







第一章、lora论文解析
参考论文: low rank adaption of llm
背景介绍:
部署完整独立的微调模型实例每次都将花费高昂的代价。所以我们提出了低秩自适应的方法,即LoRA。它冻结了预训练模型的权重值,并给Transformer架构的每一层都注入了可训练的秩分解矩阵,从而极大的减少了下游任务需要训练的参数数量。虽然使用了更少的训练参数,提供了更高的训练吞吐量。
Pytorch架构集成了LoRA模型并提供了我们针对RoBERTa, DeBERTa, and GPT-2的应用集成和相关模型,链接为 https://github.com/microsoft/LoRA。
很多时候人们通过只调整部分参数,或者给新任务添加外部模块的方式来解决这个问题。这样,在每个任务中,除预训练模型外,我们只需要额外存储和加载少量特定任务所需的参数即可,从而极大地提高了部署时的操作效率。但是现有技术在扩展模型深度或减少模型可用序列长度(Li et al. (2018a))时,通常会引入推理时延。更重要的是,这些方法往往无法与微调基线相匹配,从而在效率和模型质量之间产生权衡。
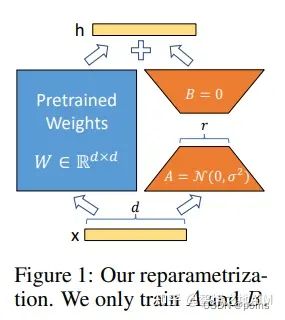
图1
我们受到Li et al. (2018a); Aghajanyan et al. (2020)等工作的启发,他们发现学习到的过参数化模型实际上存在于一个低内在维度上。我们假设模型自适应过程中权重的变化也具有较低的“内在秩”,这帮助我们提出的低秩自适应(LoRA)方法。LoRA允许我们在适配过程中,通过优化密集层变化的秩分解矩阵的方式来间接的训练神经网络的密集层,同时保持预训练权重不变。如图1所示。以GPT-3 175B 模型为例,我们发现即便全秩达到了12288,一个非常低的秩(图1中r为1或者2)也足够了。这使得LoRA在存储和计算方面都很高效。
LoRA具备以下几个关键优势:
- 一个预训练模型可以用来针对不同任务建立为很多小的LoRA模块。我们可以冻结共享模型,仅仅通过更换图1中的A,B矩阵来快速地切换任务,从而显著降低存储需求和任务切换开销。
- 当使用自适应优化器时,LoRA使训练更加高效,并将硬件门槛降低了3倍,因为对于大多数参数,我们不需要计算梯度或维护的优化器状态。相反,我们只优化注入的、小得多的低秩矩阵。
- 在构造上,我们简单的线性设计允许我们在部署时将可训练矩阵与冻结的权重合并,同时保证了相较于全微调模型的性能并不产生推理时延。
- LoRA与许多现有方法不冲突,并且可以与其中许多方法相结合,比如前缀调整法。我们在附录E中提供了一个这样的例子。
第二章、LORA大模型微调算法原理解析代码实现
import math
class LoRALayer(torch.nn.Module):
def __init__(self, in_dim, out_dim, rank, alpha):
super().__init__()
self.A = torch.nn.Parameter(torch.empty(in_dim, rank))
torch.nn.init.kaiming_uniform_(self.A, a=math.sqrt(5)) # similar to standard weight initialization
