







master节点:主要职责是和集群操作相关的内容,如创建或删除索引,跟踪哪些节点是群集的一部分,并决定哪些分片分配给相关的节点。
data节点:这个节点作为一个数据节点,数据节点主要是存储索引数据的节点,主要对文档进行增删改查操作,聚合操作等。数据节点对cpu,内存,io要求较高, 在优化的时候需要监控数据节点的状态,当资源不够的时候,需要在集群中添加新的节点。
协调节点:当node.master和node.data配置都设置为false的时候,该节点只能处理路由请求,处理搜索,分发索引操作等,从本质上来说该节点可以看成是智能负载平衡器。
独立的协调节点在一个比较大的集群中是非常有用的,他负责协调主节点和数据节点;客户端节点加入集群可以得到集群的状态,根据集群的状态可以直接路由请求。
每一个节点都隐式的是一个协调节点,如果同时设置了node.master = false和node.data=false,那么此节点将成为仅协调节点。
另外ES是将数据存储在分片上的,在ES集群中分片主要分为主分片(primary shard)和从分片(deplica shard)。其中主分片主要承担ES集群的写操作,而从分片主要承担集群的读功能。
其中分片与节点的关系是一个节点上可以分布多个分片,这个多个包括1个。所以ES存储的高可用也就是维护了ES节点以及节点上的分片的高可用。
(2)ES集群状态
Elasticsearch的集群监控信息中包含了许多的统计数据,其中最为重要的一项就是集群健康。集群健康存储在status字段中,主要包括green、yellow或者red三种状态。它的三种颜色含义如下:
green:所有的主分片和副本分片都正常运行。
yellow:所有的主分片都正常运行,但不是所有的副本分片都正常运行。
red:有主分片没能正常运行。
master选举
(1)何时选举
集群初始化、集群master崩溃、在Elasticsearch集群中,主节点通过ping命令来检查集群中的其他节点是否处于可用状态,同时非主节点也会通过ping命令来检查主节点是否处于可用状态。在集群中超过n/2 +1 节点没有链接到master选举触发。
