友好。
- Zilliz Cloud 专有的 Cardinal 引擎增强在开源基础之外,我们为 Zilliz Cloud 平台打造的 Cardinal 引擎加入了更多专有优化层,包括与图索引的深度集成、对 Arm 架构的完整支持,支持 Arm SVE 向量化指令,以及多项底层算法改进,进一步提升了向量检索的灵活性和效率。
通过这些针对性优化,Milvus 版的 RaBitQ 在跨平台兼容性、存储-性能平衡以及大规模高并发查询处理能力上,都达到了生产级向量数据库的要求,提供了一套成熟、高效、可扩展的解决方案。
03
实测突破:RaBitQ 如何实现3 倍 QPS 提升?
从 Milvus 2.6 开始,我们将推出全新的 IVF_RABITQ 索引类型,融合了 RaBitQ、IVF 倒排索引、随机旋转变换(Random Rotation)以及后处理优化机制(refinement),在高效压缩和高精度检索之间取得更优平衡。
from pymilvus import MilvusClient
index_params = MilvusClient.prepare_index_params()
index_params.add_index(
field_name="your_vector_field_name", # Name of the vector field to be indexed
index_type="
IVF_RABITQ
", # Will be introduced in Milvus 2.6
index_name="vector_index", # Name of the index to create
metric_type="IP", # IVF_RABITQ supports IP and COSINE
params={
"nlist": 1024, # IVF param, specifies the number of clusters
} # Index building params
)
我们基于开源基准工具 vdb-bench 在 AWS EC2 m6id.2xlarge 实例上,对 Milvus Standalone 版进行了对比测试。该实例配备 Intel Xeon 8375C(Ice Lake 架构,支持 AVX-512 的 VPOPCNTDQ 指令)、8 线程、32 GB RAM。在 100 万向量、768 维场景下,使用 vdb-bench 的搜索性能测试(Search Performance Test (1M dataset, 768 dim))进行评估。
Milvus 默认将数据分成每段 1 GB 大小;对于本次测试,768 × 100 万条 FP32 向量(约 3 GB 原始数据)会被分配到多个 segment 中执行,确保基准结果具有良好的可重现性与扩展性。
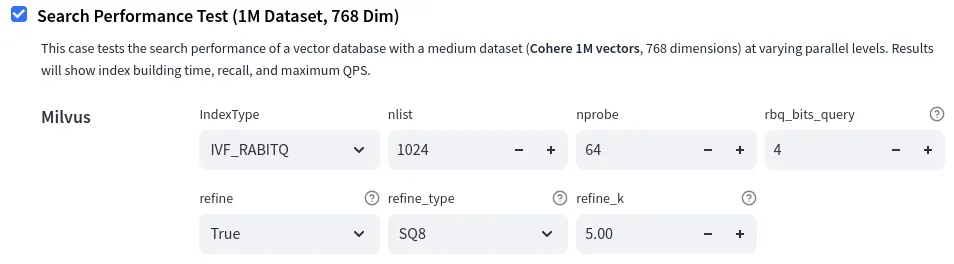
配置参数细节
以下是关于 IVF、RaBitQ 以及精调过程(refinement)过程的一些底层配置参数说明:
-
nlist和nprobe是所有基于 IVF 方法的标准参数:nlist:一个非负整数,表示整个数据集被划分成的 IVF 分桶(bucket)数量。nprobe:一个非负整数,表示在搜索过程中为每个查询向量访问的 IVF 分桶数量。- 属于与搜索相关的参数。
