







目录
9.1 数据仓库的概念
数据仓库是一个面向主题的、集成的、相对稳定的、反映历史变化的数据集合,用于支撑管理决策。企业基于数据仓库的分析结果来做出相关的经营决策。
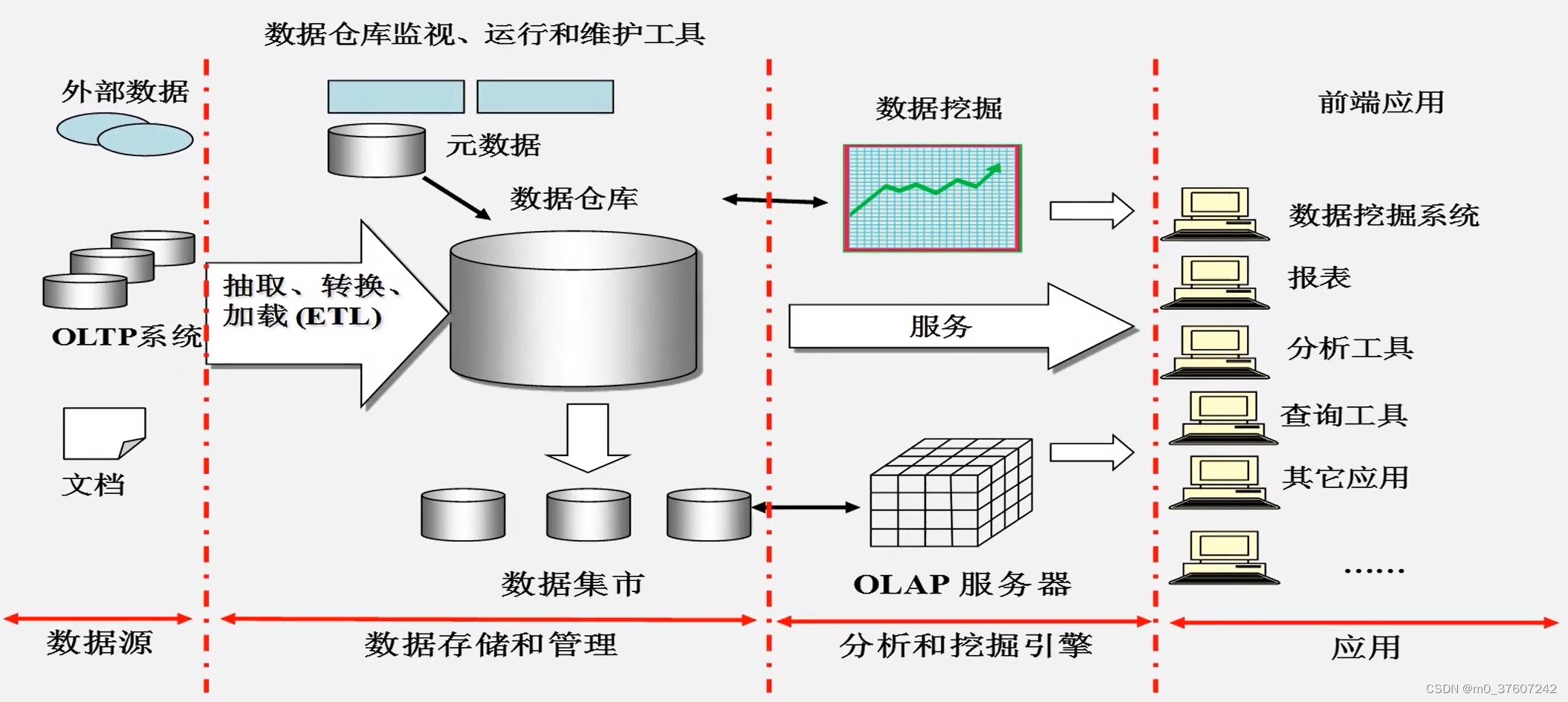
数据仓库和传统数据库相比有个本质的区别:相对稳定。数据仓库当中的数据不会频繁发生变化或者根本不发生变化,数据源当中的数据抽取、转换、加载到数据仓库中后大多数情况下不会发生变更。数据仓库中存储了大量的历史数据。而传统数据库只能保留某一个时刻的状态信息。
传统数据仓库面临的挑战
数据仓库底层借助传统的关系型数据库进行存储。无法满足快速增长的海量数据存储需求;无法有效处理不同类型的数据(只能支持结构化数据);计算和处理能力不足(无法水平拓展,纵向扩展有限)。
9.2 HIVE简介
Hive是一个构建于Hadoop顶层的数据仓库工具。
传统的数据仓库既是数据存储产品也是数据处理分析产品,能同时支持数据的存储和处理分析;但Hive本身不存储和处理数据,某种程度上可以看作是用户编程接口。
依赖分布式文件系统HDFS存储数据;
依赖分布式并行计算模型MapReduce处理数据;
定义了简单的类SQL 查询语言——HiveQL;
用户可以通过编写的HiveQL语句运行MapReduce任务;
是一个可以提供有效、合理、直观组织和使用数据的模型。
Hive适用于数据仓库的特点
采用批处理方式处理海量数据
Hive需要把HiveQL语句转换成MapReduce任务进行运行; 数据仓库存储的是静态数据,对静态数据的分析适合采用批处理方式,不需要快速响应给出结果,而且数据本身也不会频繁变化。
提供适合数据仓库操作的工具
Hive本身提供了一系列对数据进行提取、转化、加载(ETL)的工具,可以存储、查询和分析存储在Hadoop中的大规模数据; 非常适合数据仓库应用程序维护海量数据、对数据进行挖掘、形成意见和报告等。
Hadoop生态系统中Hive与其他部分的关系
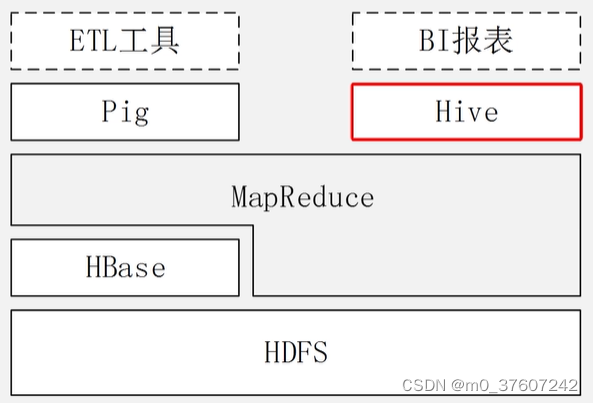
Hive依赖于HDFS存储数据
HDFS作为高可靠性的底层存储,用来存储海量数据。
Hive依赖于MapReduce处理数据
MapReduce对这些海量数据进行处理,实现高性能计算,用HiveQL语句编写的处理逻辑最终均要转化为MapReduce任务来运行。
Pig可以作为Hive的部分替代工具
Pig是一种数据流式语言处理框架,适合用于Hadoop和MapReduce平台查询半结构化数据集。常用于ETL过程的一部分,即将外部数据装载到Hadoop集群中,然后转换为用户期待的数据格式。
