







4月25日复盘
3.池化层
3.1 概述
池化层 (Pooling) 降低空间维度, 缩减模型大小,提高计算速度. 即: 主要对卷积层学习到的特征图进行下采样(SubSampling)处理。
池化层主要有两种:
-
最大池化 max pooling
最大池化是从每个局部区域中选择最大值作为池化后的值,这样可以保留局部区域中最显著的特征。最大池化在提取图像中的纹理、形状等方面具有很好的效果。
-
平均池化 avgPooling
平均池化是将局部区域中的值取平均作为池化后的值,这样可以得到整体特征的平均值。平均池化在提取图像中的整体特征、减少噪声等方面具有较好的效果。
3.2 池化层计算
整体结构
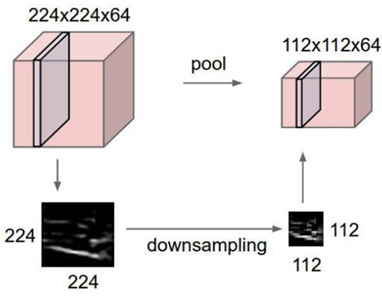
计算
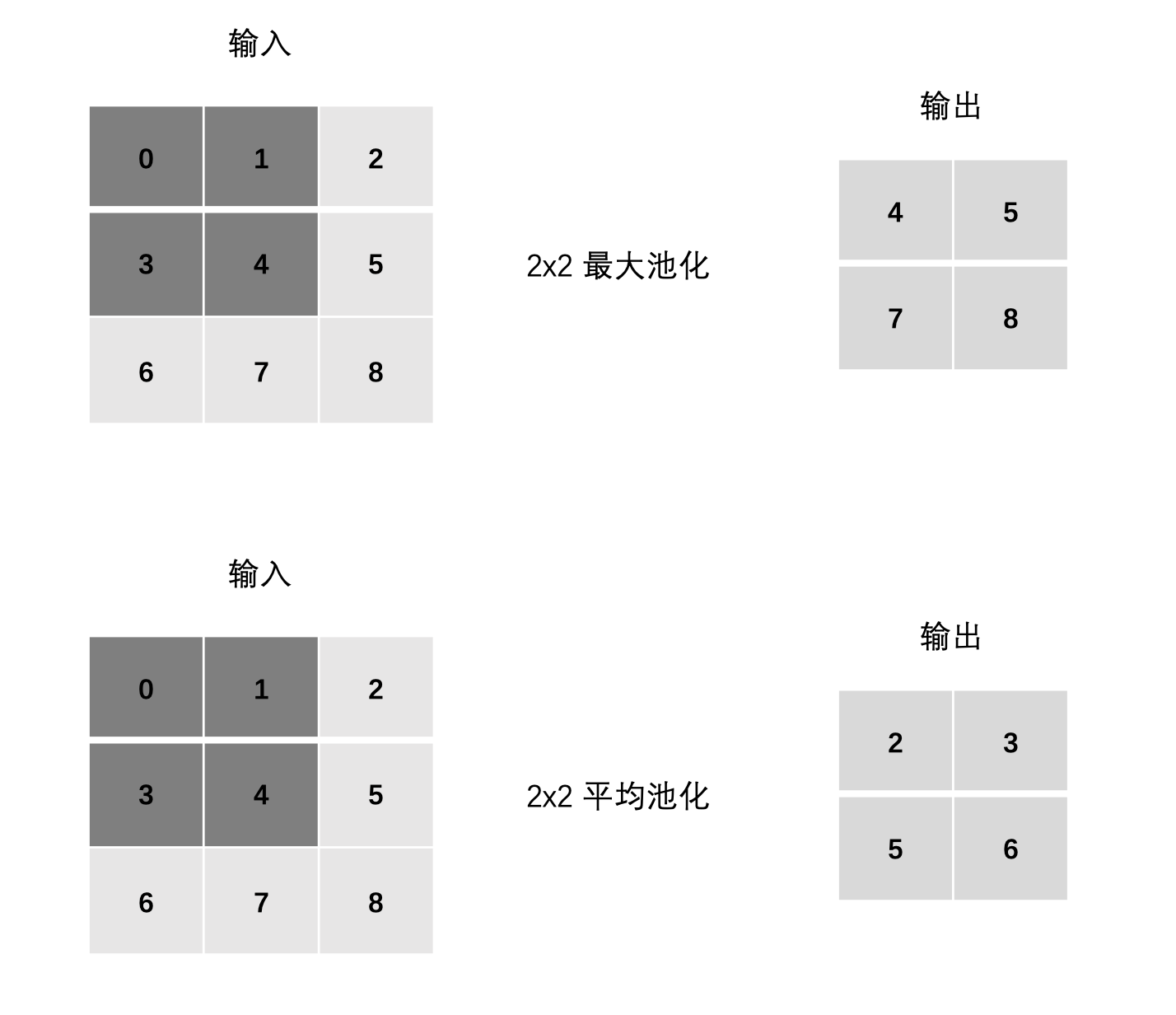
最大池化:
- max(0, 1, 3, 4)
- max(1, 2, 4, 5)
- max(3, 4, 6, 7)
- max(4, 5, 7, 8)
平均池化:
- mean(0, 1, 3, 4)
- mean(1, 2, 4, 5)
- mean(3, 4, 6, 7)
- mean(4, 5, 7, 8)
3.3 步长Stride
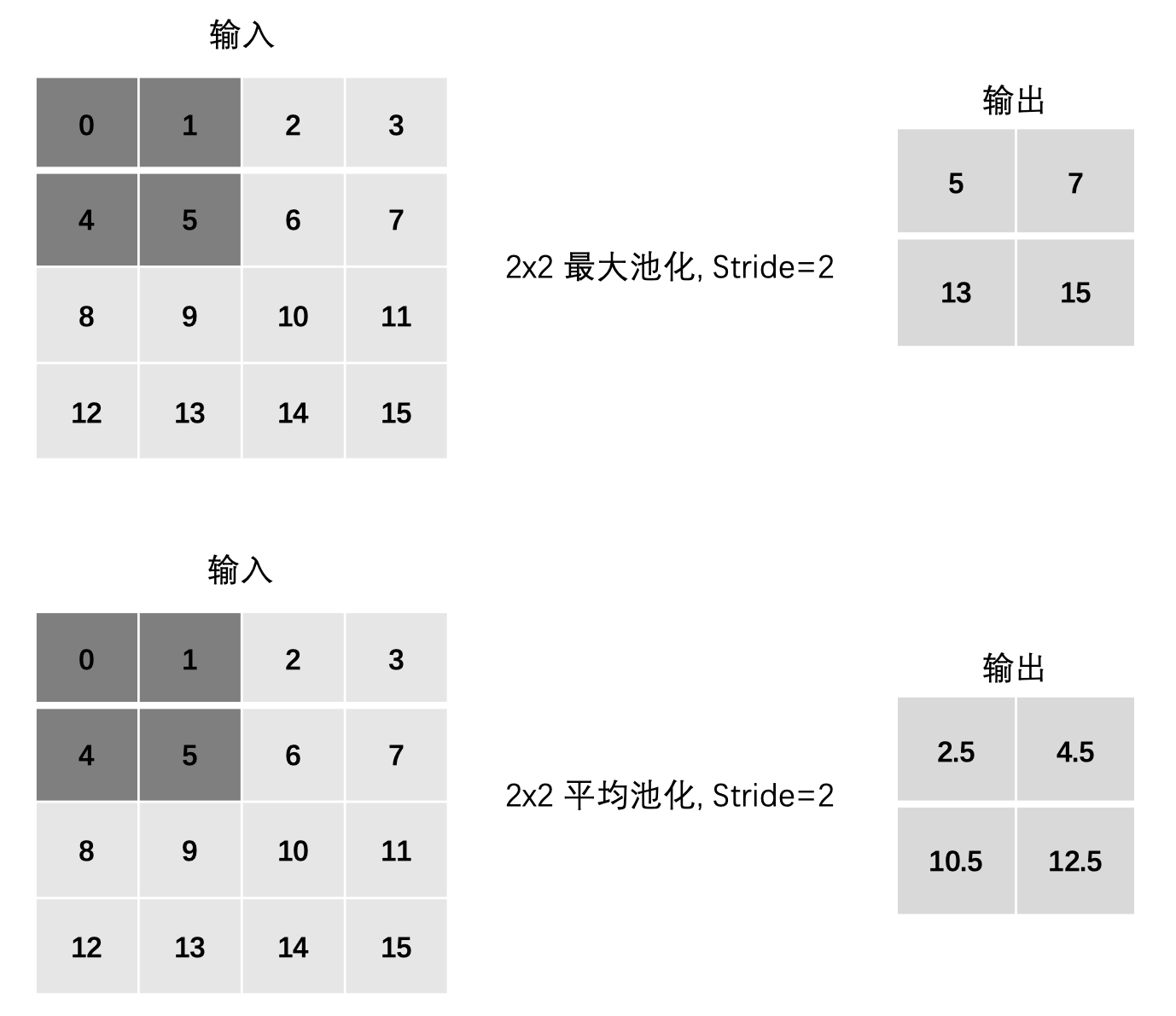
最大池化:
- max(0, 1, 4, 5)
- max(2, 3, 6, 7)
