







“你说我虽然是个普通人,我也想人家关注我啊,我也想有女孩喜欢我啊,我也想有什么东西可以吹牛啊......总不能因为我没本事很普通,就当一辈子的路人甲吧?那有什么意思啊?可在家里我真的是什么都没有,”他摊了摊手,“什么都没有......我饿了,你有没有什么吃的?”
阅读提要
全文约4.8K字,大致阅读完约6分钟,包含主要知识点:HTTP状态码,网页跳转方式,404错误页面种类,定制型网址404识别,通用型404页面识别,其中关键部位文字使用橙色重点标注,网址使用绿色重点标注,具体代码结果保存在文末。
目录:
-
状态码信息
-
页面跳转方式
-
404页面种类
-
针对单一网址404页面识别
-
针对通用型网址404页面识别
状态码
当浏览者访问一个网页时,浏览者的浏览器会向网页所在服务器发出请求。当浏览器接收并显示网页前,此网页所在的服务器会返回一个包含HTTP状态码的信息头(server header)用以响应浏览器的请求。
HTTP状态码的英文为HTTP Status Code。
下面是常见的HTTP状态码:
200 - 请求成功
301 - 资源(网页等)被永久转移到其它URL
404 - 请求的资源(网页等)不存在
500 - 内部服务器错误
如下图所示就是请求一个错误页面返回的请求头信息,其中状态码为304。
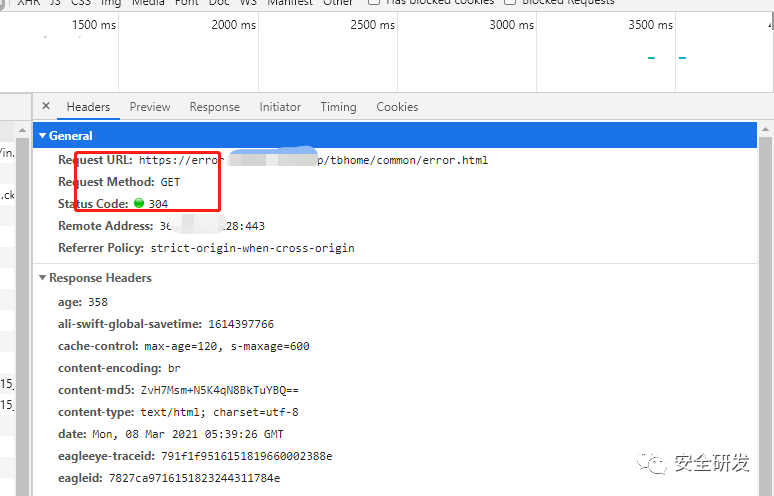
状态码都会在请求头中显示,本文中重点探讨在渗透测试的信息收集中对网址进行扫描中遇到的404页面自动识别的解决方案。
页面跳转
当访问一个不存在的网页时,服务器默认会进行自动跳转到其他网页或者返回不存在页面,按照经验URL跳转方式可以分成两种,第一种是服务端设置好后的客户端跳转,第二种是经过服务端处理后进行的跳转。最后就是默认的错误页面信息了,下面三种都是不存在的错误页面信息,但是返回的状态码都是不一样的,需要结合在一起分析处理。
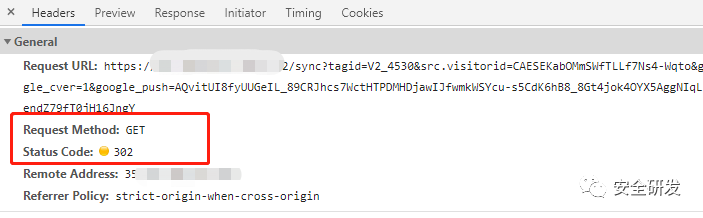
