






日常处理xlsx文件时,经常需要按照文件中某一列的信息,筛选出非重复项,采用xlsx内部的函数可以实现,但相对较慢,可以用python编写一个GUI界面的程序。
GUI的界面如下:
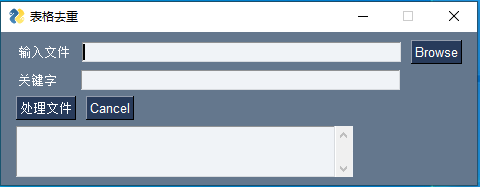
输入文件行通过“Browse”按钮可以选择要处理的文件,支持xlsx格式文件
关键字用于标示要选择的列,需填入该列第一行的数据。
“处理文件”按钮触发文件处理。
处理完成后,下边的文本框显示‘处理完成’
代码如下:
import PySimpleGUI as sg1
import pandas as pd
import openpyxl
# All the stuff inside your window.
layout = [ [sg1.Text('输入文件'), sg1.Input(), sg1.FileBrowse(key='输入')],
[sg1.Text('关键字 '), sg1.Input(key='关键值')],
[sg1.Button('处理文件'), sg1.Cancel()],
[sg1.Output() ]]
# Create the Window
window = sg1.Window('表格去重', layout)
# Event Loop to process "events" and get the "values" of the inputs
while True:
event, values = window.read()
if event in (None, 'Cancel'): # if user closes window or clicks cancel
break
if event =='处理文件':
io1 = values[ '输入']
word1 = values['关键值']
df = pd.read_excel(io1,index_col=None)
#根据关键字word1去重
#得到重复行的索引
duplicate_row = df.duplicated(subset=[word1,],keep=False)
#得到重复行数据
duplicate_data = df.loc[duplicate_row,:]
#重复行保留一个数据
duplicate_data_one= duplicate_data.drop_duplicates(subset=[word1],keep="first").reset_index(drop=True)
#得到无重复行数据
no_duplicate = df.drop_duplicates(subset=[word1] ,keep=False)
#合并数据
Result = pd.concat([no_duplicate,duplicate_data_one])
#在原文件最后写入处理结果
excel_writer = pd.ExcelWriter(io1, engine='openpyxl')
book = openpyxl.load_workbook(excel_writer.path)
excel_writer.book = book
Result.to_excel(excel_writer=excel_writer, sheet_name= '输出结果', index=None)
excel_writer.close()
print('处理完成')
window.close()















 5865
5865











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