- max(8, 9, 12, 13)
- max(10, 11, 14, 15)
平均池化:
- mean(0, 1, 4, 5)
- mean(2, 3, 6, 7)
- mean(8, 9, 12, 13)
- mean(10, 11, 14, 15)
3.4 边缘填充Padding
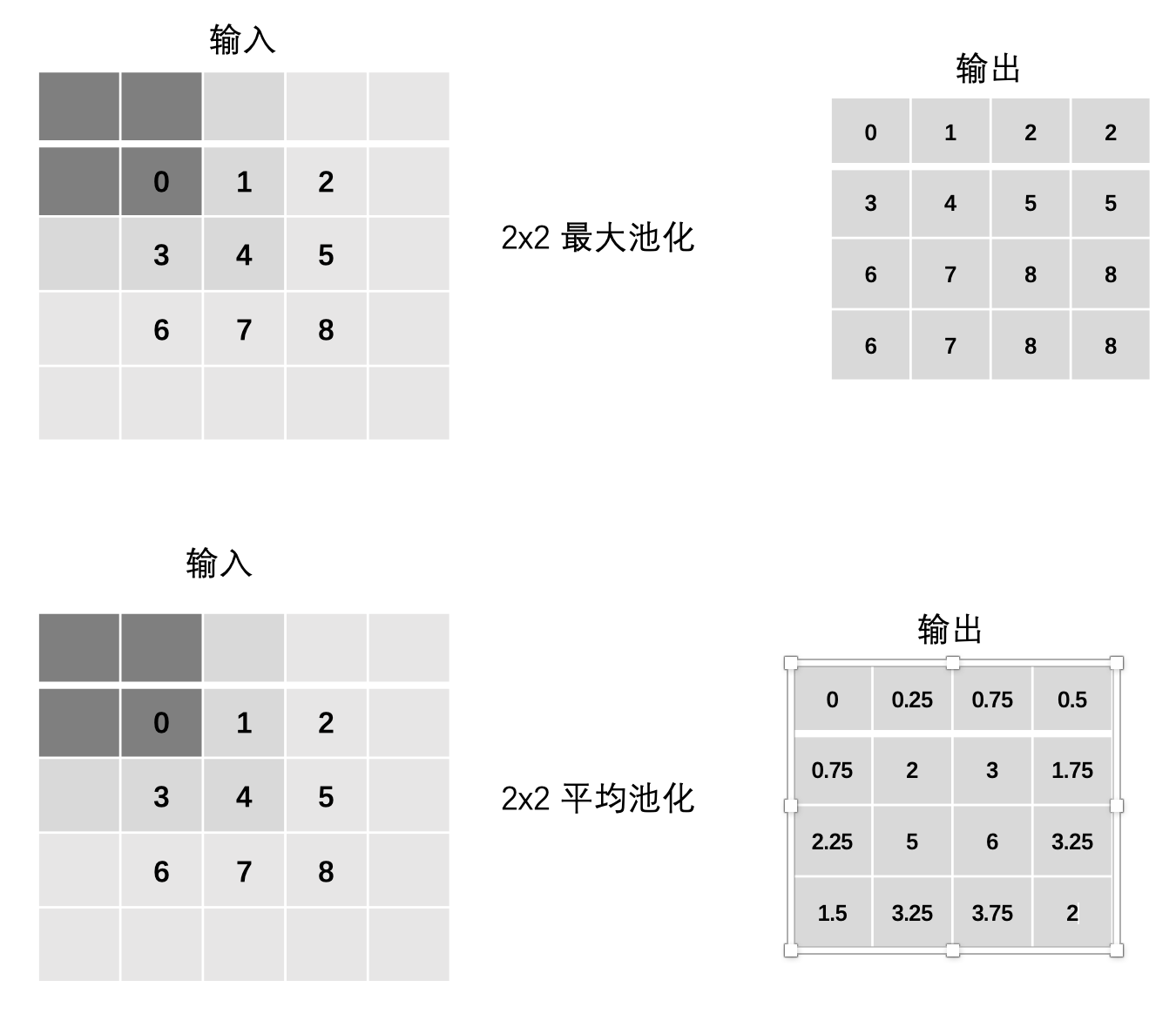
最大池化:
- max(0, 0, 0, 0)
- max(0, 0, 0, 1)
- max(0, 0, 1, 2)
- max(0, 0, 2, 0)
- … 以此类推
平均池化:
- mean(0, 0, 0, 0)
- mean(0, 0, 0, 1)
- mean(0, 0, 1, 2)
- mean(0, 0, 2, 0)
- … 以此类推
3.5 多通道池化计算
在处理多通道输入数据时,池化层对每个输入通道分别池化,而不是像卷积层那样将各个通道的输入相加。这意味着池化层的输出和输入的通道数是相等。
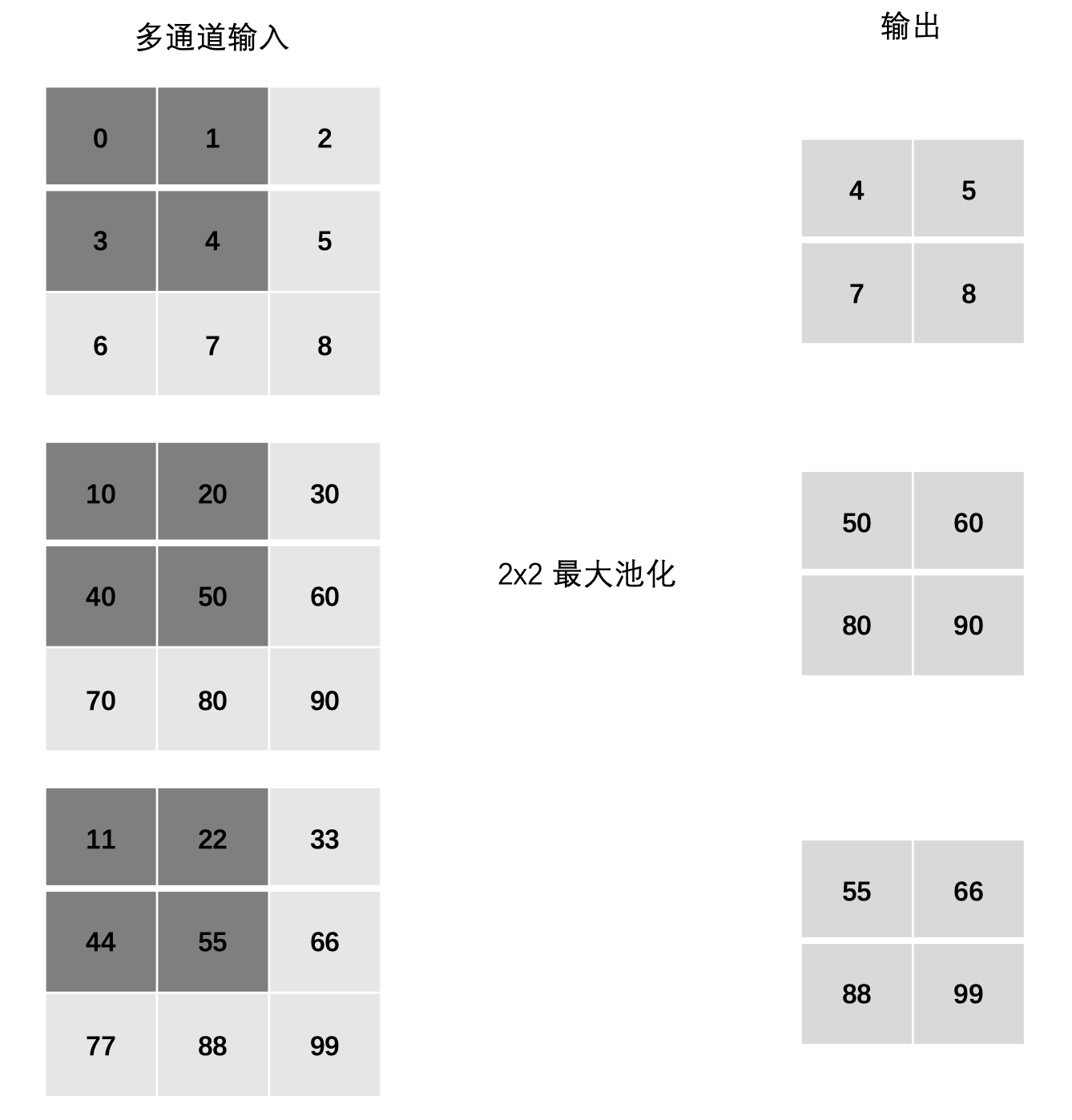
3.6 池化层的作用
池化操作的优势有:
- 通过降低特征图的尺寸,池化层能够减少计算量,从而提升模型的运行效率。
- 池化操作可以带来特征的平移、旋转等不变性,这有助于提高模型对输入数据的鲁棒性。
- 池化层通常是非线性操作,例如最大值池化,这样可以增强网络的表达能力,进一步提升模型的性能。