Pig与Hive应用场景的区别:Pig属于轻量级分析工具,适合做实时交互式分析,主要用于数据仓库的ETL环节;Hive主要用于数据仓库海量数据的批处理分析。
HBase提供数据的实时访问
HBase一个面向列、分布式、可伸缩的数据库,它可以提供数据的实时访问功能,而Hive只能处理静态数据,主要是BI报表数据,所以HBase与Hive的功能是互补的,它实现了Hive不能提供功能。
Hive与传统数据库的对比分析
Hive在很多方面和传统的关系数据库类似,但是它的底层依赖的是HDFS和MapReduce,所以在很多方面又有别于传统数据库。
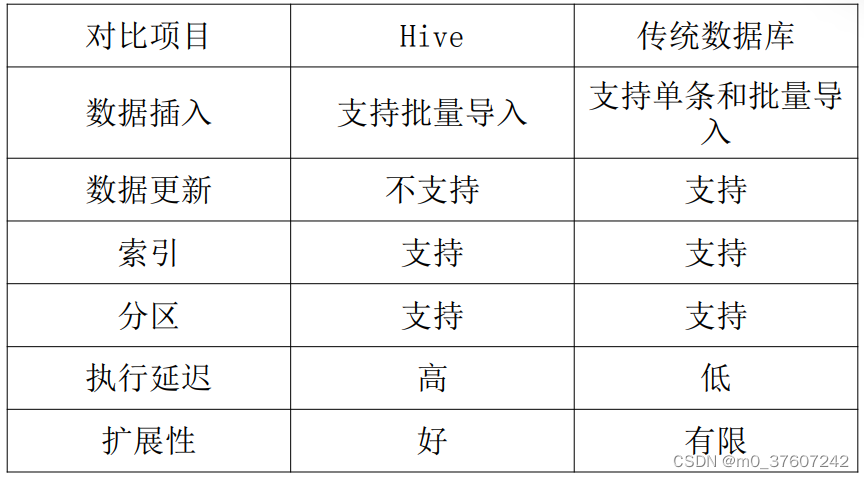
Hive与传统数据库的区别主要体现在以下几个方面:
(1)数据插入:在传统数据库中同时支持导入单条数据和批量数据 ,而Hive中仅支持批量导入数据,因为Hive主要用来支持大规模数据集上的数据仓库应用程序的运行,常见操作是全表扫描,所以单条插入功能对Hive并不实用。
(2)数据更新:更新是传统数据库中很重要的特性,Hive不支持数据更新。Hive是一个数据仓库工具,而数据仓库中存放的是静态数据 ,所以Hive不支持对数据进行更新。
(3)索引:索引也是传统数据库中很重要的特性,Hive在hive 0.7版本后已经可以支持索引了。但Hive不像传统的关系型数据库那样有键的概念,它只提供有限的索引功能,使用户可以在某些列上创建索引来加速一些查询操作,Hive中给一个表创建的索引数据被保存在另外的表中。
(4)分区:传统的数据库提供分区功能来改善大型表以及具有各种访问模式的表的可伸缩性,可管理性和提高数据库效率。Hive也支持分区功能,Hive表组织成分区的形式,根据分区列的值对表进行粗略的划分,使用分区可以加快数据的查询速度。
(5)执行延迟:因为Hive构建于HDFS与MapReduce上,所以对比传统数据库来说Hive的延迟比较高,传统的SQL语句的延迟少于一秒 ,而HiveQL语句的延迟会达到分钟级。
(6)扩展性:传统关系数据库很难横向扩展,纵向扩展的空间也很 有限。相反Hive的开发环境是基于集群的,所以具有较好的可扩展性。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 226
226











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









