







1. 贡献
跨模态reid常用的方法:
(1)模态对齐:在像素以及特征层面减少跨模态之间的gap(GAN网络生成图像)
(2)模态间的度量学习:通过度量学习技术来优化跨模态的网络(主要关注于描述单个样本之间的关系,而通常忽略全局类/身份(例如,类中心)的变化。)
本文结合两种方法,贡献如下:
- 提出了Class-aware Modality Mix (CMM):用于平滑不同模态之间的差距
- 提出了Center-guided Metric Learning (CML):用于加强跨模态类中心和样本之间的距离约束。CML可以有效地促进模型训练,并取得显著的改进。
- 提出了新颖的网络结构,结合(像素级)模态对齐,以及(特征级)度量学习
2. 模型

模型包括三个部分:
- Pixel-level Class-aware Modality Mix(CMM)
- The feature extractor
- The optimizing losses
Class-aware Modality Mix
(1)传统Mixup方法:
通常是对于两张图像进行线性插值,作用是:减轻过拟合的现象并且提高模型的泛化能力
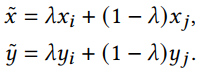
其中,xi,xj代表任意两张图像,yi,yj代表one-hot标签,λ∈[0,1]。
该方法在传统的图像分类上效果好(图像均来自与一个模态),然而在跨模态上却表现不好,因此,提出了CMM
(2)Class-aware modality Mix
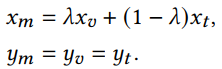
其中,xv∈visible modality, xt∈thermal modality,并且二者属于同一类别。
CMM不需要任何参数学习,可以利用两种模式之间的内部信息来弥合跨模式的差距。

Loss
(1)Feature-Level KL-Divergence
目的:为了减少不同模态之间的差异,将网络不同层提取到的相同ID不同模态图像的特征使用KL散度进行约束
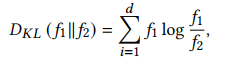
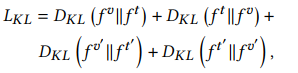
(2)Center-guided Metric Learning
首先需要得到每个模态,每类的类中心:
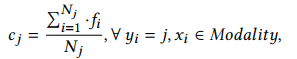
Nj是该模态中该类的样本数,最后得到的visible, thermal, mixed模态的类中心用:𝑐𝑗𝑣, 𝑐𝑗𝑡, 𝑐𝑗𝑚表示
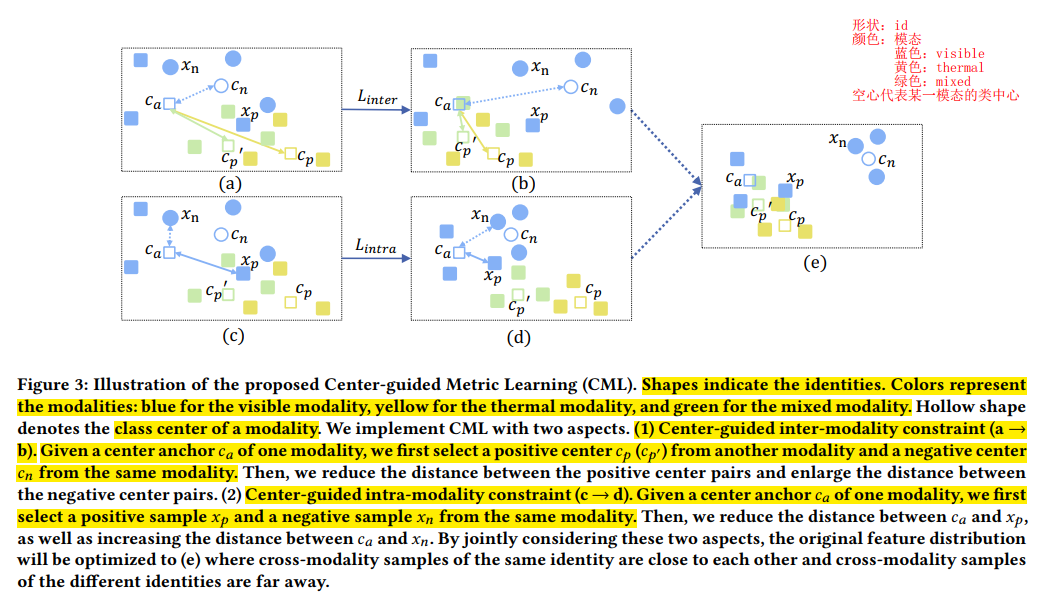
- Center-guided inter-modality constraint
![]()
其中L表示pair-based loss,𝑃𝑐,𝑁𝑐分布代表类中心组成的正、负样本对。
其中,正样本对是跨模态的,负样本对是同模态的
- Center-guided intra-modality constraint
![]()
𝑃𝑠,𝑁𝑠分布代表同模态下类中心与样本组成的正、负样本对。
- Pair mining
样本挖掘是度量学习中关键的一步,因为它决定了如何去找到训练的样本对。
首先,定义S为余弦相似度:
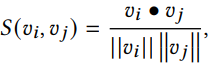
在训练时,pair的选取需要满足如下条件(m=0.1):
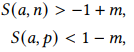
(3)Loss of CML
![]()
L函数可以是triplet loss也可以是MS loss,这里使用的是MS loss:
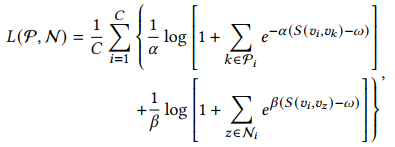
其中,C是所选择的anchors的个数
总损失函数:
![]()
3. 实验
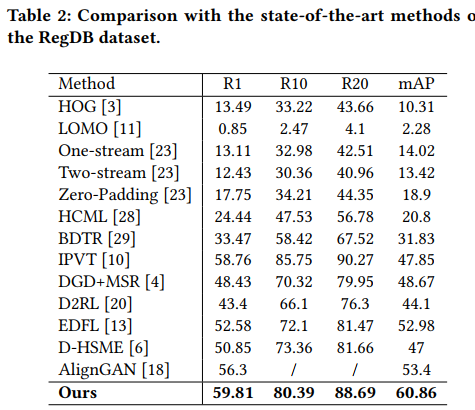
对比实验
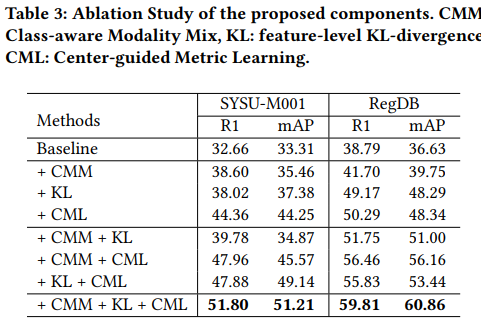
消融实验
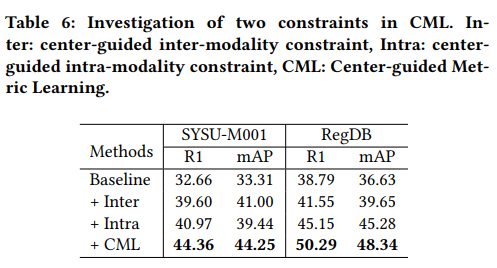
其他实验















 1164
1164











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