但是池化也有缺点:
- 池化操作会丢失一些信息,这是它最大的缺点;
3.7 池化API使用
import torch
import torch.nn as nn
# 1. API 基本使用
def test01():
inputs = torch.tensor([[0, 1, 2], [3, 4, 5], [6, 7, 8]]).float()
inputs = inputs.unsqueeze(0).unsqueeze(0)
# 1. 最大池化
# 输入形状: (N, C, H, W)
polling = nn.MaxPool2d(kernel_size=2, stride=1, padding=0)
output = polling(inputs)
print(output)
# 2. 平均池化
polling = nn.AvgPool2d(kernel_size=2, stride=1, padding=0)
output = polling(inputs)
print(output)
# 2. stride 步长
def test02():
inputs = torch.tensor([[0, 1, 2, 3], [4, 5, 6, 7], [8, 9, 10, 11], [12, 13, 14, 15]]).float()
inputs = inputs.unsqueeze(0).unsqueeze(0)
# 1. 最大池化
polling = nn.MaxPool2d(kernel_size=2, stride=2, padding=0)
output = polling(inputs)
print(output)
# 2. 平均池化
polling = nn.AvgPool2d(kernel_size=2, stride=2, padding=0)
output = polling(inputs)
print(output)
# 3. padding 填充
def test03():
inputs = torch.tensor([[0, 1, 2], [3, 4, 5], [6, 7, 8]]).float()
inputs = inputs.unsqueeze(0).unsqueeze(0)
# 1. 最大池化
polling = nn.MaxPool2d(kernel_size=2, stride=1, padding=1)
output = polling(inputs)
print(output)
# 2. 平均池化
polling = nn.AvgPool2d(kernel_size=2, stride=1, padding=1)
output = polling(inputs)
print(output)
# 4. 多通道池化
def test04():
inputs = torch.tensor([[[0, 1, 2], [3, 4, 5], [6, 7, 8]],
