






难题
我们公司出现大量有一个层级的标签,多少层并没有限制,在搜索时候用户可以选择标签,用户可以选择多个顶、中、底部的标签,而我们与其他表关联需要的是底部标签才可以查询出指定数据。
举个例子:
- 500-100-11
- 500-201-50
用户选择了标签 500 的顶部标签我们需要拿到底部标签 11 和 50。然后通过 in(11,50) 的方式获取数据, 这种方式在标签量少的时候还可以使用,但是一旦多了 in 的速度会非常慢,而且也会导致 SQL 变得十分的冗长。
我们使用常规的方式进行优化但是结果不尽人意比如: MySQL in 太多过慢的 3 种解决方案
直到发现这个模型让我们公司系统直接解决了标签问题,当然这个并不是唯一解决这个问题的方案比如还有 嵌套集合模型 等,但是这个模型是目前比较合适我们公司项目。
下面先来看一下这个模型概况,这个模型是一个十分简单方案。
模型简介
嵌套集合模型(nested set model)是一种用于组织层次结构数据的方法。该模型使用两个整数值(左值和右值)来表示每个节点,并通过将子节点的左值和右值限制在其父节点的左值和右值之间来实现层次结构。
通过使用嵌套集合模型,可以轻松地执行许多与层次结构相关的操作,例如查找给定节点的所有子节点、查找给定节点的父节点、计算子节点的数量等等。该模型在许多领域都有广泛的应用,例如数据库设计、内容管理系统等。
模型建立
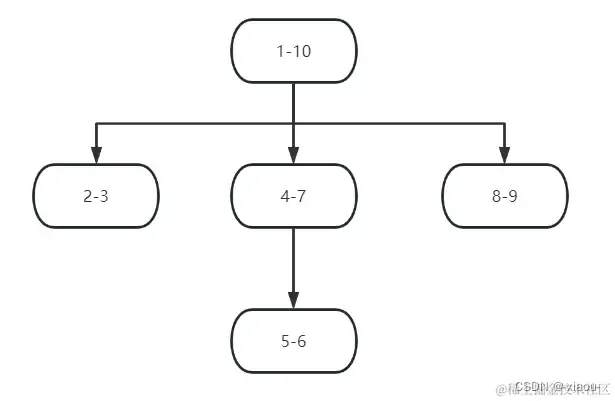
正常没有接触到这个模型的人看到这张图都会一脸懵逼,这些数据代表什么,怎么用新增结点、删除结点
这些
1-10指的是在这个结点的下一层的左值和右值的范围,我们发现图上所有的结点子结点左值右值均被父结点包含。
新增结点
新增结点可以分为 2 种情况一种是添加子结点一种是添加兄弟结点。
添加子结点
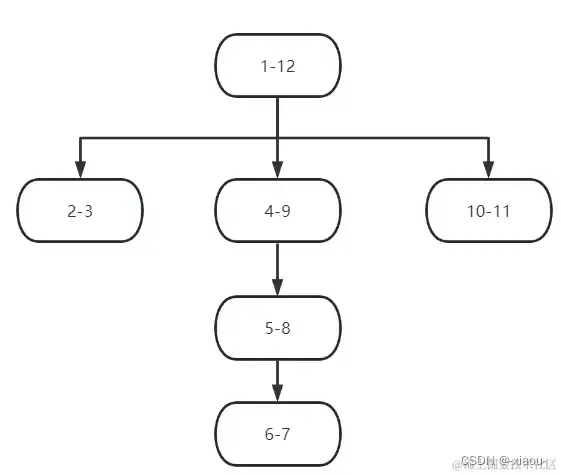
在上图中在 5-6 添加一个子结点。
规则:
- 取出插入结点的父结点 leftValue
- 将所有大于 leftValue 所有值(不区分左值和右值) 全部 + 2
- 插入结点 左值 = leftValue + 1 右值 = leftValue + 2
SELECT @leftValue := lft FROM table_name WHERE id = '1';
UPDATE table_name SET rgt = rgt + 2 WHERE rgt > @leftValue;
UPDATE table_name SET lft = lft + 2 WHERE lft > @leftValue;
INSERT INTO table_name(id, lft, rgt) VALUES(3, @leftValue + 1, @leftValue + 2);
添加兄弟结点
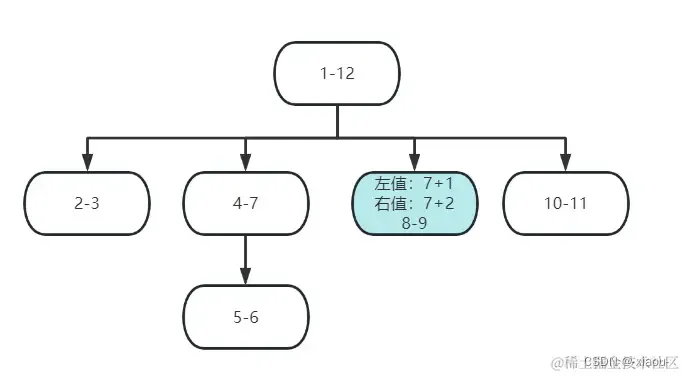
按上图中直接在 4-7 和 8-9 中间加一个新结点。
规则:
- 取出插入结点左边结点的右值定位 rightValue
- 将所有大于 rightValue 所有值(不区分左值和右值) 全部 + 2
- 插入结点 左值 = rightValue + 1 右值 = rightValue + 2
SELECT @rightValue := rgt FROM table_name WHERE id = '1';
UPDATE table_name SET rgt = rgt + 2 WHERE rgt > @rightValue;
UPDATE table_name SET lft = lft + 2 WHERE lft > @rightValue;
INSERT INTO table_name(id, lft, rgt) VALUES(2, @rightValue + 1, @rightValue + 2);
删除结点
删除结点要分为 删除结点其子结点 和 删除当前结点保留叶子结点 两种。

