







CTF逆向-[SUCTF2019]hardcpp-使用优化过的deflat.py处理混淆的控制流并将cpp的lambda解析得到实际处理逻辑
来源:https://buuoj.cn/
内容:
附件:链接:https://pan.baidu.com/s/17OePBZh7Mvv9neqnh-Sv2g?pwd=d6kg 提取码:d6kg
答案:#flag{mY-CurR1ed_Fns}
总体思路
发现混淆的执行流,使用原版的处理不太成功,处理后少了很多信息
使用优化版的进行处理得到混淆少得多的代码
逐个点开lambda函数查看其功能,并逐行还原其对input的处理
发现v_input_chr就是v_input[0]并且根据提示,反算md5得到原始值
代入式子计算得到答案
详细步骤
-
查看文件内容
-
发现存在执行流混淆
-
使用deflat.py对其进行反混淆
py .\deflat.py -f .\hardCpp --addr 0x04007e0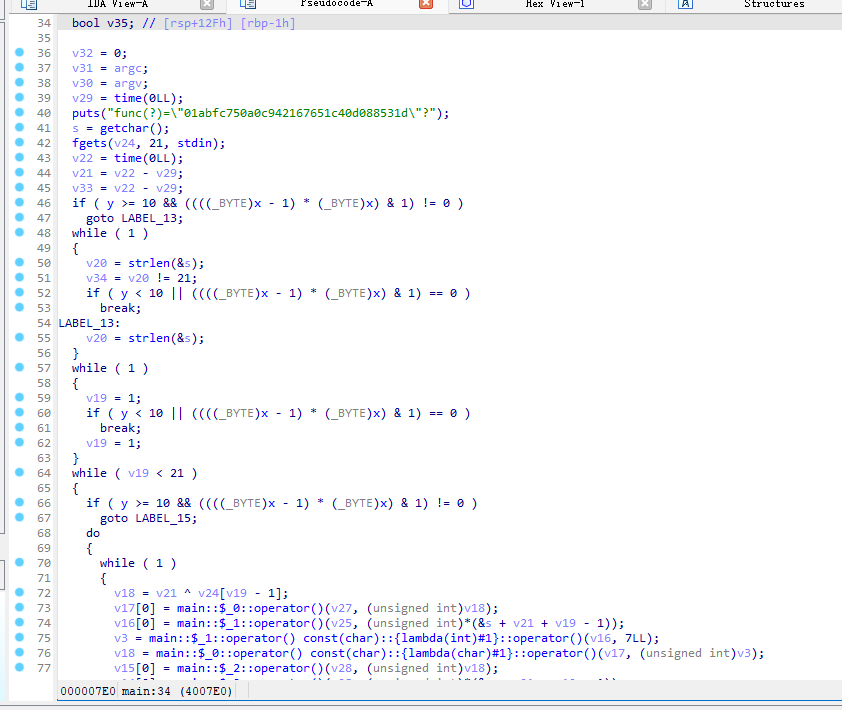
-
尝试启动远程动调以查看x和y的值,但发现缺少libc库无法运行
-
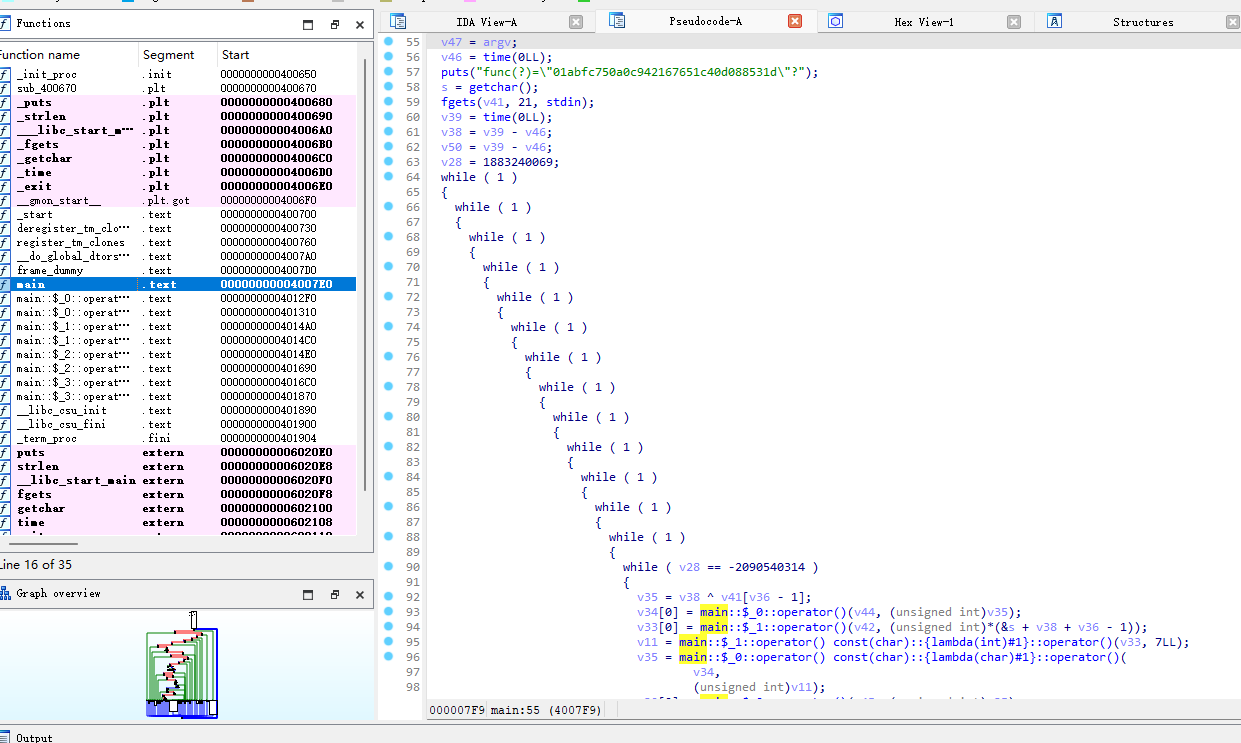
静态查看,发现其实是对输入的每一个字符执行了一系列lambda函数,输入的长度为21个字符
-
cpp的lambda这种是可以直接双击查看其具体实现的,逐个进去分析每个lambda的含义:
-
main::$_0::operator()(v27, (unsigned int)v18): 直接返回a2-
char __fastcall main::$_0::operator()(__int64 a1, char a2) { return a2; }
-
-
main::$_1::operator()(v25, (unsigned int)*(&v_input + v21 + v_pos - 1)):也是直接返回a2-
char __fastcall main::$_1::operator()(__int64 a1, char a2) { return a2; }
-
-
main::$_1::operator() const(char)::{lambda(int)#1}::operator()(v16, 7):返回a1 % a2-
__int64 __fastcall main::$_1::operator() const(char)::{lambda(int)#1}::operator()(char *a1, int a2) { return (unsigned int)(*a1 % a2); }
-
-
main::$_0::operator() const(char)::{lambda(char)#1}::operator()(v17, (unsigned int)v3):返回a1 + a2- 可以看出v_result = *(&v_temp-16) + * v_temp = v_a2 + v_a1

-
main::$_2::operator()(v28, (unsigned int)v18):返回 (a1 & 0xff00) + (a2 & 0x00ff)-
v_temp = v_a1; *((_BYTE *)&v_temp - 16) = v_a2; LOBYTE(v_temp) = *((_BYTE *)&v_temp - 16); v_result = v_temp; -
看出v_result = 高位(v_a1) 低位(v_a2)
-

-
-
main::$_2::operator() const(char)::{lambda(char)#1}::operator()(v_result, 18LL):返回 a1 ^ a2-