[[10, 20, 30], [40, 50, 60], [70, 80, 90]],
[[11, 22, 33], [44, 55, 66], [77, 88, 99]]]).float()
inputs = inputs.unsqueeze(0)
# 最大池化
polling = nn.MaxPool2d(kernel_size=2, stride=1, padding=0)
output = polling(inputs)
print(output)
if __name__ == '__main__':
test04()
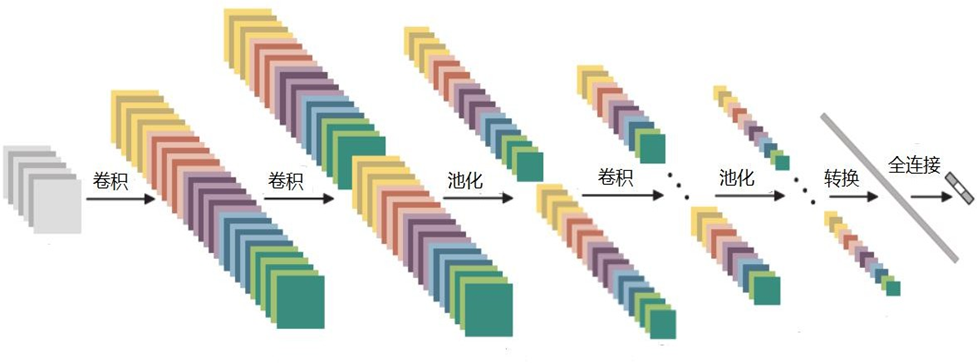
4. 整体结构
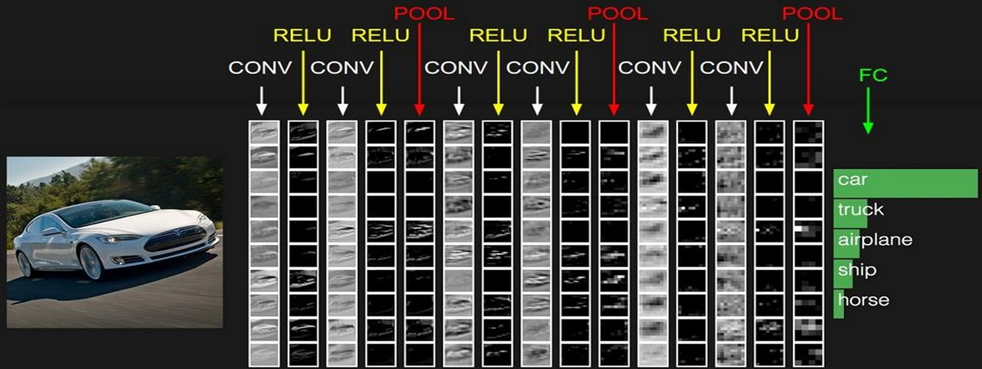
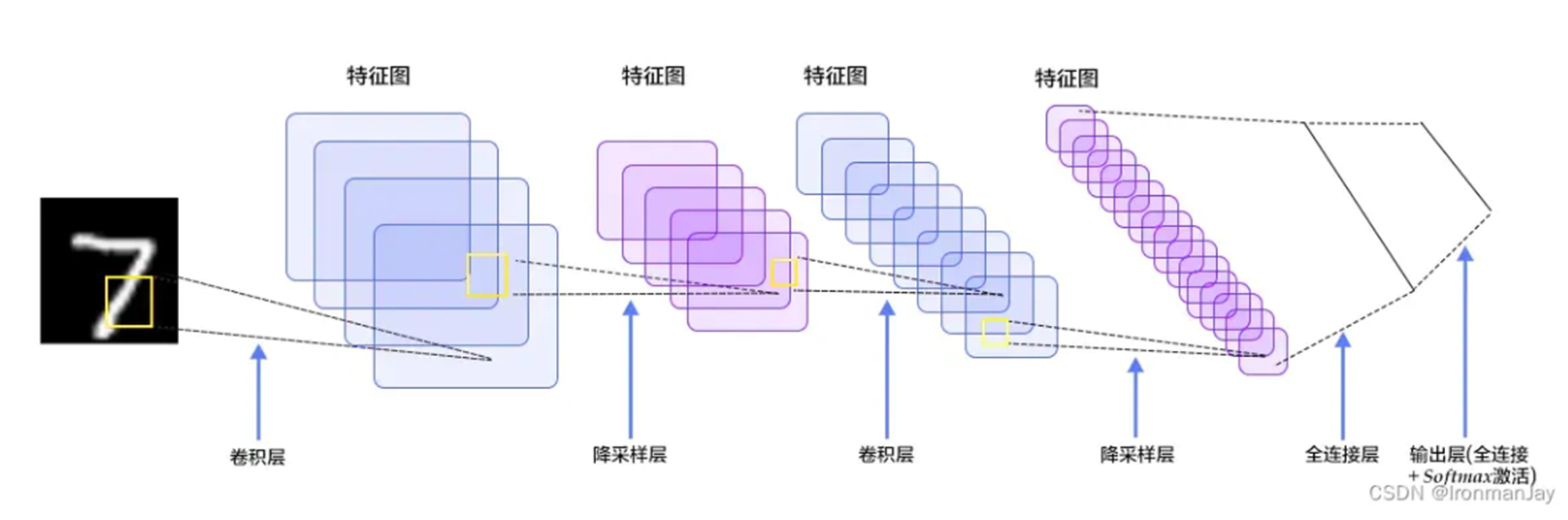
4.1 特征图变化
5. 卷积知识扩展
5.1 卷积结果
卷积实际上将原本图像中的某一特征进行提取。
5.2 二维卷积
分单通道版本和多通道版本。
5.2.1 单通道版本
之前所讲卷积相关内容其实真正意义上叫做二维卷积(单通道卷积版本),即只有一个通道的卷积。
5.2.2 多通道版本
彩色图像拥有R、G、B这三层通道,因此我们在卷积时需要分别针对这三层进行卷积
最后将三个通道的卷积结果进行合并(元素相加,就是在通道上进行特征的一个融合操作),得到卷积结果
5.3 三维卷积
二维卷积是在单通道的一帧图像上进行滑窗操作,输入是高度H宽度W的二维矩阵。