(2)选谁:集群中存在多个master节点的候选节点(master-eligible node),这些候选节点中只有一个node可以当选为master节点,如果有多个node当选为master,则集群会出现脑裂,脑裂会破坏数据的一致性,导致集群行为不可控,产生各种非
预期的影响。为了避免产生脑裂,ES采用了常见的分布式系统思路,保证选举出的master被多数派(n/2+1)的node认可,以此来保证只有一个master。
(3)怎么选举?

activeMasters列表:Elasticsearch节点成员首先向集群中的所有成员发送Ping请求,elasticsearch默认等待discovery.zen.ping_timeout时间,然后elasticsearch针对获取的全部response进行过滤,筛选出其中activeMasters列表,activeMaster列表是其它节点认为的当前集群的Master节点。
masterCandidates列表:masterCandidates列表是当前集群有资格成为Master的节点,其中设置node.master:false 表示没有资格成为master节点
从activeMasters中选举mster用的是Bully算法如果activeMaster列表有多个节点具有master资格,那么选择id最小的节点。
masterCandidates选举首先比较节点拥有的集群状态版本编号,然后再比较id,这一流程的目的是让拥有最新集群状态的节点成为master
数据如何复制(主从分片之间)
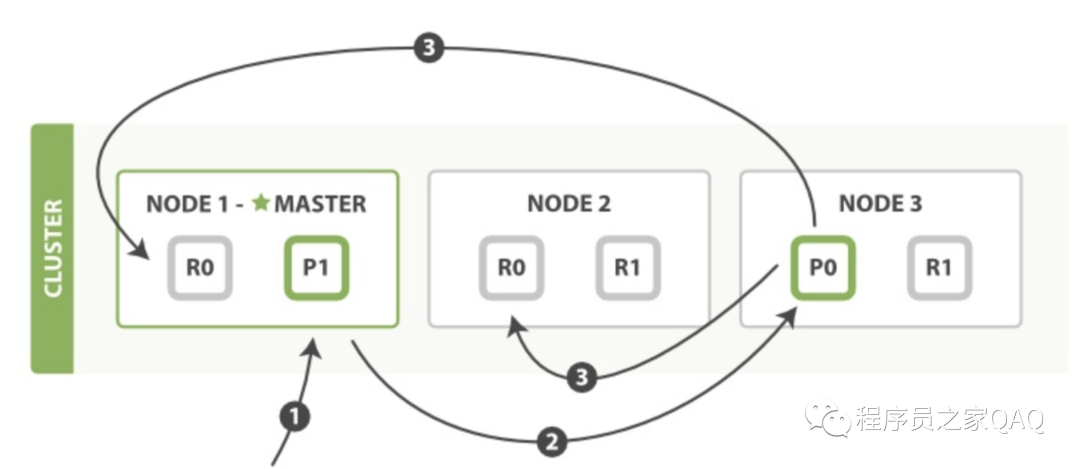
(1)客户端给 Node 1 发送新建、索引或删除请求。
(2)节点使用文档的 _id 确定文档属于分片 0(shard = hash(routing) % number_of_primary_shards)。它转发请求到 Node 3 ,分片 0 位于这个节点上。
(3)Node 3 在主分片上执行请求,如果成功,它转发请求到相应的位于 Node 1 和 Node 2 的复制节点上。当所有的复制节点报告成功, Node 3 报告成功到请求的节点,请求的节点再报告给客户端。
以上是一个写操作的执行过程,ES会等待所有分片写入成功以后再给client返回成功的消息。