__int64 __fastcall main::$_2::operator() const(char)::{lambda(char)#1}::operator()(_BYTE *a1, char a2) { return (unsigned int)(char)(a2 ^ *a1); }
-
-
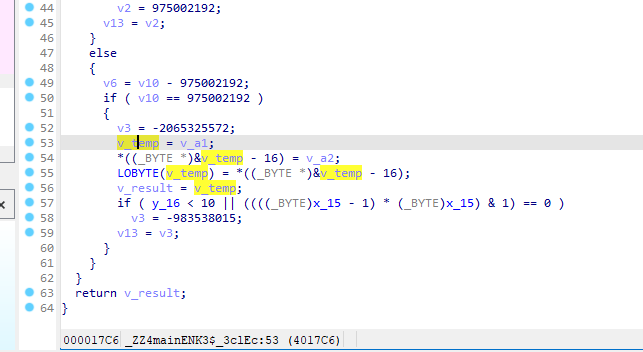
main::$_3::operator()(v26, (unsigned int)v4):返回 (a1 & 0xff00) + (a2 & 0x00ff)-
v_temp = v_a1; *((_BYTE *)&v_temp - 16) = v_a2; LOBYTE(v_temp) = *((_BYTE *)&v_temp - 16); v_result = v_temp; -
发现逻辑和上两个函数一致,也是 v_result = 高位(v_a1) 低位(v_a2)
-
-
-
main::$_3::operator() const(char)::{lambda(char)#1}::operator()(v13, 3LL):返回 a1 * a2-
__int64 __fastcall main::$_3::operator() const(char)::{lambda(char)#1}::operator()(char *a1, char a2) { return (unsigned int)(a2 * *a1); }
-
-
-
综上所述,程序的流程化简为,经过观察,发现v_input_chr应该是v_input的基地址,则理所当然将v_input_chr作为v_input[0]
-
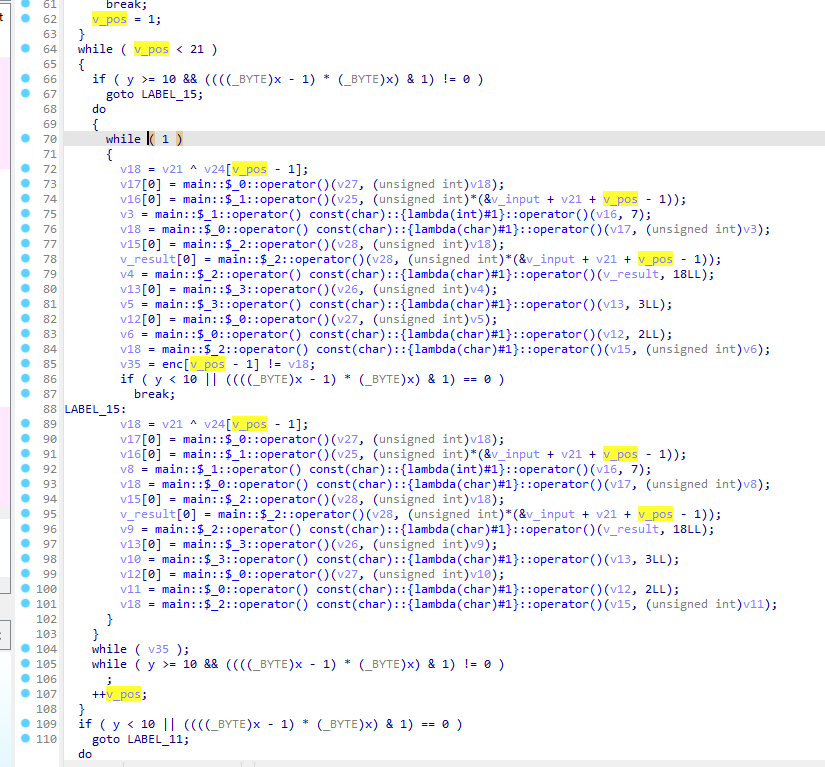
for(int v_pos=1;v_pos<21;v_pos++){ v18 = v_equal_0 ^ v_input[v_pos - 1]; v17[0] = f_a2(v27, (unsigned int)v18); v16[0] = f_a2_same(v25, (unsigned int)*(&v_input_chr + v_equal_0 + v_pos - 1)); v3 = f_a1_mod_a2(v16, 7); v18 = f_a1_add_a2(v17, (unsigned int)v3); v15[0] = f_byte_merge((__int64)v28, v18); v_result[0] = f_byte_merge((__int64)v28, *(&v_input_chr + v_equal_0 + v_pos - 1)); v4 = f_a1_xor_a2(v_result, 18); v13[0] = f_byte_merge_same((__int64)v26, v4); v5 = f_a1_multi_a2(v13, 3); v12[0] = f_a2(v27, (unsigned int)v5); v6 = f_a1_add_a2(v12, 2LL); v18 = f_a1_xor_a2(v15, v6); v35 = enc[v_pos - 1] != v18; } -
全程需要保证v35为
true
-
-
根据语义,进一步化简得到,这里是一行一行推的,要耐心
-