self.B = torch.nn.Parameter(torch.zeros(rank, out_dim))
self.alpha = alpha
def forward(self, x):
x = self.alpha * (x @ self.A @ self.B)
return x- 在上述代码中,rank 是一个超参数,它控制着矩阵的内部维度,
- 换句话说,这个参数控制了 LoRA 引入的额外参数的数量,是决定模型适应性和参数效率之间平衡的关键因素。
- 第二个超参数,alpha,是应用于低秩适应输出的缩放超参数。
- 它基本上控制了适应层的输出能够影响被适应层原始输出的程度。
- 这可以被视为一种调节低秩适应对层输出影响的方式。
- 到目前为止,我们实现的 LoRALayer 类允许我们转换输入层。
- 然而,在 LoRA 中,我们通常感兴趣的是替换现有的 Linear 层,以便将权重更新应用于现有的预训练权重,
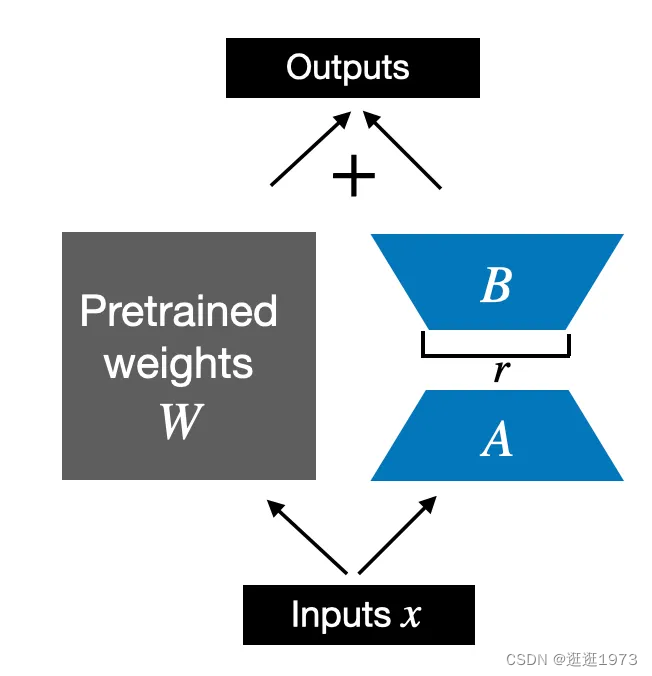
为了将原始的 Linear 层权重纳入其中,如上图所示,我们下面实现了一个 LinearWithLoRA 层,该层使用了之前实现的 LoRALayer,并且可以用来替换神经网络中现有的 Linear 层,例如,LLM 中的自注意力模块或前馈模块。
class LinearWithLoRA(torch.nn.Module):
def __init__(self, linear, rank, alpha):
super().__init__()
self.linear = linear
self.lora = LoRALayer(
linear.in_features, linear.out_features, rank, alpha
)
def forward(self, x):
return self.linear(x) + self.lora(x)- 请注意,由于我们在 LoRA 层中用零值初始化了权重矩阵(LoRALayer 中的 self.B),因此和之间的矩阵乘法结果是一个由 0 组成的矩阵,并且不会影响原始权重(因为将 0 添加到原始权重中不会修改它们)。
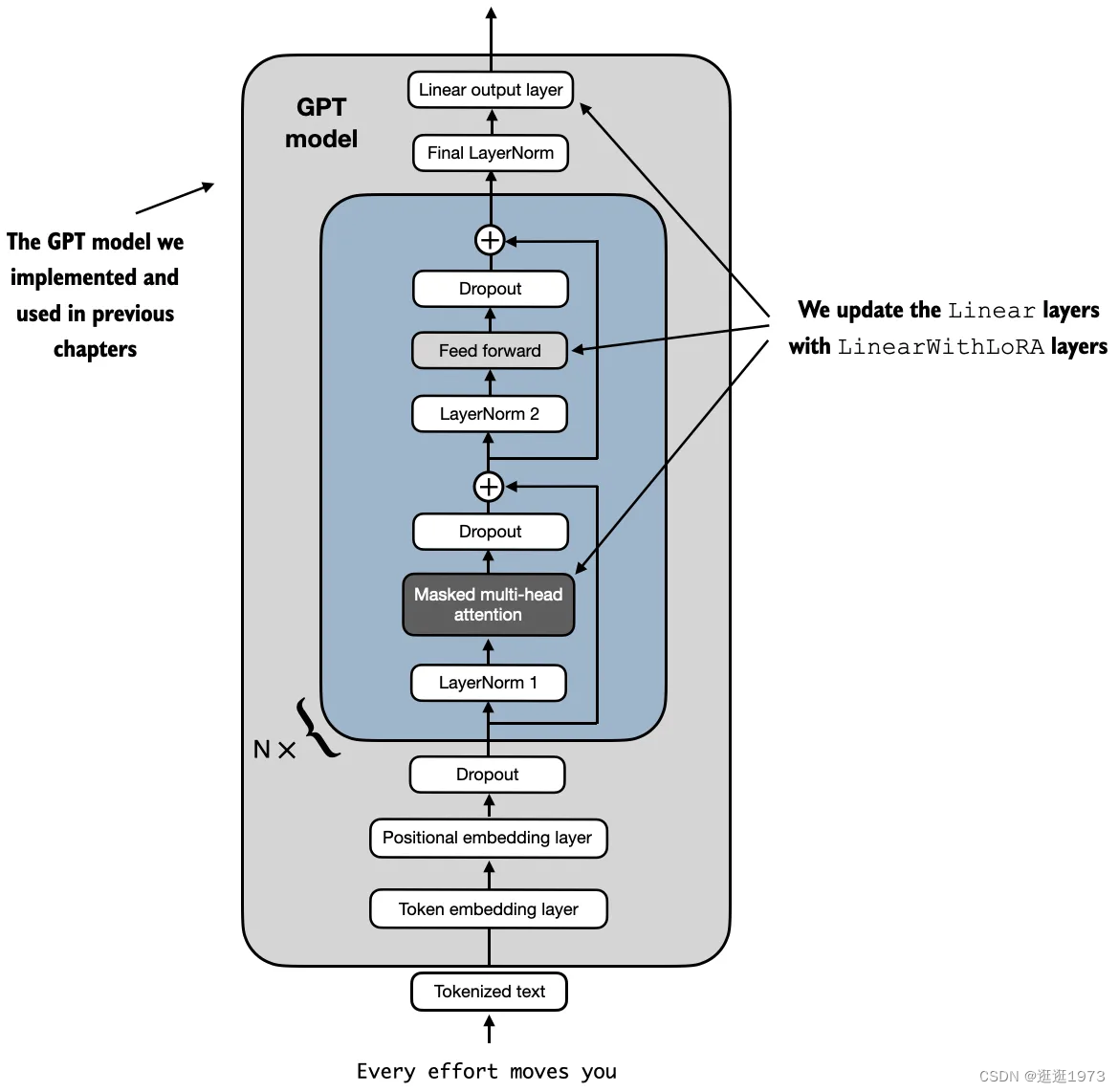
- 为了尝试在之前定义的 GPT 模型上应用 LoRA,我们定义了一个 replace_linear_with_lora 函数,用以替换模型中所有的 Linear 层为新的 LinearWithLoRA 层。
def replace_linear_with_lora(model, rank, alpha):
for name, module in model.named_children():
if isinstance(module, torch.nn.Linear):
# Replace the Linear layer with LinearWithLoRA
setattr(model, name, LinearWithLoRA(module, rank, alpha))
else:
