







通过前面的学习,已经大致了解了logback的几个重要的功能模块:Logger、Appender、PatternLayout,以及其中涉及到Level、Filter,现在来看一下在一次日志记录当中他们所扮演的角色已经作用的先后顺序。
配置文件(logback.xml)如下
<?xml version="1.0" encoding="UTF-8" ?>
<configuration>
<appender name="STDOUT"
class="ch.qos.logback.core.ConsoleAppender">
<!-- deny all events with a level below DEBUG, that is TRACE and DEBUG -->
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<level>DEBUG</level>
</filter>
<!-- encoders are assigned by default the type
ch.qos.logback.classic.encoder.PatternLayoutEncoder -->
<encoder>
<pattern>
%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n
</pattern>
</encoder>
</appender>
<root level="debug">
<appender-ref ref="STDOUT"/>
</root>
</configuration>
代码如下
package ch.qos.logback.test;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.time.LocalDate;
public class LoggerNameTest {
private static final Logger logger = LoggerFactory.getLogger("chapters.introduction");
public static void main(String[] args) {
logger.debug("今天的日期是{}", LocalDate.now());
}
}
调用debug方法,与其他级别方法只有请求level上的不同,所以公用了filterAndLog_1方法,只是将第三个参数level赋值为Level.DEBUG.
public void debug(String format, Object arg) {
filterAndLog_1(FQCN, null, Level.DEBUG, format, arg, null);
}
以下的步骤主要分为以下6个步骤
1. 获取TurboFilter执行结果
何为TurboFilter呢?全称为ch.qos.logback.classic.turbo.TurboFilter,在前面我们接触过ch.qos.logback.core.filter.Filter,在上面的配置文件当中我们也配置了一个ThresholdFilter,那么这两个Filter有啥关系吗?首先对比一下两个类的定义

