







思路和代码来自 尚硅谷的spark教程
第一种方法
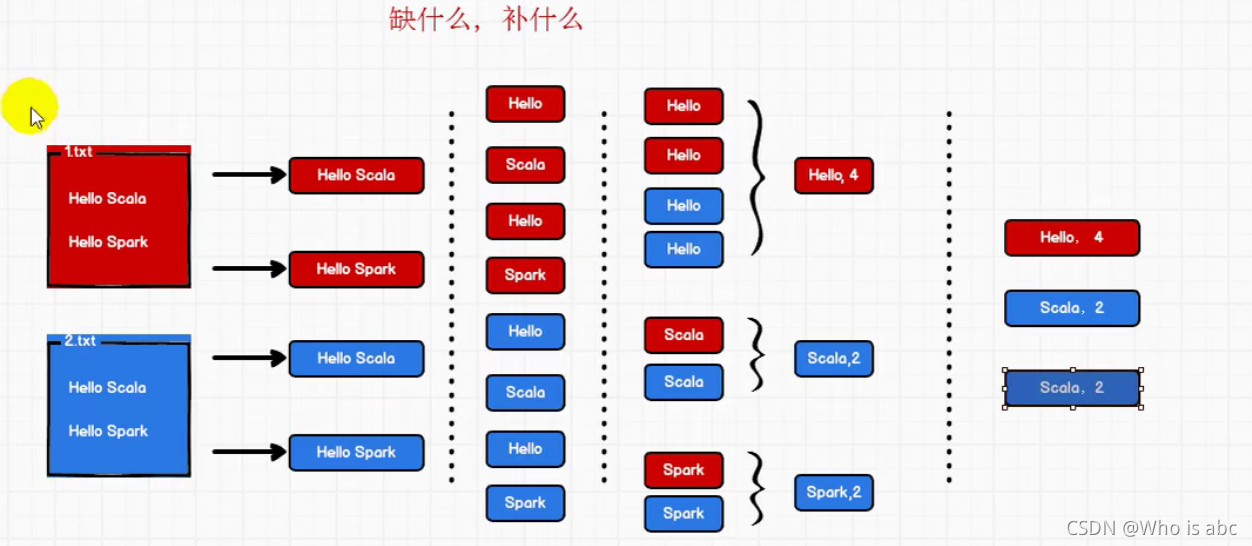
统计单词对应列表的个数
代码
package com.my.bigdata.spark
import org.apache.spark.{SparkConf, SparkContext}
/**
* Description wordCount, 单词统计
*/
object Spark01_WordCount {
def main(args: Array[String]): Unit = {
// Application
// Spark框架
// 1.建立和Spark框架的连接
// JDBC: Connection
val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparkConf)
// 2.执行业务操作
// 2.1 读取文件,获取一行一行的数据
// hello world
val lines = sc.textFile(path = "datas")
println("lines:")
lines.collect().foreach(println)
// 2.2 将一行数据进行拆分,形成一个一个的单词(分词)
// 扁平化
// "hello world" => hello, world, hello, world
val words = lines.flatMap(_.split(" "))
println("words:")
words.collect().foreach(println)
// 2.3 将数据根据单词进行分组,便于统计
// (hello, hello, hello), (word, word)
val wordGroup = words.groupBy(word => word)
println("wordGroup:")
wordGroup.collect().foreach(println)
// 2.4 对分组后的数据进行转换
// (hello, hello, hello), (word, word)
// (hello, 3), (word, 2)
val wordToCount = wordGroup.map {
case (word, list) => {
(word, list.size)
}
}
// 2.5 将转换结果采集到控制台打印出来
println("wordToCount:")
val array = wordToCount.collect()
array.foreach(println)
// 3.关闭连接
sc.stop()
}
}
输出结果:
lines:
Hello World
Hello Spark
Hello World
Hello Spark
words:
Hello
World
Hello
Spark
Hello
World
Hello
Spark
wordGroup:
(Hello,CompactBuffer(Hello, Hello, Hello, Hello))
(World,CompactBuffer(World, World))
(Spark,CompactBuffer(Spark, Spark))
wordToCount:
(Hello,4)
(World,2)
(Spark,2)