所以ES的集群中,一个主分片不能设置太多的从分片,太多的话会影响写入的性能。
注意:在ES写入主分片之前会进行一步检查Active的Shard数,这个检查shard数目与系统setting中index.write.wait_for_active_shards有关。
如果设置了index.write.wait_for_active_shards=1,那么主分片没有故障就可以执行索引操作,如果 index.write.wait_for_active_shards=all,那么必须要所有的分片没有故障才可以进行索引操作。
eg:在一个有1个primary shard 2个replica shard 的集群部署中,index.write.wait_for_active_shards被设置成all,如果此时有一个副本分片产生故障,是无法进行索引操作的,索引操作会在1min 之后提示超时操作。
思考🤔
(1)检查活跃分片数量满足 wait_for_active_shards 设置的值之后,在持续 bulk index 文档过程中有 shard 失效了(这里的shard是replica),能不能继续索引文档了?
(2)在什么时候检查集群中的活跃分片数量?难道要每次client发送索引文档请求时就要检查一次吗?还是说周期性地隔多久检查一次?
(3)这里的 check-then-act 并不是原子操作,因此wait_for_active_shards这个配置参数又有多大的意义?
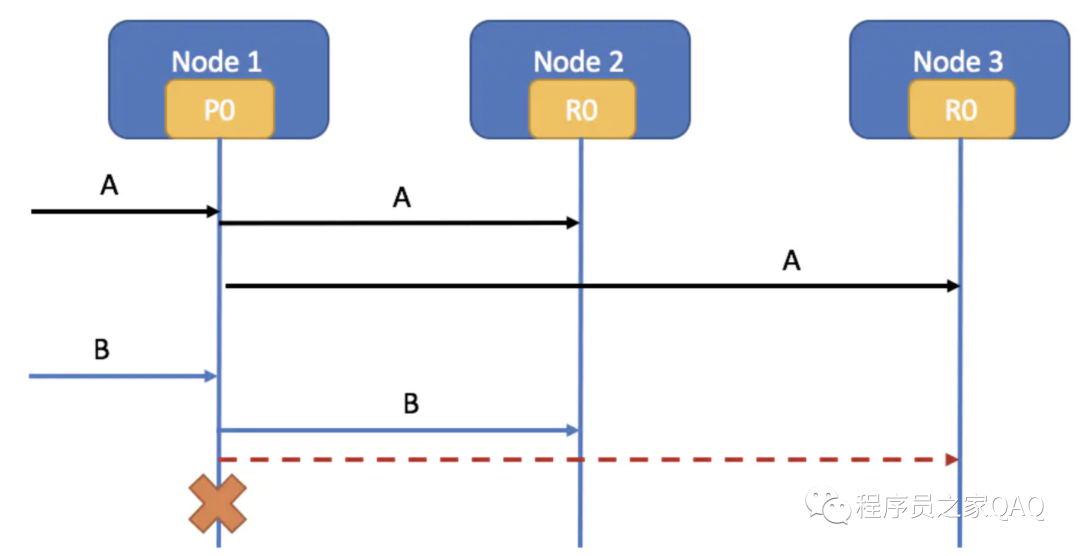
客户端将文档A成功发送到Node1、Node2和Node3三个节点上,接着客户端发送文档B到Node1 并索引文档B,这时Node1 会同步到Node2 和Node3
假设Node1 到Node3 的链路超时了并且这时Node1 挂了。
ES能找出Node2 的R0是包含了最新代码的,ES会把当前状态标成RED,并且会把Node2 的R0晋升到primary,然后会把剩下的一个R0 标记成UNassigned,待Node1 重新加入集群时,会为Node1 分配这个UNassigned的R0。
