







学习了几天如何使用scrapy去爬取静态网站,今天尝试去爬取动态加载的网站。选取的网站是华尔街见闻,文中不会像往常一样大篇幅讲解每一步该如何做,而是探讨如何爬取。
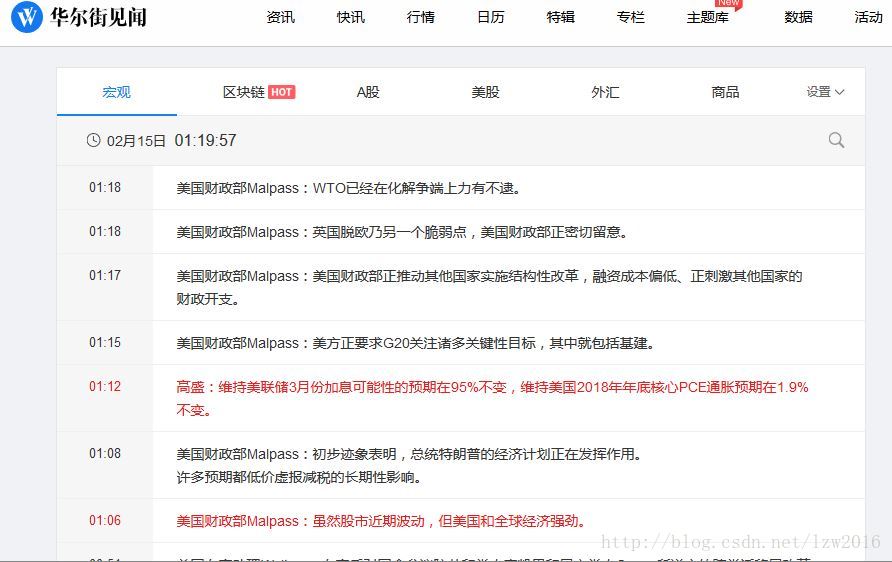
在源代码中无法获得全部数据(有的根本没数据),但是通过下拉滑条可以看到网址不变但有数据加载出来,毫无疑问这就是动态加载的网页。以下讲解如何去寻找api接口取获取数据。
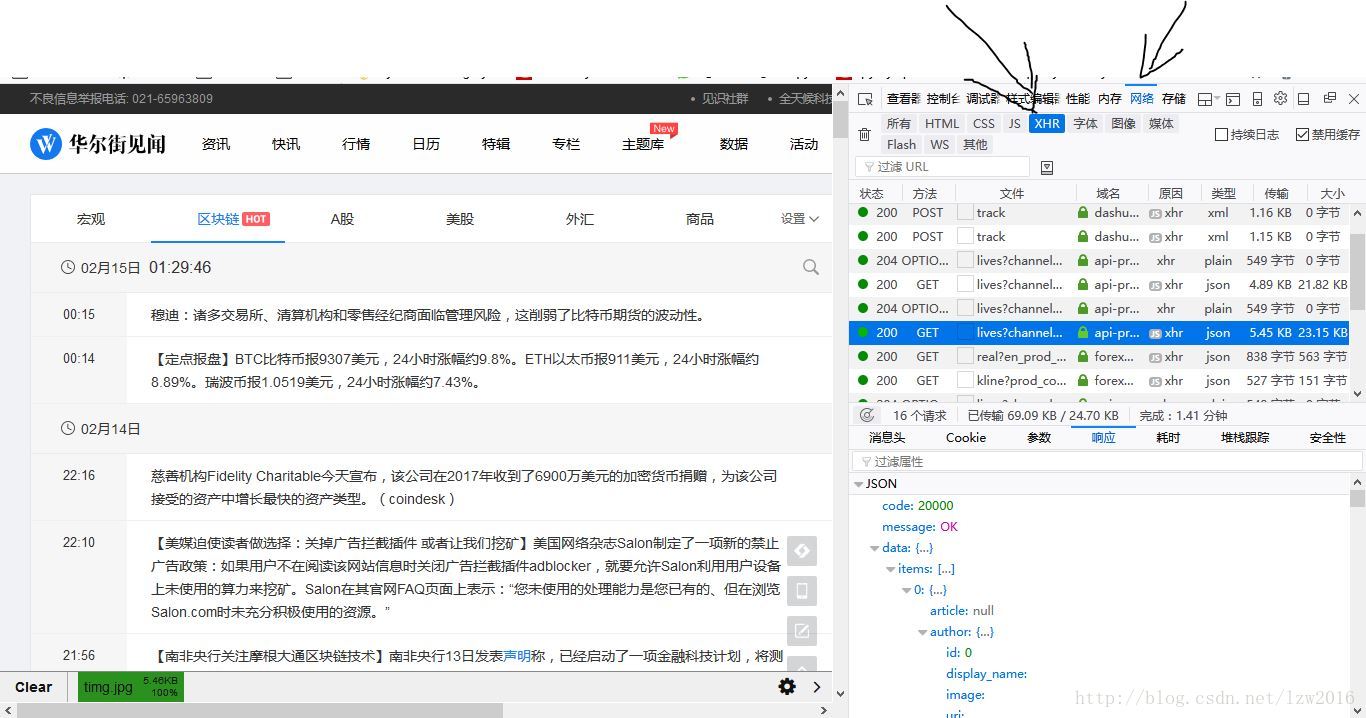
打开开发者工具,选择Network,刷新,选择XHR,如图。
 本文介绍了如何使用Scrapy爬取动态加载的华尔街见闻网站,特别是针对区块链数据的抓取。通过分析浏览器的网络请求,找出API接口`https://api-prod.wallstreetcn.com/apiv1/content/lives?channel=blockchain-channel&client=pc&cursor=1518567654&limit=20`,确定关键参数,揭示了动态加载的机制,包括cursor参数与时间戳的关系,并提供了其他板块数据的API接口。
本文介绍了如何使用Scrapy爬取动态加载的华尔街见闻网站,特别是针对区块链数据的抓取。通过分析浏览器的网络请求,找出API接口`https://api-prod.wallstreetcn.com/apiv1/content/lives?channel=blockchain-channel&client=pc&cursor=1518567654&limit=20`,确定关键参数,揭示了动态加载的机制,包括cursor参数与时间戳的关系,并提供了其他板块数据的API接口。
学习了几天如何使用scrapy去爬取静态网站,今天尝试去爬取动态加载的网站。选取的网站是华尔街见闻,文中不会像往常一样大篇幅讲解每一步该如何做,而是探讨如何爬取。
在源代码中无法获得全部数据(有的根本没数据),但是通过下拉滑条可以看到网址不变但有数据加载出来,毫无疑问这就是动态加载的网页。以下讲解如何去寻找api接口取获取数据。
打开开发者工具,选择Network,刷新,选择XHR,如图。

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言




 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1186
1186