第一种方法统计单词个数时,用的是单词列表的size,没有体现聚合的思想
第二种方法
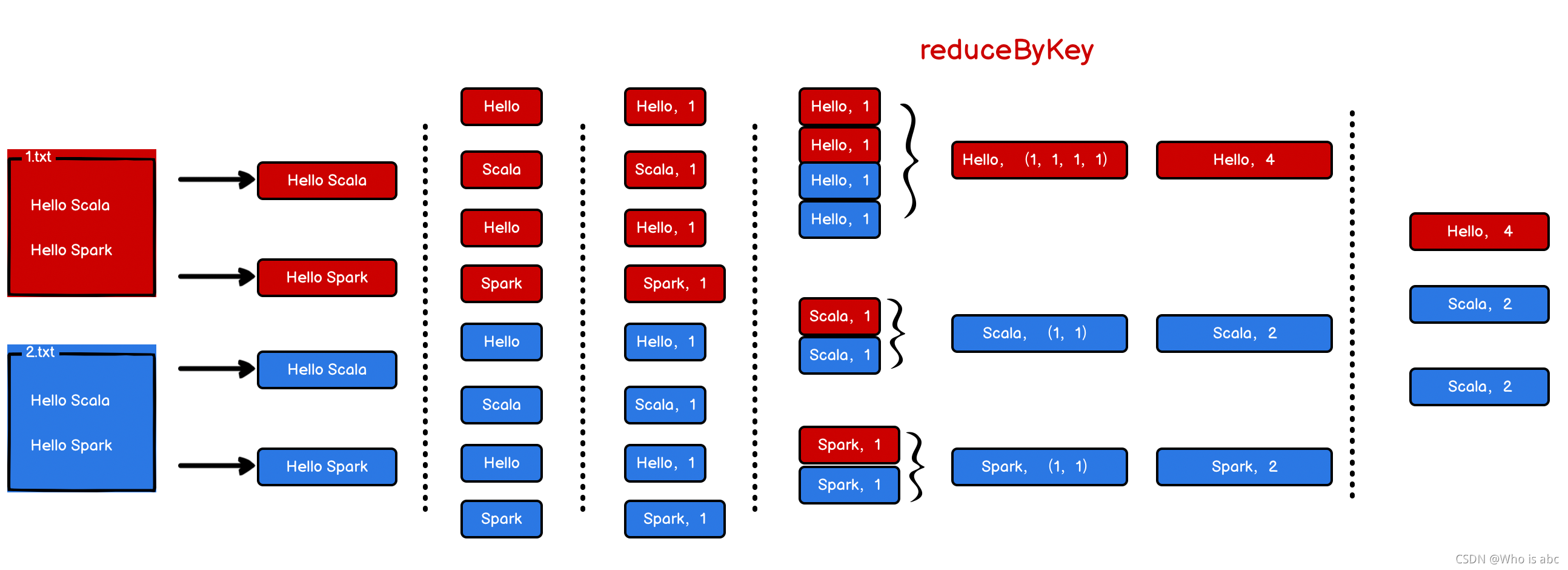
记录单词的次数并聚合
针对每个单词,记录对应的次数,最后对次数进行聚合,改进的地方在代码的2.3和2.4
代码
package com.my.bigdata.spark
import org.apache.spark.{SparkConf, SparkContext}
/**
* Description wordCount, 单词统计
*/
object Spark02_WordCount {
def main(args: Array[String]): Unit = {
// Application
// Spark框架
// 1.建立和Spark框架的连接
// JDBC: Connection
val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparkConf)
// 2.执行业务操作
// 2.1 读取文件,获取一行一行的数据
// hello world
val lines = sc.textFile(path = "datas")
println("lines:")
lines.collect().foreach(println)
// 2.2 将一行数据进行拆分,形成一个一个的单词(分词)
// 扁平化
// "hello world" => hello, world, hello, world
val words = lines.flatMap(_.split(" "))
val wordToOne = words.map(
word => (word, 1)
)
println("words:")
words.collect().foreach(println)
// 2.3 将数据根据单词进行分组,便于统计
// (hello, hello, hello), (word, word)
val wordGroup = wordToOne.groupBy(
t => t._1)
println("wordGroup:")
wordGroup.collect().foreach(println)
// 2.4 对分组后的数据进行转换
// (hello, hello, hello), (word, word)
// (hello, 3), (word, 2)
val wordToCount = wordGroup.map {
case (word, list) => {
list.reduce(
(t1, t2) => {
(t1._1, t1._2 + t2._2)
}
)
}
}
// 2.5 将转换结果采集到控制台打印出来
println("wordToCount:")
val array = wordToCount.collect()
array.foreach(println)
// 3.关闭连接
sc.stop()
}
}
输出结果:
lines:
Hello World
Hello Spark
Hello World
Hello Spark
words:
Hello
World
Hello
Spark
Hello
World
Hello
Spark
wordGroup:
(Hello,CompactBuffer((Hello,1), (Hello,1), (Hello,1), (Hello,1)))