-
rbq_bits_query指定查询向量的量化级别:- 可选值为 1 到 8,对应 SQ1 到 SQ8 的量化等级。
- 设置为 0 时表示不对查询向量进行量化。
- 属于搜索相关参数。
-
refine、refine_type和refine_k是用于精排过程的标准参数:refine:布尔值,表示是否启用精排策略。refine_k:一个非负浮点数,表示精排时所选候选池的放大倍数。系统将从一个大小为refine_k倍的候选集合中,使用更高精度的量化方式选出最终的近邻结果。属于搜索相关参数。refine_type:字符串,指定用于精排阶段的量化类型。可选值包括SQ6、SQ8、FP16、BF16和FP32/FLAT(无压缩的原始精度)。
测试结果
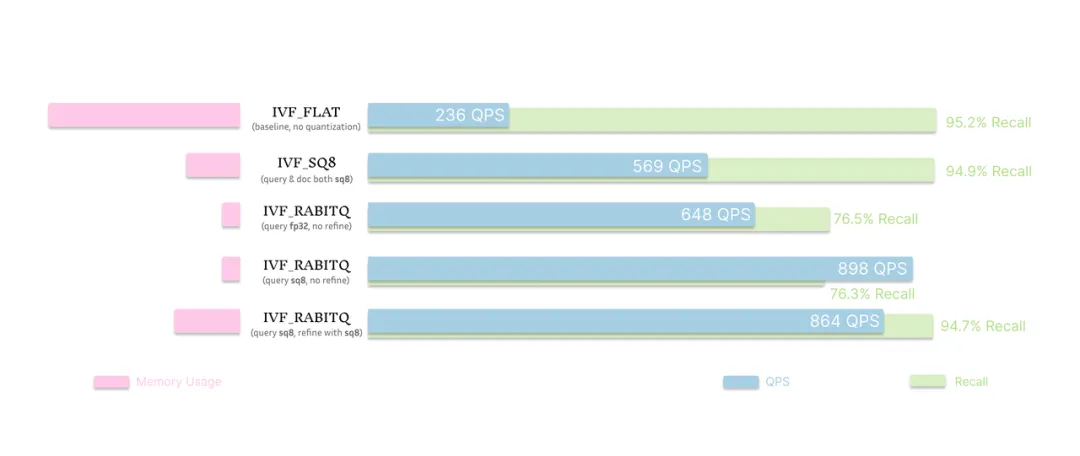
结果显示,经过精调的IVF_RABITQ 带来了显著的性能提升。与基线索引 IVF_FLAT 相比(该索引在 95.2% 召回率下达到 236 QPS),IVF_RABITQ 在吞吐量上有显著优势——在使用 FP32 查询时可达 648 QPS,而在配合 SQ8 量化查询时更是达到 898 QPS。
不过,这种性能提升也带来了召回率的牺牲。当 IVF_RABITQ 未启用 refinement 时,召回率稳定在约 76%,对于要求高精度的应用可能无法满足。但即便如此,在使用 1-bit 向量压缩的情况下实现这一召回率,仍然是非常难得的。
要提升精度,refinement 是关键。当配置为 SQ8 查询 + SQ8 refinement 时,IVF_RABITQ 实现了高性能与高召回的双赢:召回率高达 94.7%,几乎与 IVF_FLAT 持平,同时吞吐量达到 864 QPS,是 IVF_FLAT 的 3 倍以上。即使与另一种常用量化索引 IVF_SQ8 相比,IVF_RABITQ + SQ8 refinement 在相似召回率下也实现了超过一半的吞吐量,且成本增加微乎其微。
简而言之,如果希望在“可接受的召回率”下最大化吞吐量,IVF_RABITQ 是一个非常优秀的选择;而在搭配 refinement 后,效果更佳,不仅大幅提升了性能与准确率,同时所占内存相比 IVF_FLAT 更小,非常适合对速度和精度都有要求的场景。
04
结论
RaBitQ 技术的引入为 Milvus 向量数据库在性能与成本的平衡上树立了新的标杆。通过充分利用高维空间的几何特性与硬件加速能力,RaBitQ 在保证召回率的前提下,实现了查询吞吐量(QPS)的 3 倍提升,同时显著降低了存储与计算资源消耗。
此外,通过结合 IVF 架构与多级精调策略,这一技术不仅为大规模向量检索场景提供了高效的解决方案,也为企业应对数据激增与成本压力提供了关键支持。Milvus 在 Knowhere 引擎与 Zilliz Cloud 平台中的工程实践,进一步验证了 RaBitQ 在生产环境中的可靠性与扩展性。
随着 AI 应用的爆发式增长,向量数据库的底层技术革新将愈发关键。Milvus 团队将持续深耕向量压缩与检索优化,助力开发者以更低成本、更高效率解锁数据价值,推动智能时代的技术边界不断拓展。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









