







 本文详细介绍了MapReduce的模型、策略、架构以及工作流程,包括Map和Reduce函数、客户端、JobTracker、TaskTracker的角色。重点阐述了MapReduce的Shuffle过程,包括Map端和Reduce端的详细步骤,以及数据的分区、排序和合并。此外,还讨论了MapReduce在关系的自然连接等实际应用中的用法。
本文详细介绍了MapReduce的模型、策略、架构以及工作流程,包括Map和Reduce函数、客户端、JobTracker、TaskTracker的角色。重点阐述了MapReduce的Shuffle过程,包括Map端和Reduce端的详细步骤,以及数据的分区、排序和合并。此外,还讨论了MapReduce在关系的自然连接等实际应用中的用法。
目录
7.1 MapReduce简介
数据处理能力提升的两条路线:单核CPU到双核四核八核;分布式并行编程。
典型的并行编程框架还有MPI(消息传递接口),OpenCL,CUDA等。
MapReduce与传统并行计算框架对比
MapReduce模型
MapReduce策略
将庞大的数据集,切分成非常多的独立的小分片;为每个分片单独启动一个map任务;最终通过多个map任务,并行地在多个机器上去处理。
MapReduce理念——计算向数据靠拢
传统的计算方法——数据向计算靠拢:要完成一次数据分析,选择一个计算节点,把运行数据分析的程序放到计算节点上运行;然后把涉及到的数据,全部从不同节点上面拉过来,传输到计算发生的地方。
MapReduce——计算向数据靠拢:在集群中选择部分机器作为程序运算的节点,一般选择距离需要处理数据块最近的Map或Reduce机器来进行运算;最终把结果汇总到相关任务协调节点返回。(大大减少了数据传输开销)
MapReduce架构——Master/Slave
一个Master服务器,作业跟踪器JobTracker,负责整个作业的调度和处理以及失败和恢复。
若干个Slave服务器,负责具体任务执行的组件TaskTracker,负责接收JobTracker给它分配的作业处理指令完成具体的任务处理。
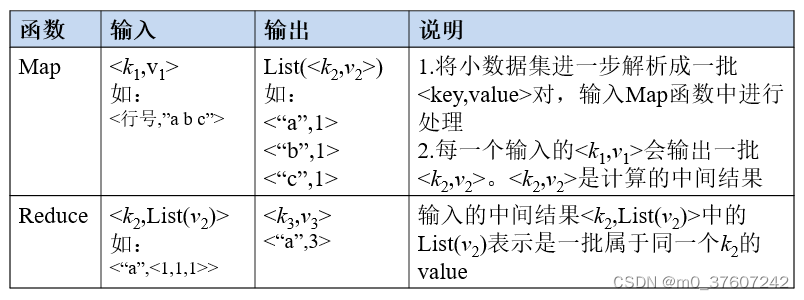
Map函数和Reduce函数
7.2 MapReduce的体系结构
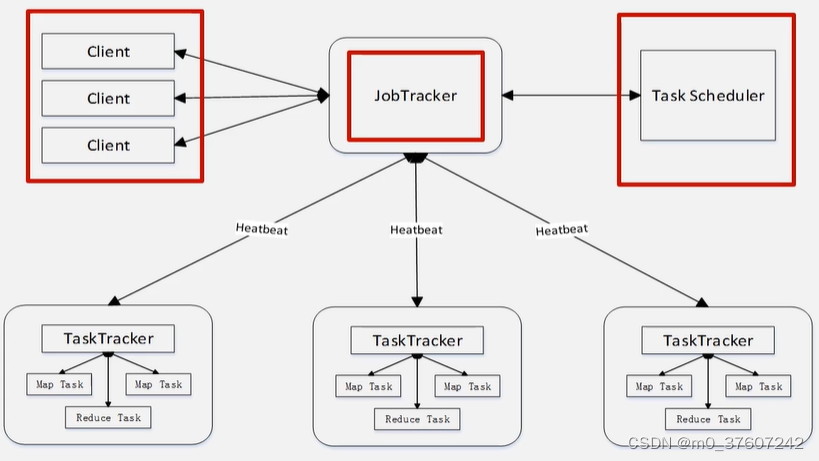
Client客户端
通过Client可以提交用户编写的应用程序,用户通过它将应用程序提交到JobTracker端;通过这些Client用户也可以通过它提供的一些接口去查看当前提交作业的运行状态。
JobTracker作业跟踪器
负责资源的监控和作业的调度;监控底层其他的TaskTracker以及当前Job的健康状况;一旦探测到失败的情况就把这个任务转移到其他节点继续执行;跟踪任务执行进度和资源使用量,并将这些信息告诉任务调度器(TaskScheduler),调度器会在资源出现空闲时,选择合适的任务去使用。(TaskScheduler是可插板模块,允许用户自行编写调度策略)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 5648
5648











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









