







2021 Principled Synthetic-to-Real Dehazing Guided by Physical
Priors, CVPR2021
https://github.com/zychen-ustc/PSD-Principled-Synthetic-to-Real-Dehazing-Guided-by-Physical-Priors

2、训练细节
不是一个纯粹的端到端的深度学习模型,结合了先验知识需要根据作者的方法修改最后的层网络结构,再进行训练(You should replace the final deconv layer by two branches for transmission maps and dehazing results, separately. The branch can be consisted of two simple convolutional layers. In addition, you should also add an A-Net to generate atmosphere light.)
(1)首先在大量合成数据进行预训练
(2)然后进行微调,利用无标签的真实数据进行域迁移,设计了 a prior loss committee指导训练(利用了几个基础良好的物理先验值,并将它们合并到 a prior loss committee)
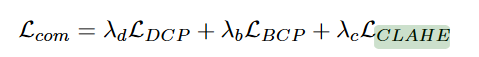
暗通道损失+ 亮通道损失+动态均衡化损失
(3)微调过程中利用了 不遗忘学习,保持模型性能(hizhong Li and Derek Hoiem. Learning without forgetting.)
1、论文训练数据,RESIDE数据中的户外合成数据,OTS_ALPHA,数据有313590个图片+ RESIDE数据的无标注真实图片,Unannotated Real Hazy Images
训练数据输入 随机剪裁 256×256, 归一化 −1 to 1
2、训练参数
(1) 主干网络,MSBDN,可以换最新的高性能网络
(2)第一步,预训练,
(3)第二步,无监督的情况下使用真实数据对其进行微调。使用RESIDE数据集中的RTT作为微调数据
3、用到了非遗忘学习
Learning without Forgetting 作者:Zhizhong Li, Derek Hoiem
主要思路:
模型的记忆功能其实就体现在参数的值上,要想让模型有“记忆功能”,模型的参数就不能有太大的变化,模型在拟合新数据的时候,参数肯定是会发生变化的,要想让参数记住原来的数据,直观的方法就是混入原来的数据一块训练,但是如果没有原来的数据怎么办呢,文章的作者就提出了一种类似 “伪标签” 的策略,既然我只是要模型也要见到原来数据分布,那我完全可以用旧模型先在部分新数据上打上标签,然后训练的时候,这部分打上“伪标签”的训练数据可以看成是原来的数据,和剩下的新数据一块投入训练,这就是 learning without forgetting 的关键思路。https://blog.csdn.net/matrix_space/article/details/87513781
















 2064
2064











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