check 操作发生在 write操作之前,某个doc的写操作check actives shard发现符合要求,但check完之后,某个replica挂了,只要不是primary shard,那该doc的写操作还是会继续进行。但是在返回给用户响应中,会标识出有多少个分片失败了。
实际上,ES索引一篇文档时,是要求primary shard写入该文档,然后primary shard将文件并行转发给所有的replica,当所有的replica都"写入"之后,给primary shard响应,primary shard才返回ACK给client。
从这里可看出,wait_for_active_shards这个参数只是尽可能地保证新文档能够写入到我们所要求的shard数量中,比如:wait_for_active_shards设置为2,那也只是尽可能地保证将新文档写入了2个shard中,当然一个是primary shard,另外一个是某
个replica。(可以理解成索引的一刻有2个分片是可以的,并且成功写入的概率是很高的,不至于出现写的时候发现有一个分片是不可用的)。防止单点故障。
3.如何应对复制延迟(es如何做到近实时搜索)
3.1 基础概念
一个ElasticSearch 索引可由多个 primary shard组成,每个primary shard相当于一个Lucene Index;一个Lucene index 由多个Segment组成,每个Segment是一个倒排索引结构表。
从文档的角度来看:文章会被analyze(比如分词),然后放到倒排索引(posting list)中。倒排索引之于ElasticSearch就相当于B+树之于Mysql,是存储引擎底层的存储结构。
3.2 近实时搜索原理
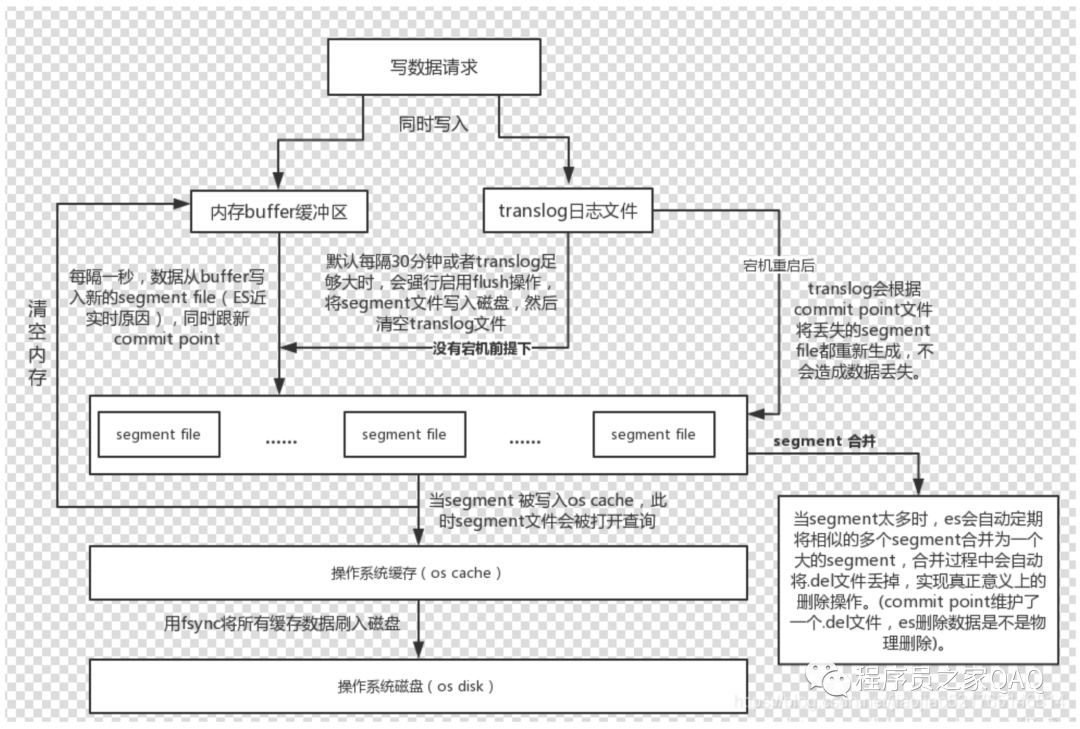
当文档写入ElasticSearch时,文档首先被保存在内存索引缓存中(in-memeory indexing buffer)。而in-memory buffer是每隔1秒钟刷新一次,刷新成一个个的可搜索的段--下图中的绿色圆柱表示(segment),这些segment存储到一个叫file systemcache的缓存中。然后这些段是每隔30分钟同步到磁盘中持久化存储,段同步到磁盘的过程称为提交commit。(这里要注意区分内存中2个不同的区域:一个是 indexing buffer,另一个是file system cache。写入indexing buffer中的文档经过refresh变成 file system cache中的segments,从而搜索可见)。