而如果涉及到视频上的连续帧或者立体图像中的不同切片,就需要引入深度通道,此时输入就变为高度H宽度W*深度C的三维矩阵。
不同于二维卷积核只在两个方向上运动,三维卷积的卷积核会在三个方向上运动,因此需要有三个自由度。
这种特性使得三维卷积能够有效地描述3D空间中的对象关系,它在一些应用中具有显著的优势,例如3D对象的分割以及医学图像的重构等。
5.4 反卷积
卷积是对输入图像及进行特征提取,这样会导致尺寸会越变越小,而反卷积是进行相反操作。并不会完全还原到跟输入图一样,只是保证了与输入图像尺寸一致,主要用于向上采样。从数学上看,反卷积相当于是将卷积核转换为稀疏矩阵后进行转置计算。也被称为转置卷积。
5.4.1 反卷积计算过程
如图,在2x2的输入图像上使用【步长1、边界全0填充】的3x3卷积核,进行转置卷积(反卷积)计算,向上采样后输出的图像大小为4x4
如我们的语义分割里面就需要反卷积还原到原始图像大小。
5.5 膨胀卷积
也叫膨胀卷积。为扩大感受野,在卷积核的元素之间插入空格“膨胀”内核,形成空洞卷积,并用膨胀率参数L表示要扩大内核的范围,即在内核元素之间插入L-1个空格。当L=1时,内核元素之间没有插入空格,变为标准卷积。图中是L=2的空洞卷积。
5.6 可分离卷积
5.6.1 空间可分离卷积
空间可分离卷积是将卷积核分解为两项独立的核分别进行操作。在数学中我们可以将矩阵分解:
[
−
1
0
1
−
2
0
2
−
1
0
1
]
=
[
1