经过一对比,发现二者基本是一样的,除了其中的decide方法传入的参数不一致。正是传入参数的不同决定了二人的不同之处。分析不同之处,还是首先分析这个方法的相同之处。两个decide方法的返回参数都是ch.qos.logback.core.spi.FilterReply类型,而这个类是一个枚举类,只有三个值。
public enum FilterReply {
/**
* 拒绝
*/
DENY,
/**
* 中立
*/
NEUTRAL,
/**
* 允许
*/
ACCEPT;
}
所谓的decide方法就是决定当前的流程要不要继续下行进行,区别于传统的true or false,这里在DENY(拒绝)和ACCEPT(允许)之间有一个中间状态(NEUTRAL)(中立),如果是拒绝状态则不需要继续执行,如果是中立状态,则可以考虑下一个过滤器,如果是允许状态,取决于外面的调用,可以直接通过。当然具体还是取决于外面的具体逻辑,比如用户可以按照一半以上不拒绝就通过的策略或者一半以上允许才通过的策略进行各种策略选择。总之,这个中立状态是一个亮点,就像投票一样,可以反对,可以赞同,也可以弃权。以上两个过滤器最主要的功能就取决于这个decide方法。接下来我们分析一下这两个方法的不同之处,
ch.qos.logback.classic.turbo.TurboFilter#decide方法接收的参数为Logger、Level、format和params这些,而ch.qos.logback.core.filter.Filter#decide方法接收的参数为E(未知类型)。从这里能看出,后者可能更通用一点,毕竟未知类型可以完全按照用户的想法而使用。从官方注释来看,TurboFilter 是一个特殊的Filter,它有一个决定方法,它接受一堆参数而不是单个事件对象。 后者更干净,但第一个性能更高。所以二者倒并没有本质差别。不过在logback当中,二者使用的地方不一样决定了二者的差别。
首先TurboFilter在用户执行logger请求的一开始就执行了,所以说TurboFilter的优先级是更高的,其次在logback-classic当中这个未知类型其实是已知的ILoggingEvent。
好了,以上分析完了TurboFilter与Filter的相同与不同之处,想必TurboFilter有什么用不需要继续介绍了。接下来继续分析获取TurboFilter执行结果的流程。
// 1. Get the filter chain decision
final FilterReply decision = loggerContext.getTurboFilterChainDecision_1(marker, this, level, msg, param, t);
从LoggerContext对象中获取TurboFilter过滤器链并获取投票结果。
private final TurboFilterList turboFilterList = new TurboFilterList();
final FilterReply getTurboFilterChainDecision_1(final Marker marker, final Logger logger, final Level level, final String format, final Object param,
final Throwable t) {
if (turboFilterList.size() == 0) {
return FilterReply.NEUTRAL;
}
return turboFilterList.getTurboFilterChainDecision(marker, logger, level, format, new Object[] { param }, t);
}
如果用户没有定义TurboFilter,那么返回中立态度。否则遍历turboFilterList获取结果,在这里TurboFilterList继承了CopyOnWriteArrayList,是一个线程安全的列表实现,因为这里是典型的读多写少的场景,使用CopyOnWriteArrayList就够了。
final public class TurboFilterList extends CopyOnWriteArrayList<TurboFilter>
如果其中的元素个数不为0,则会遍历其中的TurboFilter获取结果。
Object[] tfa = toArray();
final int len = tfa.length;
for (int i = 0; i < len; i++) {
// for (TurboFilter tf : this) {
final TurboFilter tf = (TurboFilter) tfa[i];
final FilterReply r = tf.decide(marker, logger, level, format, params, t);
if (r == FilterReply.DENY || r == FilterReply.ACCEPT) {
return r;
}
}
return FilterReply.NEUTRAL;
此处的逻辑是依次遍历,遇到一个允许或者拒绝都返回,如果是中立就继续遍历。所有都中立,就返回中立。所以说这里的TurboFilter添加到列表中的先后顺序很重要,因为在列表前面具有一票赞成和一票反对权。
2. 引用基本选择规则
// 2. Apply the basic selection rule
if (decision == FilterReply.NEUTRAL) {
if (effectiveLevelInt > level.levelInt) {
return;
}
} else if (decision == FilterReply.DENY) {
return;
}
这里的逻辑比较简单,首先如果上一步的返回结果为拒绝,那么当前请求就返回了,不需要继续进行了。如果上一次返回为中立,此时就需要将请求的级别与当前logger的有效级别进行比较决定是否通过,这个在前面已经介绍过了,不深入探讨。
这里逻辑还是很简单的,就是有一个点需要注意,就是在上面的TurboFilter的投票结果中如果是ACCEPT的话,这里logger的有效级别就不再起效了。感觉有点怪怪的,好像给用户更多的选择权,但是有点打破整体规则的意思。
3. 创建LoggingEvent对象
如果以上两个步骤都通过的话,接下来会针对请求参数进行封装。
// 3. Create a LoggingEvent object
LoggingEvent le = new LoggingEvent(localFQCN, this, level, msg, t, params);
le.setMarker(marker);
如果请求在前面的过滤器中幸存下来,logback 将创建一个 ch.qos.logback.classic.LoggingEvent 对象,其中包含请求的所有相关参数,例如请求的记录器、请求级别、消息本身、异常、当前时间、当前线程、有关发出日志记录请求的类和 MDC 的各种数据一起传递。 请注意,其中一些字段是延迟初始化的,仅在实际需要时才初始化。 MDC 用于使用附加上下文信息来修饰日志记录请求。 MDC 将在后续章节中讨论。
public LoggingEvent(String fqcn, Logger logger, Level level, String message, Throwable throwable, Object[] argArray) {
this.fqnOfLoggerClass = fqcn;
this.loggerName = logger.getName();
this.loggerContext = logger.getLoggerContext();
this.loggerContextVO = loggerContext.getLoggerContextRemoteView();
this.level = level;
this.message = message;
this.argumentArray = argArray;
if (throwable == null) {
