






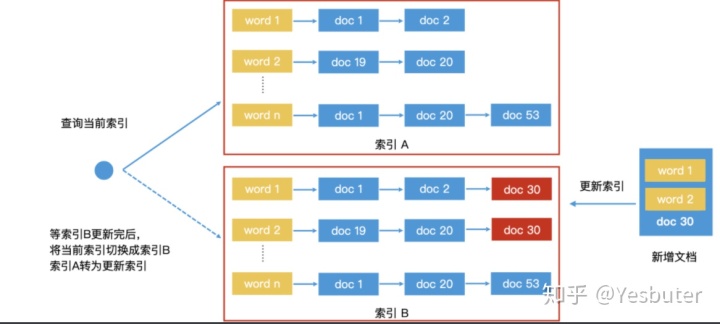
工业界更新索引 ---Double Buffer(双缓冲)机制
Double Buffer就是内存中同时保存两份一样的索引,一个是索引A,一个是索引B。我们会使用一个指针p指向索引A,表示索引A是当前可访问的索引。
如果用户通过p去访问索引A,假如需要更新,这时候只更新索引B。
更新完索引B之后,将指针p通过原子操作从A直接切换到B上。接着,就将索引B当做只读索引,然后更新索引A。
通过这样,保持一个读,一个写,并且来回切换,最终完成高性能的索引更新。并且可以积累一批新数据以后再批量更新。
全量索引结合增量索引
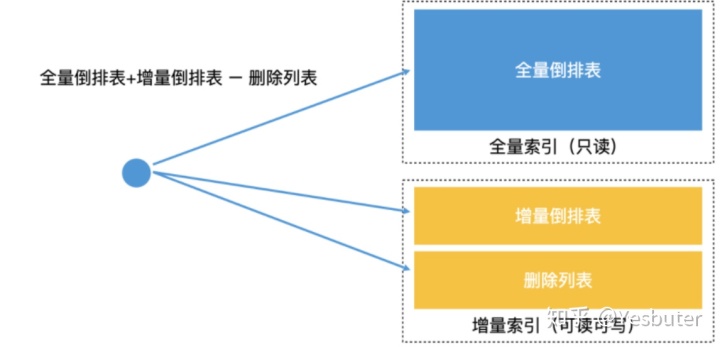
全量索引:系统周期性地处理全部的数据,生成一份完整的索引
增量索引:将新接收到的数据单独建立一个可以存在内存中的倒排索引
全量索引+增量索引:查询发生的时候,同时查询全量索引和增量索引,将合并的结果作为总的结果输出。
删除索引的时候,我们不能直接删除增量索引中的数据(如果直接删除,增量索引中没有这个数据,全量索引中会有这个数据),而是应该增加一个删除列表,将删除的数据记录保存在列表中,检索的时候就将全量索引表和增量倒排表的检索结果和删除列表做对比。
增量索引空间的持续生长
1.完全重建法
如果增量索引的增长速度不是很快,或者全量索引重建代价不大,可以在索引写满内存空间之前,完全重建一次全量索引。然后,旧的增量索引的空间就可以释放。
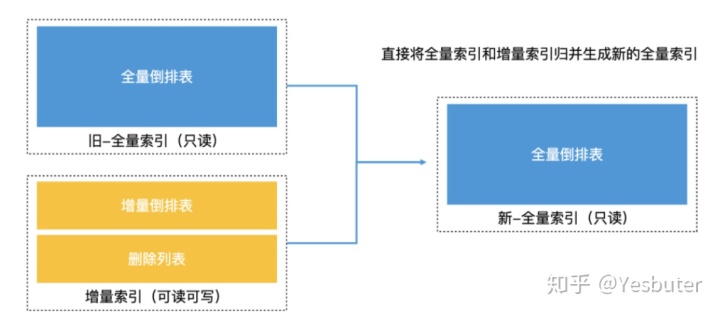
2.再合并法
可以将全量索引想象成一个已经将多个小索引合并好的大索引,然后把增量索引想象成一个新增的小索引。这样可以直接归并全量索引和增量索引,生成一个新的全量索引。!
3.滚动合并法
先生成多个不同层级的索引,然后逐层合并。
如:一个检索系统在磁盘中保存了全量索引、周级索引和天级索引。所谓周级索引,就是根据本周的新数据生成的一份索引,那天级索引就是根据每天的新数据生成的一份索引。在滚动合并法中,当内存中的增量索引增长到一定体量时,我们会用再合并法将它合并到磁盘上当天的天级索引文件中















 93
93











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









