









目录
3台4核32G机器
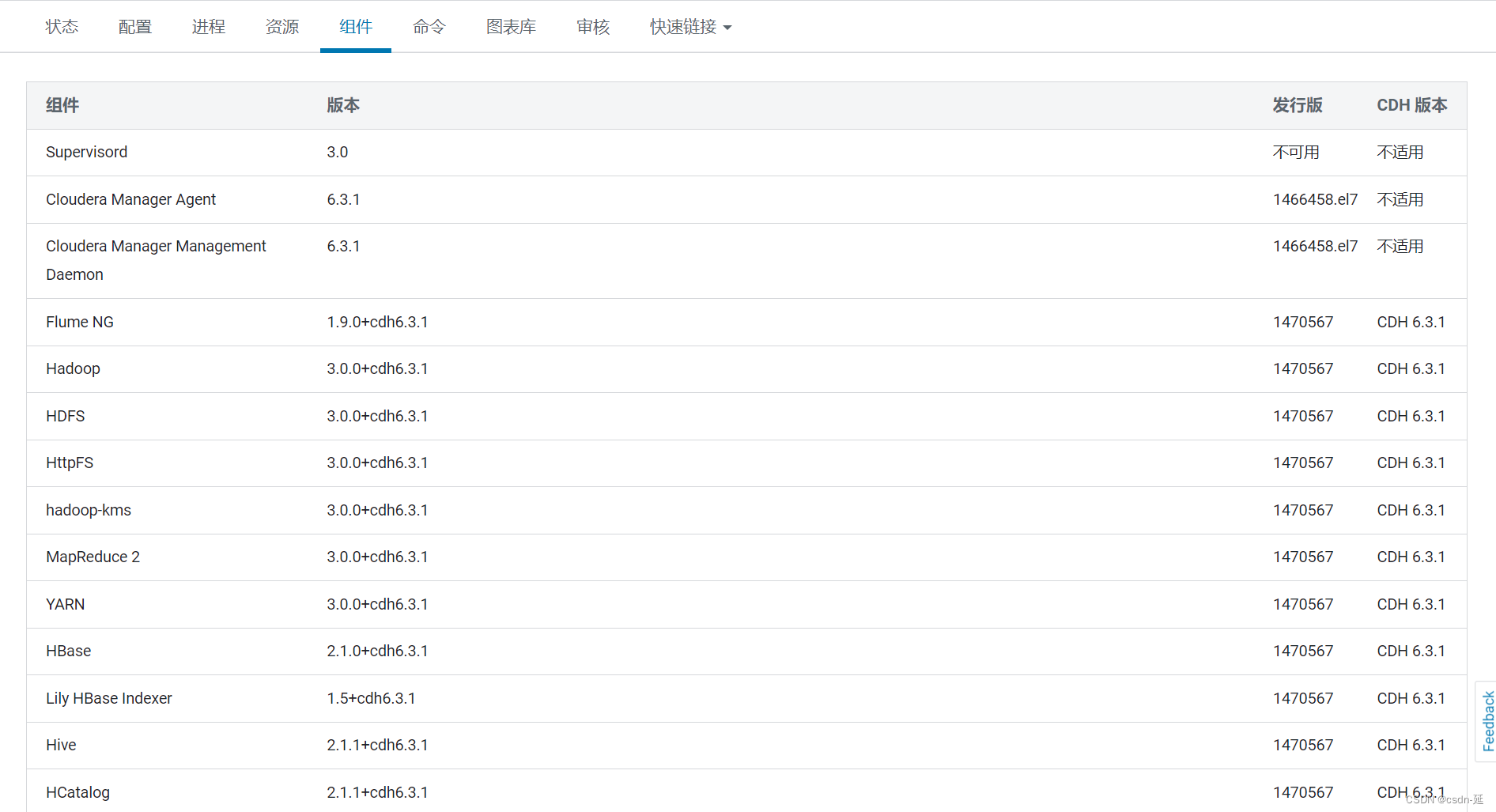
技术组件


Flume

代理名称 agent1
配置文件
# 设置代理命令
agent1.sources = r1
agent1.sinks = k1
agent1.channels = c1
# 设置数据源
agent1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
agent1.sources.r1.batchSize = 1000
agent1.sources.r1.batchDurationMillis = 1000
agent1.sources.r1.kafka.bootstrap.servers = xx.xx.xx.xx:9092,xx.xx.xx.xx:9092,xx.xx.xx.xx:9092
agent1.sources.r1.kafka.consumer.group.id = sync-bigdata
agent1.sources.r1.kafka.topics.regex = ^[a-zA-Z0-9\\-]+-sync-bigdata$
agent1.sources.r1.kafka.consumer.request.timeout.ms = 80000
agent1.sources.r1.kafka.consumer.fetch.max.wait.ms=7000
agent1.sources.r1.kafka.consumer.session.timeout.ms = 70000
agent1.sources.r1.kafka.consumer.heartbeat.interval.ms = 60000
agent1.sources.r1.kafka.consumer.enable.auto.commit = false
# 设置拦截器
agent1.sources.r1.interceptors= i1
agent1.sources.r1.interceptors.i1.type=com.cn.bigdata.flume.FlumeInterceptor$Builder
# 设置通道类型及缓存设置
agent1.channels.c1.type = org.apache.flume.channel.kafka.KafkaChannel
agent1.channels.c1.kafka.bootstrap.servers = xx.xx.xx.xx:9092,xx.xx.xx.xx:9092,xx.xx.xx.xx:9092
agent1.channels.c1.kafka.topic = kafka-channel-hdfs
agent1.channels.c1.kafka.consumer.group.id = kafka-channel
agent1.channels.c1.kafka.consumer.request.timeout.ms = 80000
agent1.channels.c1.kafka.consumer.fetch.max.wait.ms=7000
agent1.channels.c1.kafka.consumer.session.timeout.ms = 70000
agent1.channels.c1.kafka.consumer.heartbeat.interval.ms = 60000
agent1.channels.c1.kafka.consumer.enable.auto.commit = false
# 设置sink目的地
agent1.sinks.k1.type = hdfs
agent1.sinks.k1.hdfs.path = hdfs://cdh-xxx-xxx-hue/user/hive/warehouse/ods_tmp_t.db/o_flume_kafka_data_origin/dt=%{eventDate}
agent1.sinks.k1.hdfs.filePrefix = log_%Y%m%d_%H
agent1.sinks.k1.hdfs.fileType=DataStream
agent1.sinks.k1.hdfs.rollCount = 0
agent1.sinks.k1.hdfs.rollSize = 134217728
agent1.sinks.k1.hdfs.rollInterval = 600
agent1.sinks.k1.hdfs.batchSize = 100
agent1.sinks.k1.hdfs.threadsPoolSize = 10
agent1.sinks.k1.hdfs.idleTimeout = 0
agent1.sinks.k1.hdfs.minBlockReplicas = 1
agent1.sinks.k1.hdfs.useLocalTimeStamp = true
agent1.sinks.k1.hdfs.timeZone = Asia/Shanghai
# 将数据源和目的地绑定到通道上
agent1.sources.r1.channels = c1