2
1
]
×
[
−
1
0
1
]
\left[ \begin{matrix} -1 & 0 & 1 \\ -2 & 0 & 2 \\ -1 & 0 & 1 \end{matrix} \right]= \left[ \begin{matrix} 1 \\ 2 \\ 1 \end{matrix} \right]\times \left[ \begin{matrix} -1 & 0 & 1 \end{matrix} \right]
−1−2−1000121
=
121
×[−101]
所以对3x3的卷积核,我们同样可以拆分成 3x1 和 1x3 的两个卷积核,对其进行卷积,且采用可分离卷积的计算量比标准卷积要少。
5.6.2 深度可分离卷积
深度可分离卷积由两部组成:深度卷积核
1
×
1
1\times1
1×1卷积,我们可以使用Animated AI官网的图来演示这一过程
输入图的每一个通道,我们都使用了对应的卷积核进行卷积。 通道数量 = 卷积核个数,每个卷积核只有一个通道
完成卷积后,对输出内容进行1x1的卷积
5.7 扁平卷积
扁平卷积是将标准卷积拆分成为3个1x1的卷积核,然后再分别对输入层进行卷积计算。
-
标准卷积参数量XYC,计算量为MNCXY
-
拆分卷积参数量(X+Y+C),计算量为MN(C+X+Y)
5.8 分组卷积
2012年,AlexNet论文中最先提出来的概念,当时主要为了解决GPU显存不足问题,将卷积分组放到两个GPU中并行执行。