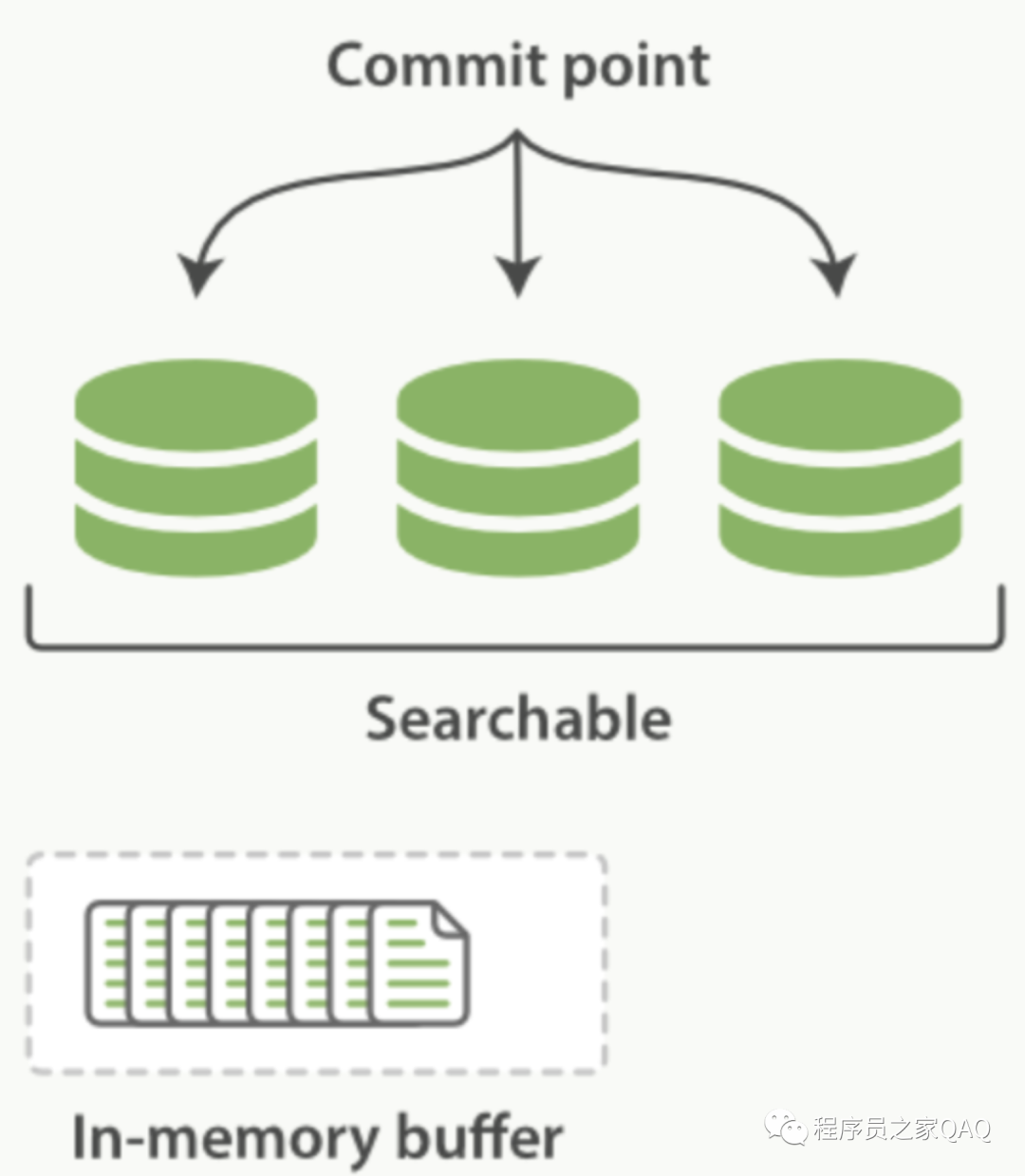
在这里涉及到了两个过程:
① In-memory buffer中的文档被刷新成段;
②段提交同步到磁盘持久化存储。
过程①默认是1秒钟1次,而我们所说的ElasticSearch是提供了近实时搜索,指的是:文档的变化并不是立即对搜索可见,但会在一秒之后变为可见,一秒钟之后,我们写入的文档就可以被搜索到了。另外ElasticSearch提供了
refresh API 来控制过程①。refresh操作强制把In-memory buffer中的内容刷新成段。
比如说,你可以在每次index一篇文档之后就调用一次refresh API,也即:每索引一篇文档就强制刷新生成一个段,这会导致系统中存在大量的小段,由于一次搜索需要查找所有的segments,因此大量的小段会影响搜索性能;此外,大量的小段也意味着OS打开了大量的文件描述符,在一定程度上影响系统资源消耗。这也是为什么ElasticSearch/Lucene提供了段合并操作的原因,因为不管是1s一次refresh,还是每次索引一篇文档时手动执行refresh,都可能导致大量的小段(small segment)产生,大量的小段是会影响性能的。
对于过程②,就是将段刷新到磁盘中去,默认是每隔30分钟一次,这个刷新过程称为提交(commit)。提交成功后,索引的文档就实际的落到了磁盘中。
如果还未来得及提交时,发生了故障,那岂不是会丢失大量的文档数据?这个时候,就引入了translog的概念。
每篇文档写入到In-memroy buffer中时,同时也会向 translog中写一条记录。In-memory buffer 每秒刷新一次,刷新后生成新段,in-memory被清空,文档可以被搜索。但是translog的内容不仍会继续保留。
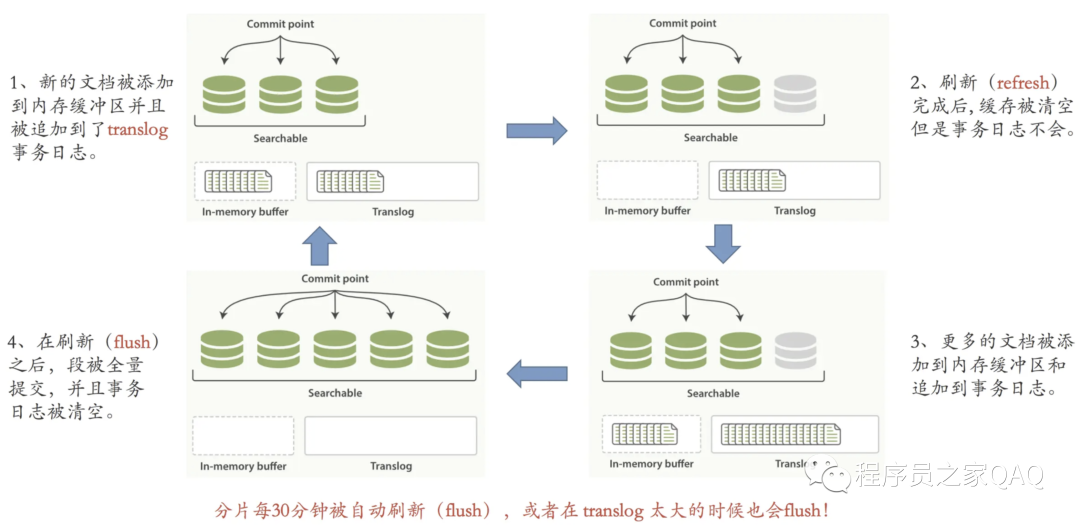
