







1、前提
项目中使用了spring-kafka1.3版本,也用了2.5版本。但是对于offset的提交时机是模糊的,这次通过源码分析和资料进一步明确。
2、认识KafkaConsumer的偏移量
KafkaConsumer是kafka客户端一个入口,通过KafkaConsumer可以拉取kafka服务上的数据、发送心跳包、上报消费分区的偏移量(offset)。
为了保证调用KafkaConsumer.poll()方法时总能返回未被消费者读取过的记录,消费者需要维护每个分区中已读消息对应的偏移量offset,并手机或定时把offset发送给kafka服务端,从而实现消息的不丢失。
对于提交offset主要分2类,一个是自动,一个是手动。通过enable.auto.commit 参数控制。
当=true时,结合auto.commit.interval.ms参数,消费者每次在进行poll 时会检查是否该提交偏移量,并且自动提交最近一次poll 返回的偏移量。
当=false时,需要开发者手动提交offset,见如下代码:
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "10.74.20.54:9092");
properties.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.setProperty("enable.auto.commit", "false"); // 禁止自动提交
properties.setProperty("group.id", "my-group"); //
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(properties);
consumer.subscribe(Collections.singletonList("topic")); // 订阅主题
try {
while (! Thread.currentThread().isInterrupted()) {
ConsumerRecords<String, String> records = consumer.poll(1000);
records.forEach(System.out::println);
consumer.commitAsync(); // 异步提交偏移量
}
} catch (WakeupException ignore) {
// 忽略关闭异常
} finally {
try {
consumer.commitSync(); // 同步提交偏移量
} finally {
consumer.close();
}
}这里又分为异步提交或同步提交:
同步提交:使用 KafkaConsumer.commitSync() 会提交最新偏移量并等待 broker 对提交请求作出回应。 在成功提交或碰到无法恢复的错误之前会不断重试,会导致应用程序一直阻塞,限制了应用程序的吞吐量。
异步提交:使用 KafkaConsumer.commitAsync() 会提交最新偏移量但无需等待 broker 的响应并且不进行重试。 不进行重试,是因为可能有一个更大的偏移量已经提交成功,重试可能会覆盖到最新的值,导致再均衡后出现重复消息。 该方法在 broker 作出响应时会执行用户指定的回调,回调经常被用于记录提交错误或生成度量指标。 不过如果要在其中进行重试,一定要注意提交的顺序。
从性能上考虑:采用上面代码的形式,异步+同步
3、Spring-kafka的实现方式
在spring-kafka 2.3之后enable.auto.commit 默认设置为false(在该版本之前是true),并且AckMode默认为batch。通过该值为false,kafkaConsumer不再自动提交偏移量(offset)了。而是用spring帮我们实现。
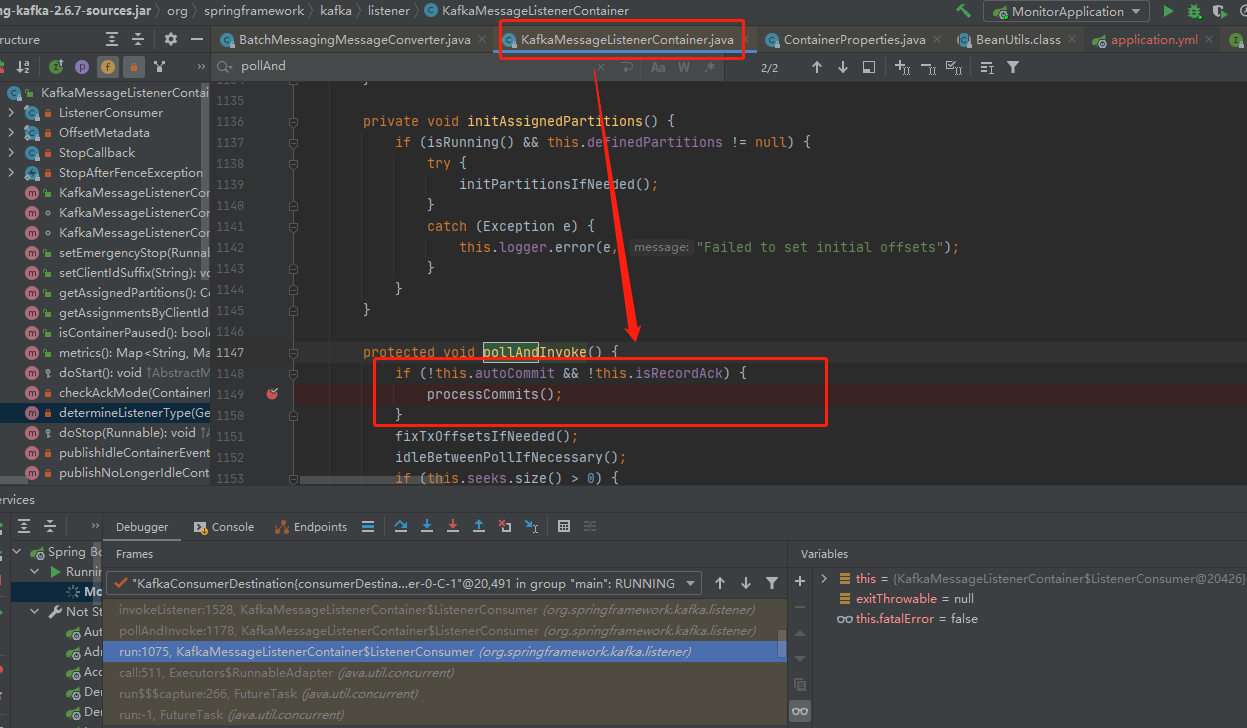
那sping是怎么实现?通过下图,我们可以看到,KafkaMessageListenerContainer.run()内部实现while循环,其内部再调用 pollAndInvoke()完成数据的读取,在pollAndInvoke方法的最上面就是判断是否为手动提交,是就提交上一次读取的offset。














 979
979











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