for(int v_pos=1;v_pos<21;v_pos++){ v_current_char = v_equal_0 ^ v_input[v_pos - 1];// v_input[i-1] v_current_char_arr[0] = f_a2(v27, (unsigned int)v_current_char);// v_input[i] v_previous_char_arr[0] = f_a2_same(v25, (unsigned int)*(&v_input_chr + v_equal_0 + v_pos - 1));// v_input[i-1] v_prev_mod_7 = f_a1_mod_a2(v_previous_char_arr, 7);// v_input[i-1] % 7 v_current_char = f_a1_add_a2(v_current_char_arr, (unsigned int)v_prev_mod_7);// v_input[i] + v_input[i-1] % 7 v_cur_add_v_prevmod7[0] = f_byte_merge((__int64)v28, v_current_char);// v_input[i] + v_input[i-1] % 7 v_result[0] = f_byte_merge((__int64)v28, *(&v_input_chr + v_equal_0 + v_pos - 1));// v_input[i-1] v_prev_xor_18 = f_a1_xor_a2(v_result, 18);// v_input[i-1] ^ 18 v_prev_xor_18_same[0] = f_byte_merge_same((__int64)v26, v_prev_xor_18);// v_prev_xor_18 v_prev_xor_18_mutil_3 = f_a1_multi_a2(v_prev_xor_18_same, 3);// v_prev_xor_18_mutil_3 v_prev_xor_18_mutil_3_same[0] = f_a2(v27, (unsigned int)v_prev_xor_18_mutil_3); v_prev_xor_18_mutil_3_add2 = f_a1_add_a2(v_prev_xor_18_mutil_3_same, 2LL);// (v_prev ^ 18) * 3 + 2 v_current_char = f_a1_xor_a2(v_cur_add_v_prevmod7, v_prev_xor_18_mutil_3_add2);// (v_input[i] + v_input[i-1] % 7) ^ ((v_prev ^ 18) * 3 + 2) v35 = enc[v_pos - 1] != v_current_char; // 判断enc[v_pos-1] == (v_input[i] + v_input[i-1] % 7) ^ ((v_prev ^ 18) * 3 + 2) }
-
-
综上,题意为迭代判断
enc[v_pos-1] == (v_input[i] + v_input[i-1] % 7) ^ ((v_prev ^ 18) * 3 + 2) -
双击
enc变量,shift+e复制他的值F32E1836E14C22D1F98C4076F40E0005A3900EA5 -
再次观察全部代码,发现v_input_chr=getchar()的上一句有一个提示,puts(“func(?)=“01abfc750a0c942167651c40d088531d”?”);// md5(‘#’)
- 猜测是md5,将其拖入到sojson的md5解密中,得到其值为
md5('#') - [外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-7UtH1gs0-1651240604659)(https://raw.githubusercontent.com/serfend/res.image.reference/main/image-20220429214107980.png)]
- 猜测是md5,将其拖入到sojson的md5解密中,得到其值为
-
则v_input[0] = ‘#’