es进行commit操作的时候,会在磁盘中记录一个commit point的概念,是用来表明所有的index segment。假设在上图的流程中,数据保存在file system cache 中发生故障,此时由于没有持久化到磁盘中,但是由于上一次的flush操作会记录一个
commit point 的信息,此时translog会记录上次commit 后的所有写记录,通过存量的快照+ 增量的log 可以实现数据恢复的目标。
3.3分片写入数据架构
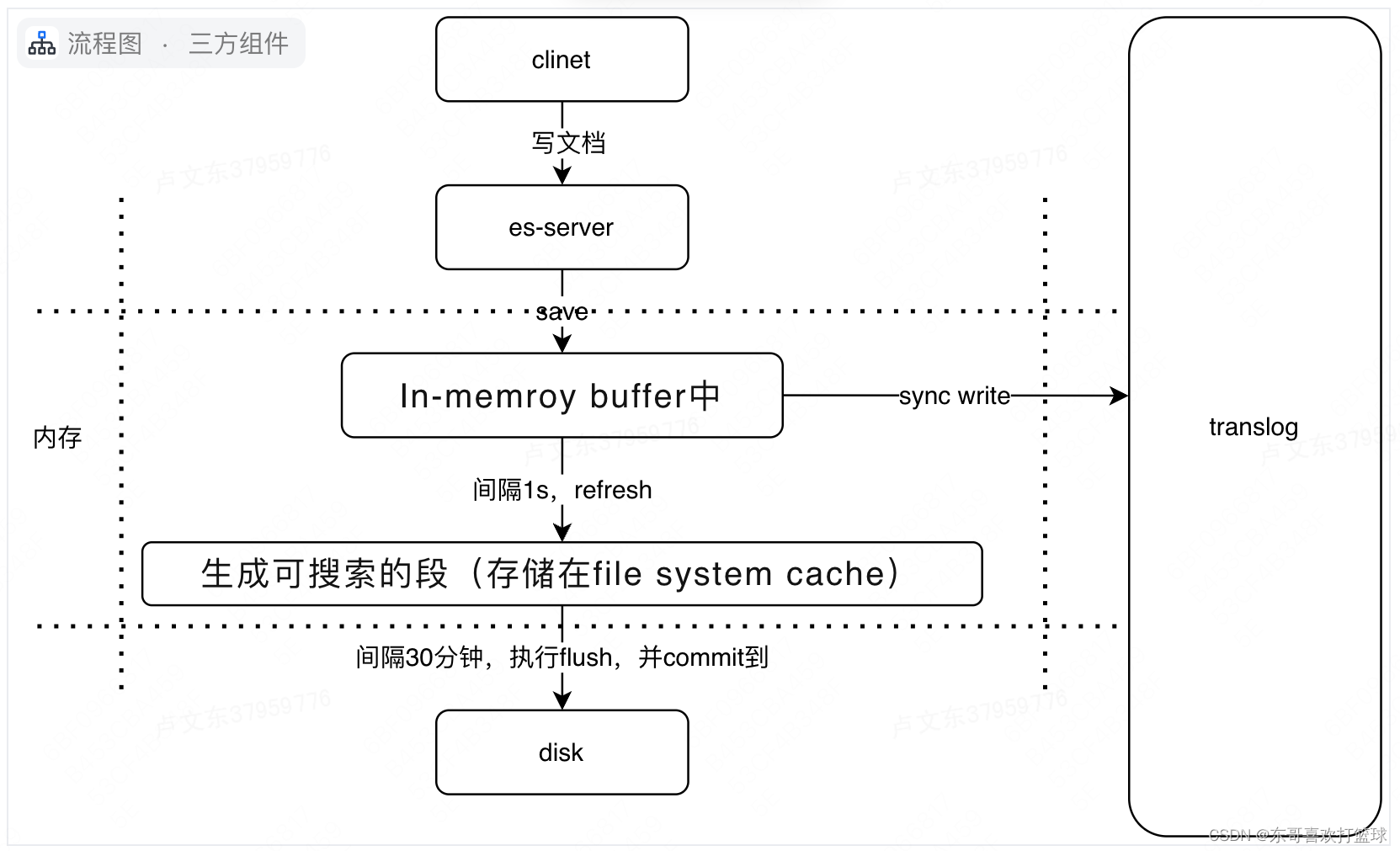
系统宕机后在下一次重启ElasticSearch时,就会读取translog进行恢复。这也是为什么,在我们关闭ElasticSearch时最好进行一次flush操作,将段刷新到磁盘中。因为这样会清空translog,那么在重启ElasticSearch就会很快(不需要恢复大量的translog了)
有个问题是:为什么translog可以在每次请求之后刷新到磁盘?难道不会影响性能吗?相比于将段(segment)刷新到磁盘,刷新translog的代价是要小得多的,因为translog是经过精心设计的数据结构,而段(segment)是用于搜索的"倒排索引",我们无法做到每次将段刷新到磁盘;而刷新translog相比于段要轻量级得多(translog 可做到顺序写disk,并且数据结构比segment要简单),因此通过translog机制来保证数据不丢失又不太影响写入性能。
总结一下:
-
in-memory buffer 刷新生成segment
每秒一次,文档刷新成segment就可以被搜索到了,ElasticSearch提供了refresh API 来控制这个过程。
-
translog 刷新到磁盘
可以动态控制每个索引的translog行为:
index.translog.sync_interval :translog多久被同步到磁盘并提交一次。默认5秒。这个值不能小于100ms
index.translog.durability :是否在每次index,delete,update,bulk请求之后立即同步并提交translog。接受下列参数:
request :(默认)fsync and commit after every request。这就意味着,如果发生崩溃,那么所有只要是已经确认的写操作都已经被提交到磁盘。