在分组卷积中,卷积核被分成不同的组,每组负责对相应的输入层进行卷积计算,最后再进行合并。
卷积核被分成两个组,前半部负责处理前半部的输入层,后半部负责后半部的输入层,最后将结果组合。
分组卷积中:
-
输入通道被划分为若干组。
-
每组通道只与对应的卷积核计算。
-
不同组之间互相独立,卷积核不共享。
5.9 混洗分组卷积
分组卷积中最终结果会按照原先的顺序进行合并组合,阻碍了模型在训练时特征信息在通道间流动,削弱了特征表示。混洗分组卷积,主要是将分组卷积后的计算结果混合交叉在一起输出。
6.感受野
6.1 理解感受野
字面意思是感受的视野范围
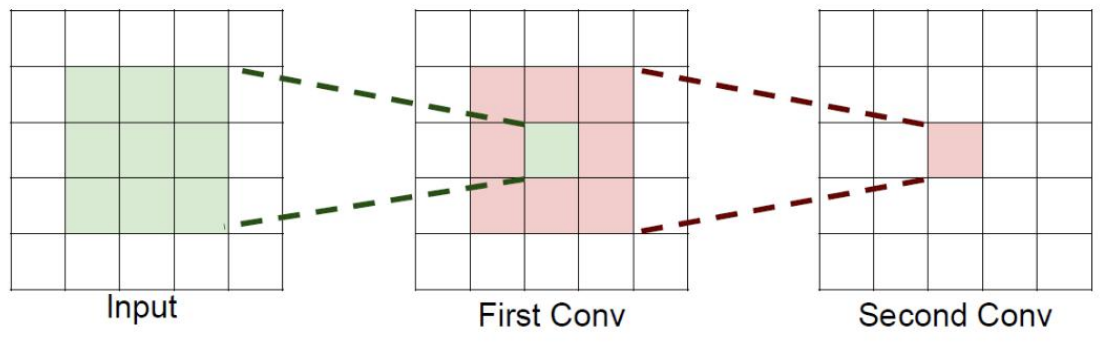
如果堆叠3个3 x 3的卷积层,并且保持滑动窗口步长为1,其感受野就是7×7的了, 这跟一个使用7x7卷积核的结果是一样的,那为什么非要堆叠3个小卷积呢?
6.2 感受野的作用
假设输入大小都是h × w × C,并且都使用C个卷积核(得到C个特征图),可以来计算 一下其各自所需参数
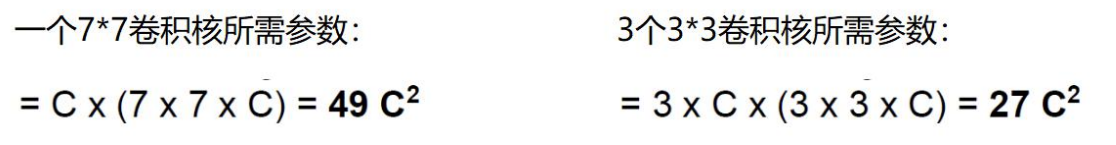
很明显,堆叠小的卷积核所需的参数更少一些,并且卷积过程越多,特征提取也会越细致,加入的非线性变换也随着增多,还不会增大权重参数个数,用小的卷积核来完成体特征提取操作。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