-
即可编写exp如下
-
v_enc = 'F32E1836E14C22D1F98C4076F40E0005A3900EA5' v_enc = bytearray.fromhex(v_enc) # puts("func(?)="01abfc750a0c942167651c40d088531d"?");// md5('#') v_input_chr = ord('#') v_input = [v_input_chr] # 原式: (v_input[i] + v_input[i-1] % 7) ^ ((v_input[i-1] ^ 18) * 3 + 2) == v_enc[i-1] # 两边同时异或((v_input[i-1] ^ 18) * 3 + 2), # 化简为:(v_input[i] + v_input[i-1] % 7) = v_enc[i-1] ^ ((v_input[i-1] ^ 18) * 3 + 2) # 将左边移到右边,化简为:v_input[i] = (v_enc[i-1] ^ ((v_input[i-1] ^ 18) * 3 + 2)) - v_input[i-1] % 7 for i in range(1, 21): v = ((v_input[i-1] ^ 18) * 3 + 2) v_input_i = (v_enc[i-1] ^ v) - (v_input[i-1] % 7) v_input_i &= 0xff # 可打印的字符串范围必然在 0xff 以内,此处防溢出 v_input.append(v_input_i) flag = [chr(x) for x in v_input] print(''.join(flag)) # #flag{mY-CurR1ed_Fns}
-
-
结果为
#flag{mY-CurR1ed_Fns}

其他文档
-
CTF逆向-常用的逆向工具 提取码:pnbt
-
B站教程中国某省队CTF集训(逆向工程部分)
- 中国某省队CTF集训(逆向工程部分)(已授权)(一)
- 基础加密方式例如
XXTEA、Base64换表 - Python库
Z3方程式、不定式等的约束求解 - 基础的假跳转花指令(脏字节)
- 非自然程序流程
- 扁平化程序控制流
- OLLVM程序流程(虚拟机壳) 很难一般不考
- ida里面按
X键跟踪,寻找所有Ty为w的引用(即类型是写入的),通常就是关键位置
- 中国某省队CTF集训(逆向工程部分)(已授权)(二)
- ollydb动调去壳,upx为例子
- python的逆向和自定义虚拟指令
- 使用pycdc 提取码:dorr 解密python编译的exe或者pyc
- 逐条去解析用py字典手动实现的指令调用
- C++编译的程序的逆向
- 中国某省队CTF集训(逆向工程部分)(已授权)(三)
- 简单模运算加密
- base58 寻找一下特别大的数,这种数通常是算法的标识,或者ida7.7版本以上自带的
find crypt插件ctrl+alt+f - 常见的关键位置是有新的内存分配的地方通常是关键地方,或者函数中间突然return的地方也是
- 迷宫题 注意绘制出来就好
- 动调题
- 注意观察会执行的反调试分支,例如出现
int 3,需要跳过去
- 注意观察会执行的反调试分支,例如出现
-
基本知识
更多CTF逆向题通用性做法和常用工具下载参考该博文内容:CTF逆向Reverse题的玩法
相关逆向CTF题
-
Python
-
远程调试汇编
-
流程控制
-
逆向思维
-
安卓
-
虚拟机
-
反调试和SMC
-
加密
-
花指令
-
流程混淆的扁平化处理
















 305
305











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









