







工作中经常用到hadoop和spark的相关操作,大数据的知识点很多,想要全部掌握烂熟于心很困难,将一些比较重要或经常忘记的点记录一下
1. saprk与hadoop的关系
hadoop是一个完善的大数据生态系统,包含了底层的文件系统HDFS,计算引擎MapReduce,大数据查询引擎Hive,实时流计算storm,资源调度系统Yarn等,而spark主要是用来替换MR计算引擎的,利用内存计算替换磁盘交换来提升计算效率,因此spark可以看作是hadoop生态系统中的一员,一种基于内存的计算引擎,它提供的spark sql、spark streaming、spark ML、GraphX等都是基于内存的大数据计算框架
2. spark的主要角色
spark应用部署常用的有三种模式,即master等于local、standalone、yarn
- local常用来本地测试,不用安装hadoop,也不用启动spark的master、worker进程它使用本地的多核多线程模拟spark的分布式计算,分布式的线程共享同一个进程,即spark submit进程,该进程充当了三种角色,spark任务提交的client进程,spark创建context的driver进程(AppMaster),spark执行任务的executor进程

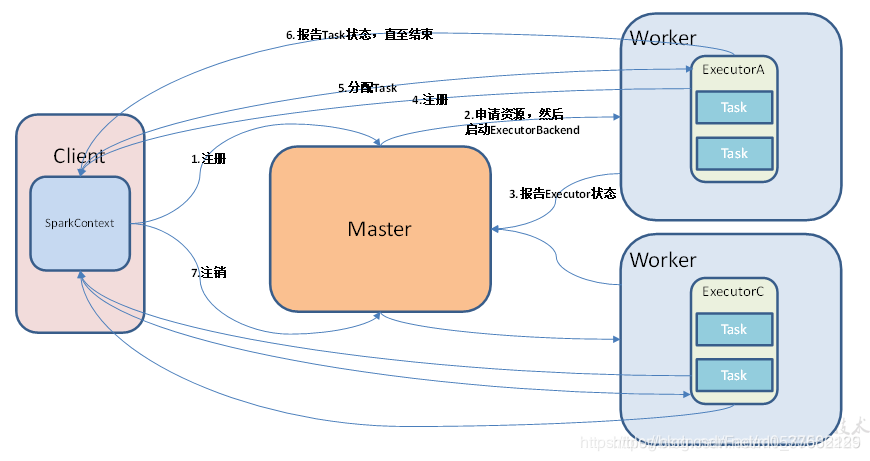
- standalone是spark自带的集群模式,需要设置master和work节点,其中master充当资源调度的角色,接受client提交的spark任务,分配executor资源等,worker充当执行任务的角色,开启executor进程
- Yarn模式是生产中最常用的部署模式,利用yarn来调度资源,执行spark的任务,其中cluster模式表示client与driver分离,driver由Yarn ResourceManager创建并开启App Master,client仅用来提交spark任务,接收yarn的工作日志等。client模式表示client即driver,客户端提交spark任务后,同时作为driver端创建App Master,初始化spark上下文,与所有的executor通信
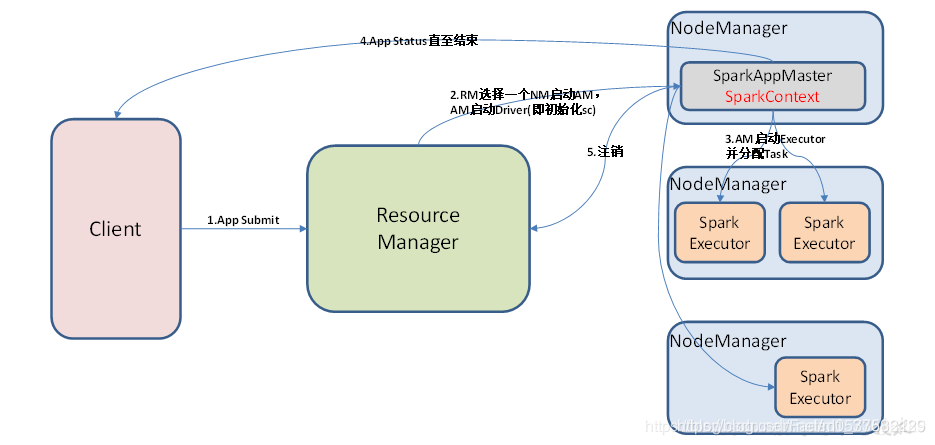
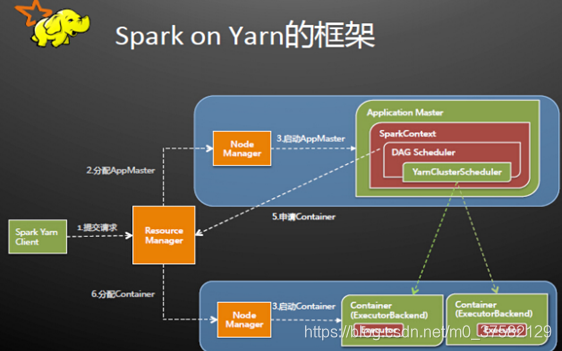

在yarn模式中,仅客户端服务器需要安装spark软件包,作为提交程序使用,其它节点安装hadoop、yarn等即可
3. spark作业的拆分
一个spark任务提交后,sparkContext在初始化时会根据宽窄依赖确定stage数量,其中一个stage内部全是窄依赖操作,RDD之间是一对一的,没有发生数据交换shuffer,没有数据落磁盘,stage与stage之间的操作是宽依赖的,需要打乱数据顺序计算。每个Action操作会触发一个job,一个job是一组stage的组合,其中每个stage会切分为多个task(取决于对应的处理的数据在HDFS上的block数量),executor中的一个线程执行一个task,对应一个partition的数据
job的划分:Action操作
stage的划分:宽窄依赖
task的划分:partition数量(HDFS block数量)















 1236
1236











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