async :在后台每sync_interval时间进行一次fsync和commit。意味着如果发生崩溃,那么所有在上一次自动提交以后的已确认的写操作将会丢失。
index.translog.flush_threshold_size :当操作达到多大时执行刷新,默认512mb。也就是说,操作在translog中不断累积,当达到这个阈值时,将会触发刷新操作。
index.translog.retention.age :translog最长多久提交一次。默认12h。
-
段(segment) 刷新到磁盘(flush)
每30分钟一次,ElasticSearch提供了flush API来控制这个过程。在段被刷新到磁盘(就是通常所说的commit操作)中时,也会清空刷新translog。如果服务发生故障,重启以后可以根据commit point和日志进行数据恢复
4.容灾扩容处理
4.1 单机房容错机制
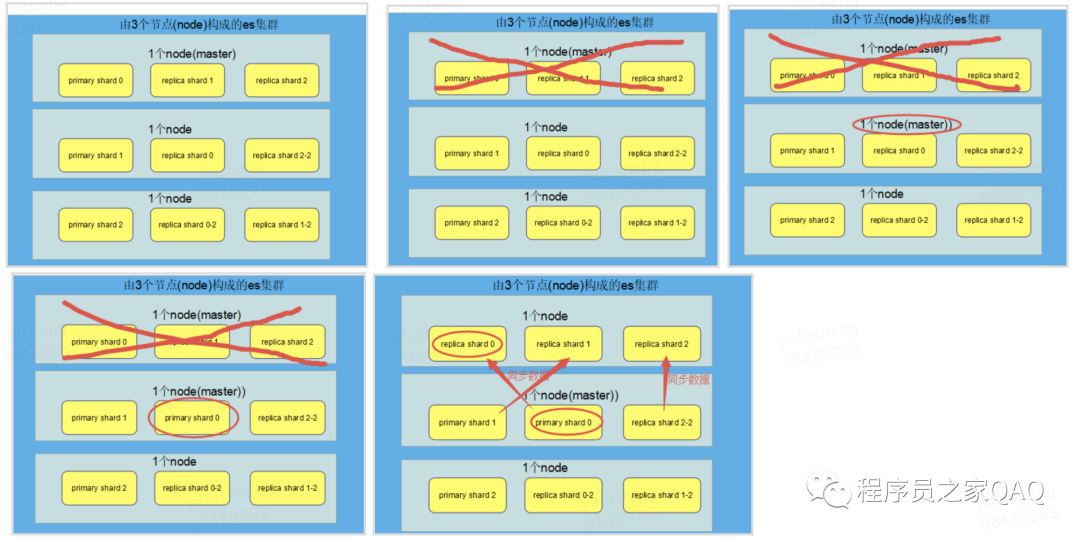
节点master挂掉以后集群的状态变成red。
主节点挂掉 前文有描述如何用候补节点做选举选出新的master节点。
master节点确定好以后选择丢失的primary分片对应的replica shard晋升为primary.此时集群的状态由red变成yellow.
故障恢复重启node1,新的master节点将缺失的副本都copy到故障恢复的node上,并且同步故障期间的增量数据。此时es的集群状态恢复成green。
4.2 多机房容错机制
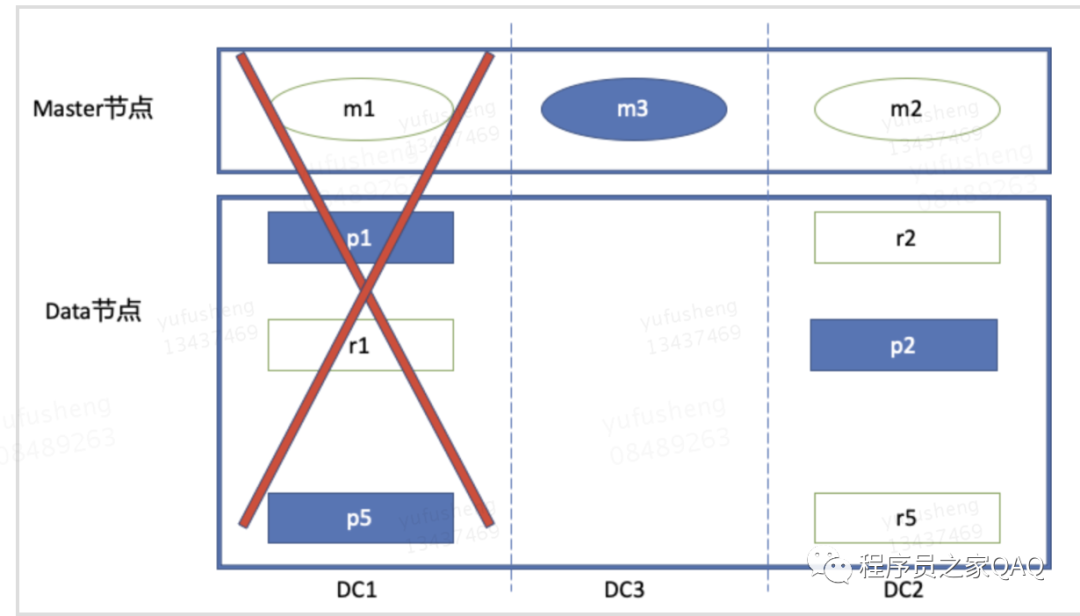
(1)多机房部署结构
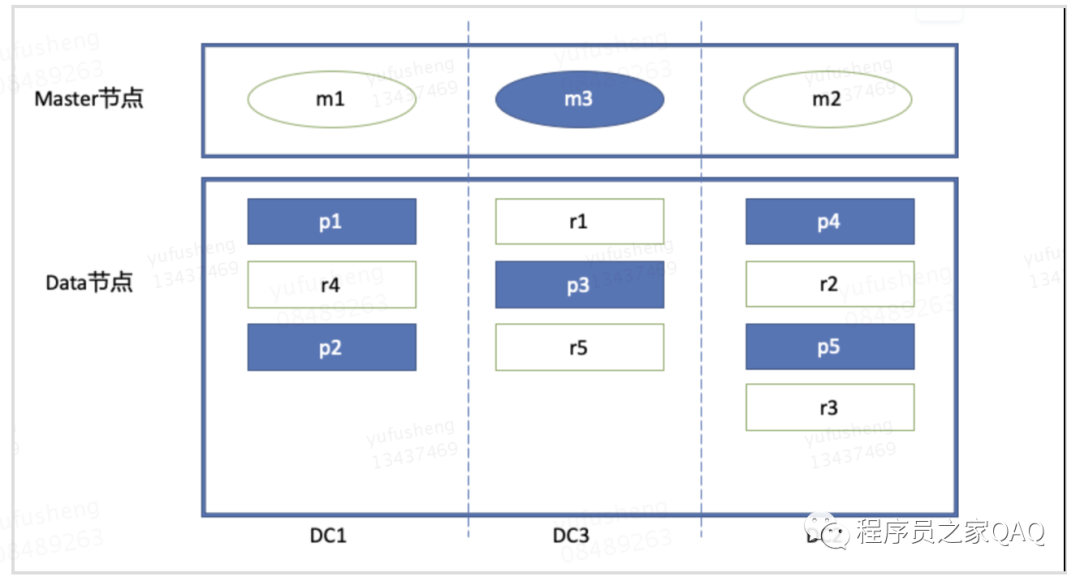
如果DC1、DC2、DC3任何一个机房发生故障,都会有相应的存活的master节点接替,同时data节点也会有对应的deplica 转化成 primary shard来保证服务的写功能。
虽然多机房部署,但是分片的部署节点也不能随便部署,如果按照如下图进行部署,如果DC1机房发生故障,则整个集群是无法对外提供写服务,集群的健康情况就会变成red。