throwable = extractThrowableAnRearrangeArguments(argArray);
}
if (throwable != null) {
this.throwableProxy = new ThrowableProxy(throwable);
LoggerContext lc = logger.getLoggerContext();
if (lc.isPackagingDataEnabled()) {
this.throwableProxy.calculatePackagingData();
}
}
timeStamp = System.currentTimeMillis();
}
4. 调用Appender
创建完LoggingEvent对象之后,logback将会调用当前logger的callAppenders方法,其实就是从当前logger按照名称继承结构依次调用ch.qos.logback.classic.Logger#appendLoopOnAppenders方法(当然了,某个logger的additive属性设置为false,则停止)。
/**
* Invoke all the appenders of this logger.
*
* @param event
* The event to log
*/
public void callAppenders(ILoggingEvent event) {
int writes = 0;
for (Logger l = this; l != null; l = l.parent) {
writes += l.appendLoopOnAppenders(event);
if (!l.additive) {
break;
}
}
// No appenders in hierarchy
if (writes == 0) {
loggerContext.noAppenderDefinedWarning(this);
}
}
主要的逻辑在appendLoopOnAppenders方法当中
transient private AppenderAttachableImpl<ILoggingEvent> aai;
private int appendLoopOnAppenders(ILoggingEvent event) {
if (aai != null) {
return aai.appendLoopOnAppenders(event);
} else {
return 0;
}
}
这里的aai属性类型为AppenderAttachableImpl,其中通过appenderList属性存放了通过addAppender方法添加的Appender。
/**
* Attach an appender. If the appender is already in the list in won't be
* added again.
*/
public void addAppender(Appender<E> newAppender) {
if (newAppender == null) {
throw new IllegalArgumentException("Null argument disallowed");
}
appenderList.addIfAbsent(newAppender);
}
而这行这个属性的appendLoopOnAppenders方法无非就是遍历appenderList依次调用doAppend方法。
/**
* Call the <code>doAppend</code> method on all attached appenders.
*/
public int appendLoopOnAppenders(E e) {
int size = 0;
final Appender<E>[] appenderArray = appenderList.asTypedArray();
final int len = appenderArray.length;
for (int i = 0; i < len; i++) {// 遍历每一个Appender执行日志操作
appenderArray[i].doAppend(e);
size++;
}
return size;
}
这里的逻辑并不复杂,主要是从源码更深入理解前面关于Appender的继承(并非一个列表存放自己的Appender和所有能继承的Appender,而是依次遍历自己与祖先logger以及其Appender列表)。其次,一个logger支持多个Appender,在正常执行的时候是互不影响的,但是如果其中有一个执行异常了,后续的Appender其实是不能正常作用的,这里是单线程在循环调用的,所以就需要理解自己的Appender与继承的Appender之间的优先级关系,从上面源码不难得出结论:Appender优先级是取决于继承关系上的亲疏的,自己的优先级最高,其次父亲,再其次父亲的父亲,随着深度增加越来越低。在介绍每个Appender遍历之前,先看下如果当前logger没有一个Appender会怎么样。
// No appenders in hierarchy
if (writes == 0) {
loggerContext.noAppenderDefinedWarning(this);
}
如果没有任何的Appender,在第一次(注意只有第一次使用时)会向StatusManager中添加日志信息。
final void noAppenderDefinedWarning(final Logger logger) {
if (noAppenderWarning++ == 0) {
getStatusManager().add(new WarnStatus("No appenders present in context [" + getName() + "] for logger [" + logger.getName() + "].", logger));
}
}
以上添加的这条信息可以通过StatusPrinter进行打印(在前面已经介绍过了)。
接下来继续谈谈Appender的执行逻辑。官方文档中介绍logback本身附带的几乎所有Appender都扩展了AppenderBase 抽象类,该抽象类在同步块中实现了 doAppend 方法,以确保线程安全。
/**
* The guard prevents an appender from repeatedly calling its own doAppend
* method.
*/
private boolean guard = false;
public synchronized void doAppend(E eventObject) {
// WARNING: The guard check MUST be the first statement in the
// doAppend() method.
// prevent re-entry.
if (guard) {
return;
}
try {
guard = true;
if (!this.started) {
if (statusRepeatCount++ < ALLOWED_REPEATS) {
addStatus(new WarnStatus("Attempted to append to non started appender [" + name + "].", this));
}
return;
}
if (getFilterChainDecision(eventObject) == FilterReply.DENY) {
return;
}
// ok, we now invoke derived class' implementation of append
this.append(eventObject);
} catch (Exception e) {
if (exceptionCount++ < ALLOWED_REPEATS) {
addError("Appender [" + name + "] failed to append.", e);
}
} finally {
guard = false;
}
}
但是仔细分析源码发现其实并非如此