(World,CompactBuffer((World,1), (World,1)))
(Spark,CompactBuffer((Spark,1), (Spark,1)))
wordToCount:
(Hello,4)
(World,2)
(Spark,2)
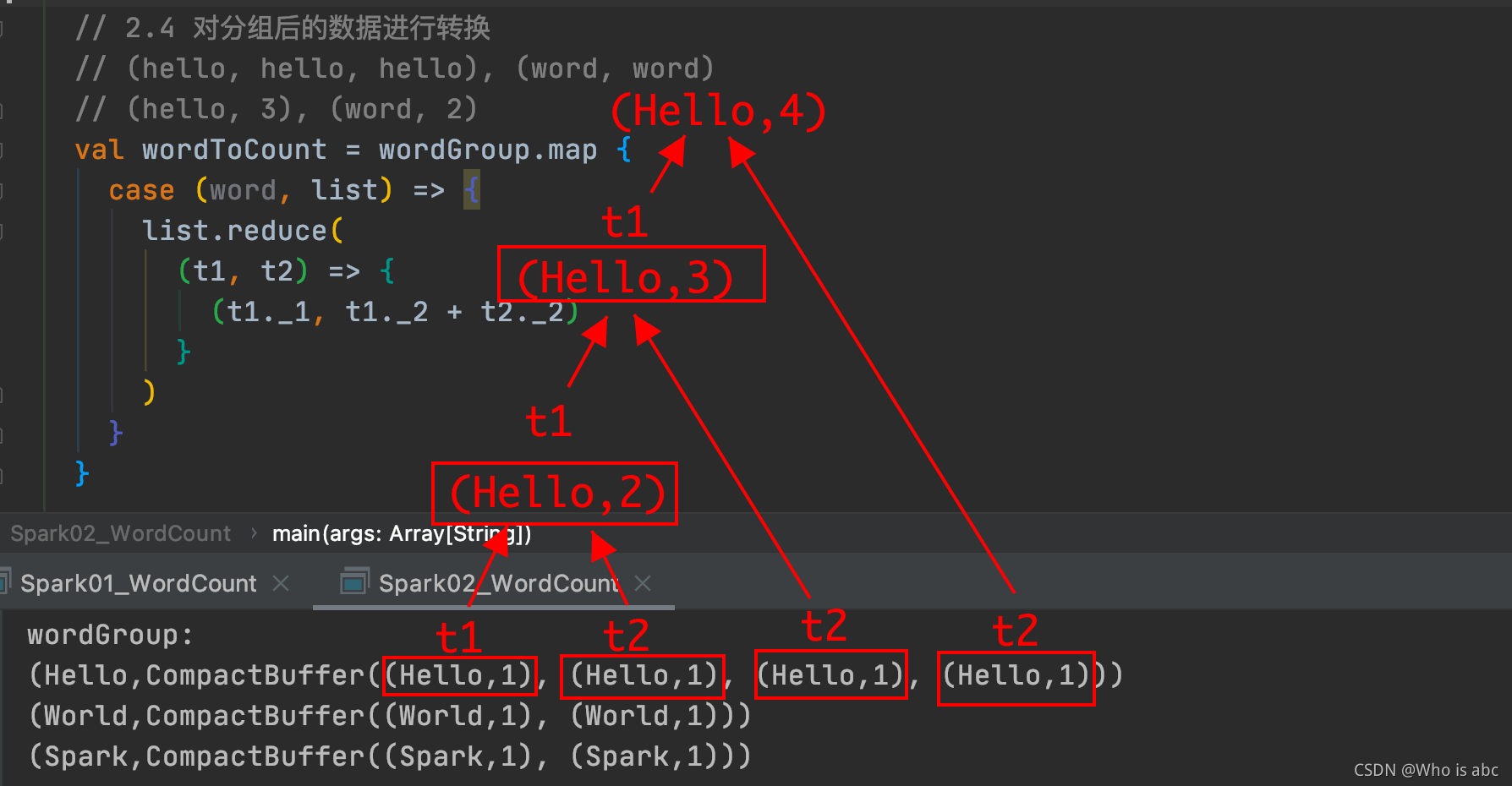
下面对这段代码进行解释:
val wordToCount = wordGroup.map {
case (word, list) => {
list.reduce(
(t1, t2) => {
(t1._1, t1._2 + t2._2)
}
)
}
}
在((Hello, 1), (Hello, 1))中
t1._1 和 t1._2 分别指的是第一个(Hello, 1)的 Hello 和 1
t2._1 和 t2._2 分别指的是第二个(Hello, 1)的 Hello 和 1
第三种方法
spark特有的聚合方法
和第二种方法的区别在于,将2.3和2.4融合成一条语句
代码
package com.my.bigdata.spark
import org.apache.spark.{SparkConf, SparkContext}
/**
* Description wordCount, 单词统计
*/
object Spark03_WordCount {
def main(args: Array[String]): Unit = {
// 1.建立和Spark框架的连接
val sparkConf = new SparkConf().setMaster("local").setAppName("WordCount")
val sc = new SparkContext(sparkConf)
// 2.执行业务操作
// 2.1 读取文件,获取一行一行的数据
// hello world
val lines = sc.textFile(path = "datas")
println("lines:")
lines.collect().foreach(println)
// 2.2 将一行数据进行拆分,形成一个一个的单词(分词)
// 扁平化
// "hello world" => hello, world, hello, world
val words = lines.flatMap(_.split(" "))
val wordToOne = words.map(
word => (word, 1)
)
// Spark框架提供了更多的功能,可以将分组和聚合使用一个方法实现
// reduceByKey: 相同的key的数据,可以对value进行reduce聚合
val wordToCount = wordToOne.reduceByKey(_ + _) // 等同于: wordToOne.reduceByKey((x, y) => { x + y })
println("wordToCount:")
val array = wordToCount.collect()
array.foreach(println)
// 3.关闭连接
sc.stop()
}
}














 505
505











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