单机房部署虽然没有机房容灾,但没有跨机房数据传输,读写延迟可以做到最低,数据传输效率最高!但如果一个机房挂掉,整个es集群数据就不可用了,因此存在较大容灾隐患;
但多机房部署也存在明显弊端,多机房部署不可避免会造成跨机房数据传输,无形增加了数据传输延时,一定程度上又降低了集群读写性能。
4.3 扩容问题
由于当初对于业务的预计不够充分,导致服务的读写遇到性能瓶颈,这就需要对ES集群进行扩容处理,传统的扩容方式主要有2种:垂直扩容和水平扩容。
(1)垂直扩容
例如当前的服务器能够容纳1T的数量,现在数据量达到了10T,直接购买一台10T的服务器进行替换。
(2)水平扩容
增加多台拥有类似性能的服务器构成集群。
ES一般采用水平扩容的方式进行扩容。从成本上来说,内存容量小,并且性能相对较低的服务器相比较与内存容量大,性能好的服务器,在价格上的差距不是一个量级的。
从另一方面来说,ES是一套分布式的系统,分布式的存在也是为存放大量的数据。讲到elasticSearch的扩容,自然就会想到shard和replica shard。
elasticSearch拥有cluster discovery(集群发现机制),当我们启动一个新的节点,该节点会发现集群并且自动加入到集群中。并且es集群会自动进行各个shard之间的数据均衡处理。
并且当节点减少时,es集群也会自动将减少的节点中的数据移到其他正在运行的节点中。所以ES一般选择水平扩容的方式。
举一个🌰
一个索引有6个shard,其中3 primary shard,3replica shard。此集群的配置的最大极限是6台node ,每个node有更少的shard。IO/CPU/Memory资源给每个shard分配更多, 每个shard性能更好。
此时平均1个node节点上平均分布了1个shard,写性能已经达到单机的最佳状态。但是如果是一个读多的服务的话,仍然可以继续扩容到9台node,即3 primary shard,6replica shard。此时读操作的吞吐量会比3台node 的性能高2倍左右(理论上)。
参考文献:















 193
193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