有绝大多数的Appender(比如我们用过的ConsoleAppender和RollingFileAppender)都是继承的UnsynchronizedAppenderBase,与上面的AppenderBase有啥区别呢?首先doAppend方法没有加synchronized关键字,其次guard定义不一样。
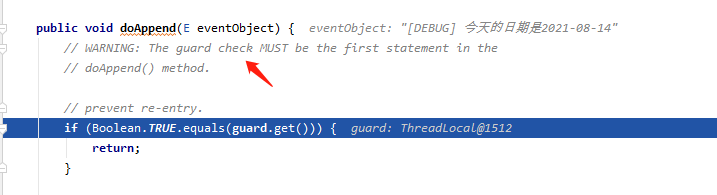
// using a ThreadLocal instead of a boolean add 75 nanoseconds per
// doAppend invocation. This is tolerable as doAppend takes at least a few microseconds
// on a real appender
/**
* The guard prevents an appender from repeatedly calling its own doAppend
* method.
*/
private ThreadLocal<Boolean> guard = new ThreadLocal<Boolean>();
之所以这里要考虑同步问题,其实还是与logger继承结构有关系,子logger与父logger可能同时使用相同的Appender调用doAppend方法。是否需要同步其实是取决于doAppend的对象的,对于控制台和日志文件,可以同时多个文件同时一起操作的,所以这里使用了UnsynchronizedAppenderBase.
执行了不同的同步逻辑之后,接下来的逻辑是一样的,首先是getFilterChainDecision获取用户自定义的Filter构成的过滤器链的投票结果,如果结果为拒绝,则返回,不继续日志打印。这里的逻辑与前面的TurboFilter基本一摸一样,不继续介绍。
经过以上的步骤,终于可以执行真正的append操作了。而这个append操作又是取决于每个Appender的不同实现。本次仅仅分析一下ConsoleAppender的主要逻辑。ConsoleAppender继承了OutputStreamAppender,所以真实执行的是ch.qos.logback.core.OutputStreamAppender#append方法。
@Override
protected void append(E eventObject) {
if (!isStarted()) {
return;
}
subAppend(eventObject);
}
/**
* Actual writing occurs here.
* <p>
* Most subclasses of <code>WriterAppender</code> will need to override this
* method.
*
* @since 0.9.0
*/
protected void subAppend(E event) {
if (!isStarted()) {
return;
}
try {
// this step avoids LBCLASSIC-139
if (event instanceof DeferredProcessingAware) {
((DeferredProcessingAware) event).prepareForDeferredProcessing();
}
// the synchronization prevents the OutputStream from being closed while we
// are writing. It also prevents multiple threads from entering the same
// converter. Converters assume that they are in a synchronized block.
// lock.lock();
// 执行编码 5. Formatting the output
byte[] byteArray = this.encoder.encode(event);
writeBytes(byteArray);
} catch (IOException ioe) {
// as soon as an exception occurs, move to non-started state
// and add a single ErrorStatus to the SM.
this.started = false;
addStatus(new ErrorStatus("IO failure in appender", this, ioe));
}
}
首先是执行消息对象(LoggingEvent实现了ILoggingEvent接口,而后者继承了DeferredProcessingAware接口)的prepareForDeferredProcessing,在这个方法中开始进行参数拼接(性能优化)和线程名称等获取。
/**
* This method should be called prior to serializing an event. It should also
* be called when using asynchronous or deferred logging.
* <p/>
* <p/>
* Note that due to performance concerns, this method does NOT extract caller
* data. It is the responsibility of the caller to extract caller information.
*/
public void prepareForDeferredProcessing() {
this.getFormattedMessage();
this.getThreadName();
// fixes http://jira.qos.ch/browse/LBCLASSIC-104
this.getMDCPropertyMap();
}
接下来通过encoder将日志事件序列化为字节数组,然后通过writeBytes方法处理,
5. 格式化输出
被调用的appender 负责格式化日志事件。 但是,一些(但不是全部)appender 将格式化日志事件的任务委托给布局。 布局格式化 LoggingEvent 实例并将结果作为字符串返回。
请注意,某些 appender,例如 SocketAppender,不会将日志记录事件转换为字符串,而是将其序列化。 因此,它们没有也不需要布局。
在当前的配置情况下,由于ConsoleAppender使用的是ch.qos.logback.classic.encoder.PatternLayoutEncoder
byte[] byteArray = this.encoder.encode(event);
执行这个encode方法其实是将事件代理给layout执行获取日志信息,而encoder只是负责将结果转为字节数组。
public byte[] encode(E event) {
String txt = layout.doLayout(event);
return convertToBytes(txt);
}