第一种客户端浏览器自动跳转,默认返回的状态码是301或者302,然后由经过设置好的规则开始跳转到下一个页面,这种方式使用代码识别比较简单。
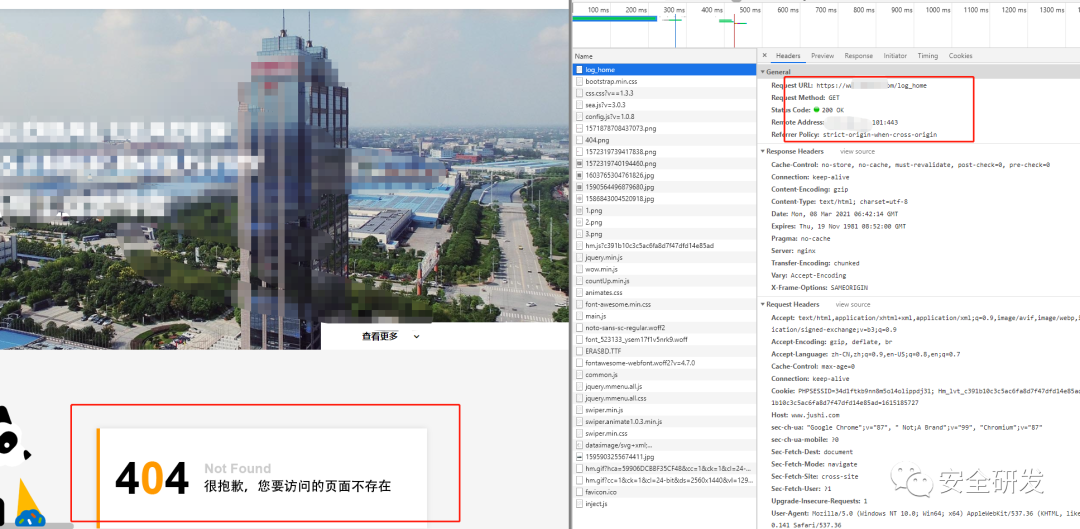
第二种服务端对请求进行处理分析后跳转,是由服务器进行处理请求后,服务端发现页面不存在,但是还是给你返回200状态码然后给你跳转到正常页面,将结果从后端发送给前端,获取的状态码是200,该种方式使用代码进行识别难度稍大。
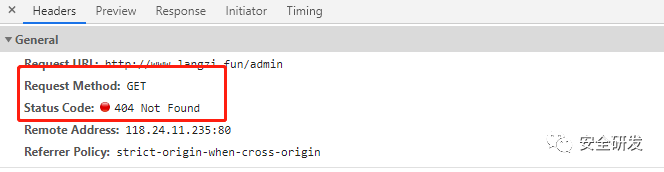
第三种默认的方式是如果网页不存在,则会自动返回404状态码和相关错误界面。
404页面种类
URL的404页面的识别,按照经验有如下几种情况
-
直接返回错误页面,请求头中显示404状态码。
-
将错误页面重定向到一个新的页面,重定向方式是上面说的两种,请求头中显示301,302状态码。
-
程序员在后端代码中,将错误页面的状态码设置成200的错误页面,然后直接返回到前端,请求头状态码为200。
-
程序员在后端代码中,将错误页面的请求直接从后端自动重定向到首页,同上。
常见的情况大概这么多,尝试使用python实现对404页面的检测识别,这里还可以分成两类代码,第一类是通用型的,即可以对不同的网址识别404页面,通用性大更加方便,同时难度和容错率也相对提高。第二种则是专门对某个网址进行单独的检测,这种定制化的相对简单,首先分析该网站的返回状态码,返回的错误页面,是否跳转信息,就可以判断是否为404页面。
定制型404页面识别
识别404分通用型与制定型,制定型即对特定的指定的一个网站进行目录扫描,单独写一个程序代码进行识别。这个比较容易,但是这里存在一个问题,即你扫描网站的目录结果还是扫描网站的文件,如果扫描网站的文件,那么适用上面的规则,如果
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 753
753











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











