




 该项目实现了使用Lucene对数据库表数据的全文检索,支持增量更新和近实时查询。启动时多线程加载磁盘索引,通过定时任务监测数据库变化,使用RAMDirectory缓存,达到一定数量后清理并持久化。同时提供了代码解析,包括索引读取、数据源刷新任务等,项目已在GitHub开源。
该项目实现了使用Lucene对数据库表数据的全文检索,支持增量更新和近实时查询。启动时多线程加载磁盘索引,通过定时任务监测数据库变化,使用RAMDirectory缓存,达到一定数量后清理并持久化。同时提供了代码解析,包括索引读取、数据源刷新任务等,项目已在GitHub开源。
最近一直在学习Lucene,今天分享一个个人的简单开源项目,可以将数据库中特定表的数据索引化,并支持了增量更新,近实时查询以及多线程索引建立的相关功能。
1.需求
为数据库中特定的表的数据提供全文检索功能,并且数据库的更新可以反映到全文检索的结果上(即近实时查询)。
2.实现思路
项目启动时使用多线程读取已经持久化在磁盘中的索引文件,并开启一个定时任务定期检索数据库中状态发生更改的数据,使用Lucene提供的RAMDirectory缓存这一部分数据,但为了保证内存使用不超过负荷需要在RAMDirectiory中缓存的document数量达到配置文件的指定数值后进行清理,并将清理的文档持久化到表数据对应的索引磁盘目录下。可以通过下面两个流程图进行简单的思路梳理。
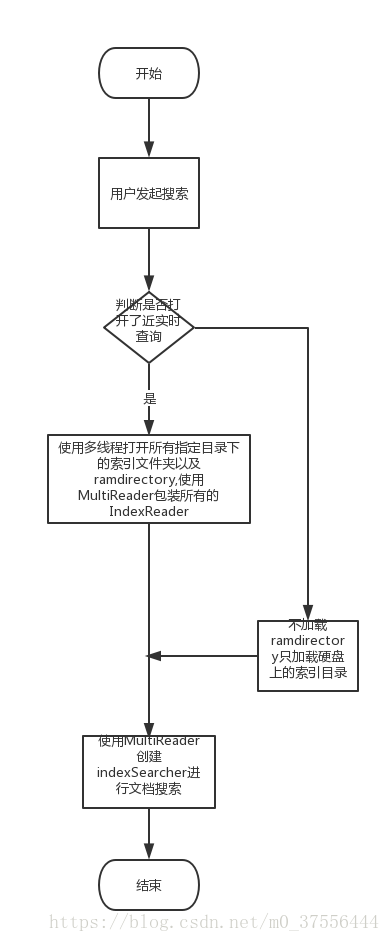
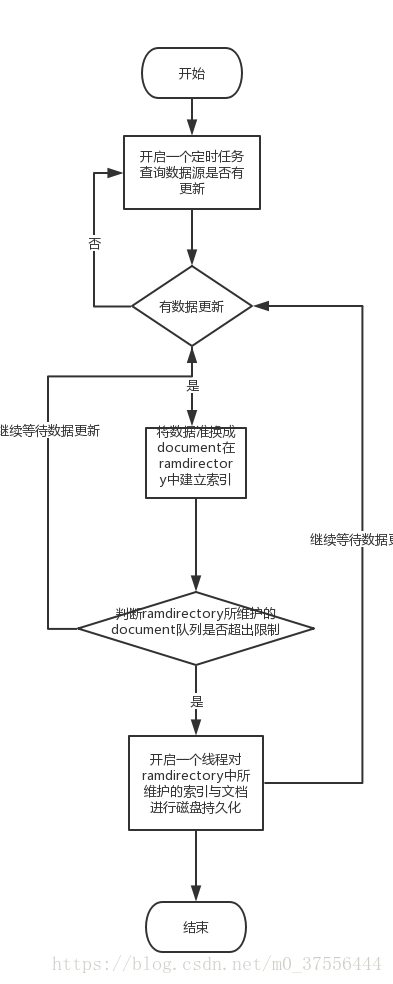
3.代码解析
1.HardDiskIndexReaderBuilderTask
首先我们需要从磁盘中加载已经持久化的索引目录,由于这样的索引目录通常情况下不止一个(通常一个表或者一个业务模块就会对应一个甚至多个索引目录)。所以为了加快索引的读取效率,使用多线程方式进行IndexReader的加载,使用Future异步获取结果。任务类代码如下:
package com.cfh.practice.searchengine.task;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexReader;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.concurrent.Callable;
/**
* @Author: cfh
* @Date: 2018/9/18 15:42
* @Description: 并行读取指定目录下的索引文件的任务类
*/
public class HardDiskIndexReaderBuilderTask implements Callable<IndexReader> {
final Logger log = LoggerFactory.getLogger(HardDiskIndexReaderBuilderTask.class);
//指定当前线程需要搜索的目录
String indexPath;
public HardDiskIndexReaderBuilderTask(String indexPath){
this.indexPath = indexPath;
}
@Override
public IndexReader call(){
try {
log.info("加载{}子目录下的索引", indexPath);
Directory directory = FSDirectory.open(Paths.get(indexPath));
IndexReader indexReader = DirectoryReader.open(directory);
log.info("{}子目录下的索引建立完成", indexPath);
return indexReader;
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
}
2.IndexReaderLoader
IndexSearcher的构建类,使用线程池异步获取所有索引目录下的IndexReader之后包装成MultiReader进行多目录下索引的读取,同时根据需求返回实时或非实时的IndexSearcher供调用者调用。具体的实现细节请参考源码注释
package com.cfh.practice.searchengine.common;
import com.cfh.practice.searchengine.task.HardDiskIndexReaderBuilderTask;
import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;
import org.apache.lucene.index.*;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.File;
import java.io.IOException;
import java.nio.file.Paths;
import java.util.ArrayList;
import java.util.List;
import java.util.concurrent.ExecutionException;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Future;
/**
* @Author: cfh
* @Date: 2018/9/18 16:02