# Recursively apply the same function to child modules
replace_linear_with_lora(module, rank, alpha)- 其目的是遍历一个神经网络模型的所有子模块,并替换其中的
torch.nn.Linear层为自定义的LinearWithLoRA层 rank:LoRA中使用的低秩矩阵的秩。alpha:LoRA中的缩放超参数,用于控制低秩适应输出对原始输出的影响。-
使用
named_children()方法遍历模型的所有直接子模块,并获取它们的名称和引用。 -
setattr 函数的作用:
setattr函数的作用是将model对象的属性(由name指定的名称)设置为新的LinearWithLoRA实例。这意味着,如果name是'layer1',那么model.layer1将被替换为新的LinearWithLoRA层。 -
递归调用确保了即使模型具有复杂的嵌套结构,所有
nn.Linear层也能被替换。替换完成后,
original_model的linear1和linear2属性已经被LinearWithLoRA实例所替代,而这些实例包含了原始线性层的权重和任何 LoRA 技术所添加的新权重。
然后我们冻结原始模型参数,并使用replace_linear_with_lora来替换上述Linear层,使用以下代码:这将把LLM中的Linear层替换为LinearWithLoRA层。
total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"Total trainable parameters before: {total_params:,}")
for param in model.parameters():
param.requires_grad = False
total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"Total trainable parameters after: {total_params:,}")Total trainable parameters before: 124,441,346 Total trainable parameters after: 0
replace_linear_with_lora(model, rank=16, alpha=16)
total_params = sum(p.numel() for p in model.parameters() if p.requires_grad)
print(f"Total trainable LoRA parameters: {total_params:,}")Total trainable LoRA parameters: 2,666,528
如我们所见,使用LoRA时,我们将可训练参数的数量减少了将近50倍。
现在,让我们通过打印模型架构来再次检查这些层是否按预期被修改。















 2471
2471

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