agent1.sinks.k1.channel = c1Hive
Hive 辅助 JAR 目录
/etc/hive/auxlibhive-site.xml 的 Hive 服务高级配置代码段(安全阀)
<property>
<name>hive.spark.client.future.timeout</name>
<value>1800</value>
<description>Timeout for requests from Hive client to remote Spark driver.</description>
</property>
<property>
<name>hive.spark.client.connect.timeout</name>
<value>30000</value>
<description>Timeout for remote Spark driver in connecting back to Hive client.</description>
</property>
<property>
<name>hive.spark.client.server.connect.timeout</name>
<value>300000</value>
</property>
<property>
<name>hive.txn.manager</name>
<value>org.apache.hadoop.hive.ql.lockmgr.DbTxnManager</value>
</property>
<property>
<name>hive.compactor.initiator.on</name>
<value>true</value>
</property>
<property>
<name>hive.compactor.worker.threads</name>
<value>1</value>
</property>
<property>
<name>hive.support.concurrency</name>
<value>true</value>
</property>
<property>
<name>hive.enforce.bucketing</name>
<value>true</value>
</property>
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
<description>支持动态分区</description>
</property>
<property>
<name>hive.exec.dynamic.partition</name>
<value>true</value>
</property>
<property>
<name>hive.warehouse.subdir.inherit.perms</name>
<value>false</value>
</property>
<property>
<name>hive.exec.stagingdir</name>
<value>/tmp/hive/.hive-staging</value>
</property>
<property>
<name>HIVE_AUXLIB_JARS_PATH</name>
<value>/etc/hive/auxlib</value>
<description>hive辅助jar包存放目录</description>
</property>默认:

实际:


元数据字符集设置
①. 进入mysql ,查看hive 数据库当前编码
show create database hive ;② 如果是utf8 则执行下面sql将 hive 数据库默认编码改成 latin1
alter database hive default character set latin1 ;③ 执行下面sql ,修改 表/字段/分区/索引 等部分的注释字符集
use hive;
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;UDF及扩展

- 将这3个包放入到对应hdfs目录下
- 将json-serde包放入到服务器目录/etc/hive/auxlib/
- create function json_array as 'com.cn.bigdata.hive.func.JsonArray' using jar "hdfs:///tmp/udf/lib/json-array-1.0-SNAPSHOT.jar";
- 将flume-interceptor包放入到服务器目录/opt/cloudera/parcels/CDH/lib/flume-ng/lib
- 重启hive、flume
Hue


Sentry





Spark

Yarn



其他
所有日志相关目录,前面均价上/data (原 /var/log/flume-ng)
















 1868
1868











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