* @Description: IndexSearcher的构建类,根据传入的参数决定是否需要开启近实时查询
*/
public class IndexReaderLoader {
String dirPath;
ExecutorService executorService;
Logger log = LoggerFactory.getLogger(IndexReaderLoader.class);
public IndexReaderLoader(String dirPath, ExecutorService executorService) {
this.dirPath = dirPath;
this.executorService = executorService;
//先在所有子目录下commit一遍防止读取时出现no segments异常
try {
writeAndCommit(dirPath);
} catch (Exception e) {
e.printStackTrace();
log.info("索引目录初始化出现错误:{}",e.getCause());
}
loadIndexReaderFromHardDisk(dirPath, executorService);
}
public void writeAndCommit(String dirPath) throws Exception{
log.info("初始化索引目录");
File rootPath = new File(dirPath);
File[] files = rootPath.listFiles();
for(File file : files){
if(file.exists() && file.isDirectory()){
Directory directory = FSDirectory.open(Paths.get(file.getPath()));
Analyzer analyzer = new SmartChineseAnalyzer();
IndexWriterConfig iWConfig = new IndexWriterConfig(analyzer);
IndexWriter indexWriter = new IndexWriter(directory, iWConfig);
indexWriter.commit();
indexWriter.close();
}
}
log.info("索引初始化完成");
}
private List<IndexReader> loadIndexReaderFromHardDisk(String dirPath, ExecutorService executorService){
List<IndexReader> readers = new ArrayList<>();
log.info("从根路径{}下加载索引", dirPath);
File rootPath = new File(dirPath);
File[] files = rootPath.listFiles();
log.info("路径{}下有{}个子目录", dirPath, files.length);
List<Future<IndexReader>> futures = new ArrayList<>();
for(File file : files){
if(file.isDirectory() && file.exists()){
Future<IndexReader> future = executorService.submit(new HardDiskIndexReaderBuilderTask(file.getPath()));
futures.add(future);
}
}
//异步获取读取到的索引的结果
for(Future<IndexReader> future : futures){
try {
IndexReader result = future.get();
readers.add(result);
log.info("读取完{}条索引", result.getRefCount());
} catch (InterruptedException e) {
e.printStackTrace();
} catch (ExecutionException e) {
e.printStackTrace();
}
}
return readers;
}
/**
* 获取非近实时的IndexSearcher
* 这种写法每次获取索引都需要读取一遍磁盘,一般只适用于对搜索实时性特别高的情况
* @return
*/
public IndexSearcher getUnRealTimeSearch() {
List<IndexReader> indexReaderList = loadIndexReaderFromHardDisk(dirPath, executorService);
IndexReader[] indexReaders = indexReaderList.toArray(new IndexReader[indexReaderList.size()]);
MultiReader multiReader = null;
try {
multiReader =  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 868
868

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









