









Netty处理器重要概念:
* 1.Netty处理器可以分为两类,入站处理器和出站处理器,
* 2.入站处理器的顶层是ChannelInboundHandler,出站处理器的顶层是ChannelOutboundHandler
* 3.数据处理时常用的各种解码器本质上都是处理器
* 4.编码:本质是一种出站处理器,因此编码一定是一种ChannelOutboundHandler
* 5.解码:本质是一种入站处理器,因此解码一定是一种ChannelInboundHandler
* 6.在Netty中,编码器通常以XXXEncoder命名,解码器通常以XXXDecoder命名
* 7.前一个处理器的出来的数据要和后一个处理器入参相匹配,否则就会有问题
* 8.TCP粘包和拆包会对消息的处理产生问题 Netty提供了Frame Dectection系列的一些双处理器解码器通常要继承ByteToMessageDecoder
而编码器通常要继承MessageToByteEncoder
下面自己写一个编码器和一个解码器
public class MyByteToLongDecoder extends ByteToMessageDecoder {
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
System.out.println("decode invoked");
System.out.println(in.readableBytes());
if(in.readableBytes()>=8){
out.add(in.readLong());
}
}
}
public class MyByteToLongDecoder extends ByteToMessageDecoder {
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
System.out.println("decode invoked");
System.out.println(in.readableBytes());
if(in.readableBytes()>=8){ 这里要特别注意,由于TCP粘包拆包的问题,这里一定要加这个判断,否则会接收不到数据,关于粘包拆包问题,我会在下一篇中说明。
out.add(in.readLong());
}
}
}
再贴上一段客户端的自定义handler
public class MyClientHandler extends SimpleChannelInboundHandler<Long> {
@Override
protected void channelRead0(ChannelHandlerContext ctx, Long msg) throws Exception {
System.out.println(ctx.channel().remoteAddress());
System.out.println("client output "+msg);
}
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
ctx.writeAndFlush(123456L);//一定要加L,否则会作为int类型处理,最终导致消息发送不出去。】、
如果改成ctx.writeAndFlush(Unpooled.copiedBuffer("helloworld", Charset.forName("utf-8")));
那么服务端的console上接收到的是一串Long型的数字,而不是字符串
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {
super.exceptionCaught(ctx, cause);
ctx.close();
}
}
其他组件详细贴上了。
关于netty编解码器的重要结论:
1、无论是编码器还是解码器,其接受的消息类型必须要与待处理的参数类型一致,否则该编码器或解码器并不会执行。
2、在解码器进行数据解码时,一定要记得判断缓冲(ByteBuf)中的数据是否 足够,否则将会产生一些问题。
例如上边的例子判断是否是8个长度(因为long是占用8个字节的数据类型):
-------------------------------------------------------
在netty中有一个非常重要的decoder ReplayingDecoder
如果一个解码器继承了ReplayingDecoder,就没有 if(in.readableBytes()>=8)这样的判断了,如下:
public class MyReplayingDecoder extends ReplayingDecoder<Void> {
@Override
protected void decode(ChannelHandlerContext ctx, ByteBuf in, List<Object> out) throws Exception {
System.out.println("MyReplayingDecoder decode invoked!");
out.add(in.readLong());//注意没有判断字节数!!!!
}
}
这样写是正确的,因为ReplayingDecoder帮我们做了好多事情。
ReplayingDecoder是
一个特殊的ByteToMessageDecoder ,可以在阻塞的i/o模式下实现非阻塞的解码。
ReplayingDecoder 和ByteToMessageDecoder 最大的不同就是ReplayingDecoder 允许你实现decode()和decodeLast()就像所有的字节已经接收到一样,不需要判断可用的字节,举例,下面的ByteToMessageDecoder 实现:
public class IntegerHeaderFrameDecoder extends ByteToMessageDecoder {
@Override
protected void decode(ChannelHandlerContext ctx,
ByteBuf buf, List<Object> out) throws Exception {
if (buf.readableBytes() < 4) {
return;
}
buf.markReaderIndex();
int length = buf.readInt();
if (buf.readableBytes() < length) {
buf.resetReaderIndex();
return;
}
out.add(buf.readBytes(length));
}
}
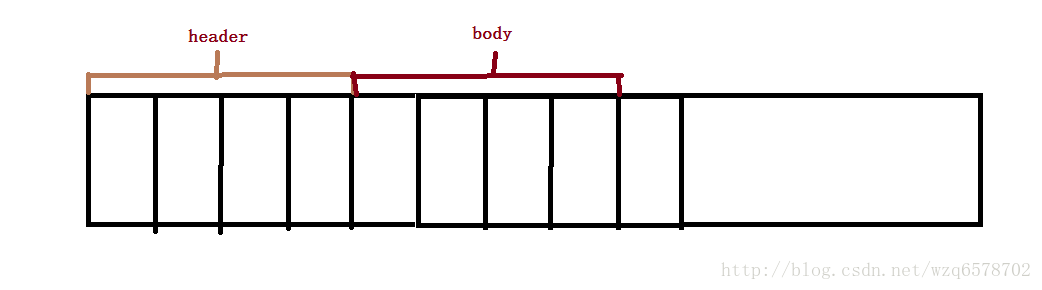
这段代码表达的意思是先读取前边4隔壁字节(即,一个int类型),然后再去读取后边个字节,如果前边四个字节无法读取,直接返回,如果可以读取前四个字节,那么紧接着读取同样长度个字节,这种方式是一种消息头,消息体的协议模型,先读取消息头,之后再去读取消息体:
如果用 ReplayingDecoder来简化:
public class IntegerHeaderFrameDecoder
extends ReplayingDecoder<Void> {