删除结点其子结点
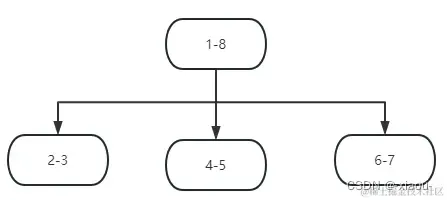
按上图中删除 4-7 结点。
删除叶子结点比较简单,仅仅删除自己就可以了, 但是如果是子结点会造成将子结点和它孩子结点一并删除。
- 获取要被删除结点的左值 (leftValue) 和右值 (rightValue) 并且求出宽度(width = rightValue - leftValue + 1)。
- 删除所有 左值在 leftValue 和 rightValue 范围内的值(左包含)。
- 将所有的大于 rightValue 的值(不区分左值和右值) 全部 - width

SELECT @leftValue := lft, @rightValue := rgt, @width := rgt - lft + 1
FROM table_name
WHERE id = 'value';
DELETE FROM table_name WHERE lft BETWEEN @leftValue AND @rightValue;
UPDATE table_name SET rgt = rgt - @width WHERE rgt > @rightValue;
UPDATE table_name SET lft = lft - @width WHERE lft > @rightValue;
删除当前结点保留叶子结点
按上图中删除 4-7 结点。
上面的方法会导致删除子结点下的孩子结点,在某些情况下并不想删除被删除结点下的子结点。
- 获取要被删除结点的左值 (leftValue) 和右值 (rightValue) 并且求出宽度(width = rightValue - leftValue + 1)。
- 删除左值 = leftValue 的即删除需要删除结点。
- 将被删除结点的子结点的左右值全部缩减 1。
- 将所有的大于 rightValue 的值(不区分左值和右值) 全部 - 2。
SELECT @leftValue := lft, @rightValue := rgt, @width := rgt - lft + 1
FROM table_name
WHERE id = 'value';
DELETE FROM table_name WHERE lft = @leftValue;
UPDATE table_name SET rgt = rgt - 1, lft = lft - 1 WHERE lft BETWEEN @leftValue AND @rightValue;
UPDATE table_name SET rgt = rgt - 2 WHERE rgt > @rightValue;
UPDATE table_name SET lft = lft - 2 WHERE lft > @rightValue;
模型使用
上面已经完成构建和维护模型规则,那我们应该如何使用这个模型呢?🤔
我们先简单构建一下模型
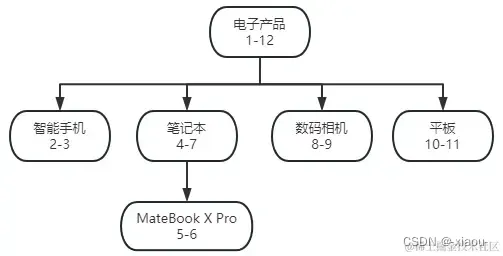
# 创建数据表
CREATE TABLE `tags_tree` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(255) NOT NULL,
`lft` int NOT NULL,
`rgt` int NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci;
# 插入数据
INSERT INTO `tags_tree` (`id`, `name`, `lft`, `rgt`) VALUES (1, '电子产品', 1, 12);
INSERT INTO `tags_tree` (`id`, `name`, `lft`, `rgt`) VALUES (2, '智能手机', 2, 3);
INSERT INTO `tags_tree` (`id`, `name`, `lft`, `rgt`) VALUES (3, '笔记本', 4, 7);
INSERT INTO `tags_tree` (`id`, `name`, `lft`, `rgt`) VALUES (4, 'MateBook X Pro', 6, 6);
INSERT INTO `tags_tree` (`id`, `name`, `lft`, `rgt`) VALUES (5, '数码相机', 8, 9);
INSERT INTO `tags_tree` (`id`, `name`, `lft`, `rgt`) VALUES (6, '平板', 10, 11);
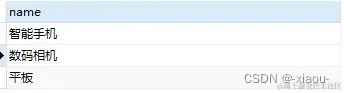
检索所有叶子节点
SELECT name FROM tags_tree WHERE rgt = lft + 1;
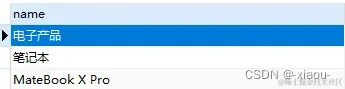
检索节点路径
SELECT parent.name
FROM tags_tree AS node,
tags_tree AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
AND node.name = 'MateBook X Pro'
ORDER BY node.lft
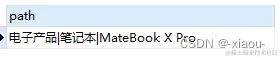
SELECT GROUP_CONCAT(parent.name SEPARATOR "|") as path
FROM tags_tree AS node,
tags_tree AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
AND node.name = 'MateBook X Pro'
ORDER BY node.lft
获取直接父结点
SELECT parent.name
FROM tags_tree AS node,
tags_tree AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
AND node.name = 'MateBook X Pro' AND parent.`name` != 'MateBook X Pro'
ORDER BY parent.rgt - parent.lft
LIMIT 1;

获取结点深度
SELECT node.name, (COUNT(parent.name) - 1) AS depth
FROM tags_tree AS node,
tags_tree AS parent
WHERE node.lft BETWEEN parent.lft AND parent.rgt
GROUP BY node.name
ORDER BY node.lft;

获取结点下的所有结点
这个个也是我们需要的 SQL 写法
SELECT node.name
FROM tags_tree parent
JOIN tags_tree node
ON node.lft BETWEEN parent.lft AND parent.rgt
WHERE parent.id IN (3);
作者信息
- 多多点赞会变好看,多多留言会变有钱,多多收藏会变幸运。
- 联系方式添加微信 -xiaou- 备注:csdn

















 2345
2345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