protected void decode(ChannelHandlerContext ctx,
ByteBuf buf) throws Exception {
out.add(buf.readBytes(buf.readInt()));
}
}
具体原理:
当ReplayingDecoder 接收的buffer的数据不足时,会抛出一个异常,ReplayingDecoder 通过一个ByteBuf 的具体实现来完成。在上边的IntegerHeaderFrameDecoder ,当你调用buf.readInt().你就假设在buffer里边有4个字节,如果里边确实有4个字节,它将会返回一个整型的头,就像你期望的一样,否则,将会抛出一个Error并且控制会返回到ReplayingDecoder,如果ReplayingDecoder扑捉到这个错误,然后他就会将读的索引重置到刚开始的位置(buffer的开始位置),之后再次调用decode方法当数据继续进入buffer的时候。
请注意ReplayingDecoder 总是返回一个缓冲的Error 的实例,,来避免创建新的Error对象和每次填充堆栈的负担。
简化使用带来的成本,ReplayingDecoder 强制带来了2个限制:
一些buffer 的操作是被禁止的
如果网络过慢并且消息的格式复杂不像上边提到的那种简单的例子,会导致性能下降。在这种情况下,你的解码器就会一遍又一遍解码一个消息的同一个部分。
你必须要记住decode方法为了解码一个消息可能别调用多次,下面的情况是不能工作的。
public class MyDecoder extends ReplayingDecoder<Void> {
private final Queue<Integer> values = new LinkedList<Integer>();
@Override
public void decode(.., ByteBuf buf, List<Object> out) throws Exception {
// A message contains 2 integers.
values.offer(buf.readInt());
values.offer(buf.readInt());
// This assertion will fail intermittently since values.offer()
// can be called more than two times!
assert values.size() == 2;
out.add(values.poll() + values.poll());
}
}
上边的方式当中,假如走到第二个values.offer(buf.readInt());时候抛出了异常,下边的逻辑就不会走,但是values 里边已经有一个消息了,当下次再调用decode方法的时候(加入过来了2条数据),那么assert values.size() == 2;永远都不会通过,因为加上之前的一条现在values里边是三条数据。
The correct implementation looks like the following, and you can also utilize the ‘checkpoint’ feature which is explained in detail in the next section.
正确的实现应该是下边这样的方式
public class MyDecoder extends ReplayingDecoder<Void> {
private final Queue<Integer> values = new LinkedList<Integer>();
@Override
public void decode(.., ByteBuf buf, List<Object> out) throws Exception {
// Revert the state of the variable that might have been changed
// since the last partial decode.
values.clear();//首先要清理掉里边的消息
// A message contains 2 integers.
values.offer(buf.readInt());
values.offer(buf.readInt());
// Now we know this assertion will never fail.
assert values.size() == 2;
out.add(values.poll() + values.poll());
}
}
幸好,复杂解码器性能的提升可以通过checkpoint()方法实现,checkpoint()方法可以更新buffer的初始化的位置,这样ReplayingDecoder 就可以在调用checkpoint()方法的时候重新回到上一次读索引的位置。
通过枚举调用索引,尽管你可以自己使用checkpoint()方法来管理decoder的状态,最易用的方式就是使用枚举来管理decoder的状态,这个枚举代表了当前decoder的状态,当状态改变时可以调用checkpoint()方法,你可以有很多状态取决于你想解码的消息的复杂度。
实际上checkpoint就是一种存档机制,可以跳过不需要的部分进行重试。下面有一个例子
public enum MyDecoderState {
//假设消息有2种状态,读取长度状态和读取内容的状态。
READ_LENGTH,
READ_CONTENT;
}
public class IntegerHeaderFrameDecoder
extends ReplayingDecoder<MyDecoderState> {
private int length;
public IntegerHeaderFrameDecoder() {
// Set the initial state.
super(MyDecoderState.READ_LENGTH);
}
@Override
protected void decode(ChannelHandlerContext ctx,
ByteBuf buf, List<Object> out) throws Exception {
switch (state()) {
case READ_LENGTH:
length = buf.readInt();
checkpoint(MyDecoderState.READ_CONTENT);
//注意这里没有break,也就是说接下来就是进入READ_CONTENT的代码块,执行读取内容的逻辑
case READ_CONTENT:
ByteBuf frame = buf.readBytes(length);
checkpoint(MyDecoderState.READ_LENGTH);
out.add(frame);
break;
default:
throw new Error("Shouldn't reach here.");
}
}
}















 2517
2517











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