那么ch.qos.logback.classic.PatternLayout呢?因为要根据设置的格式转换字符串,比如上面设置的为%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n,这里涉及到时间、线程、级别、logger本身以及真实日志信息。这里面很多其实都是公用的,只是取决于用户是否需要。在logback当中用户将这个抽象为ch.qos.logback.core.pattern.Converter。不同的Converter实现处理不同的逻辑。比如ch.qos.logback.classic.pattern.DateConverter转换逻辑就是通过缓存的SimpleDateFormat格式化事件中的时间戳(这个时间戳是在创建LoggerEvent对象时设置的)
public String convert(ILoggingEvent le) {
long timestamp = le.getTimeStamp();
return cachingDateFormatter.format(timestamp);
}

再比如ThreadConverter,也是简单的获取线程名称返回

PatternLayout通过遍历Converter,执行Converter的write方法,而write方法本质上又是调用convert方法,只不过额外将结果拼接到StringBuilder当中。
static final int INTIAL_STRING_BUILDER_SIZE = 256;
public String doLayout(ILoggingEvent event) {
if (!isStarted()) {
return CoreConstants.EMPTY_STRING;
}
return writeLoopOnConverters(event);
}
protected String writeLoopOnConverters(E event) {
StringBuilder strBuilder = new StringBuilder(INTIAL_STRING_BUILDER_SIZE);
Converter<E> c = head;
while (c != null) {
c.write(strBuilder, event);
c = c.getNext();
}
return strBuilder.toString();
}
以上的逻辑并不难,这里的难点或者说亮点是在另外两个方法,第一个,logback是如何将%d{HH:mm:ss.SSS} [%thread] %-5level %logger{36} - %msg%n转换为一系列的Converter的,第二个,在PatternLayout当中并没有所谓的Converter列表。
其实ch.qos.logback.core.encoder.Encoder实现了LifeCycle接口。PatternLayoutEncoder在系统执行生命周期方法的时候会创建PatternLayout对象,并设置一些重要的参数(其中就包含有pattern)。
public void start() {
PatternLayout patternLayout = new PatternLayout();
patternLayout.setContext(context);
patternLayout.setPattern(getPattern());
patternLayout.setOutputPatternAsHeader(outputPatternAsHeader);
patternLayout.start();
this.layout = patternLayout;
super.start();
}
PatternLayout类初始化就设置一堆的pattern关键字与Converter类名称的映射关系,比如d和date都映射DateConverter。足足有60多个。

执行PatternLayout的start方法,在这个方法当中,就会根据pattern从上面的defaultConverterMap查找Converter(并不是直接,中间还有一个转换effectiveConverterMap),并
public void start() {
if (pattern == null || pattern.length() == 0) {
addError("Empty or null pattern.");
return;
}
try {
Parser<E> p = new Parser<E>(pattern);
if (getContext() != null) {
p.setContext(getContext());
}
Node t = p.parse();
this.head = p.compile(t, getEffectiveConverterMap());
if (postCompileProcessor != null) {
postCompileProcessor.process(context, head);
}
ConverterUtil.setContextForConverters(getContext(), head);
ConverterUtil.startConverters(this.head);
super.start();
} catch (ScanException sce) {
StatusManager sm = getContext().getStatusManager();
sm.add(new ErrorStatus("Failed to parse pattern \"" + getPattern() + "\".", this, sce));
}
}
通过Parser将pattern转为一个token列表

然后通过parse方法更是构造成了一个类型为SimpleKeywordNode的链表

结合关键字与Converter的映射和SimpleKeywordNode通过Parser获取头节点Converter(这个头节点链接下一个Converter,单向链表结构,与SimpleKeywordNode一致)。

接下来还会从head节点执行上面Converter的初始化(所有的DynamicConverter实现了LifeCycle接口),比如%d{HH:mm:ss.SSS}中的d对应DateConverter,而后面的{HH:mm:ss.SSS}则需要在对应的Converter中进行处理。这里涉及到日期格式以及时区的设置。源码如下
public void start() {
String datePattern = getFirstOption();
if (datePattern == null) {
datePattern = CoreConstants.ISO8601_PATTERN;
}
if (datePattern.equals(CoreConstants.ISO8601_STR)) {
datePattern = CoreConstants.ISO8601_PATTERN;
}
try {
cachingDateFormatter = new CachingDateFormatter(datePattern);
// maximumCacheValidity =
// CachedDateFormat.getMaximumCacheValidity(pattern);
} catch (IllegalArgumentException e) {
addWarn("Could not instantiate SimpleDateFormat with pattern " + datePattern, e);
// default to the ISO8601 format
cachingDateFormatter = new CachingDateFormatter(CoreConstants.ISO8601_PATTERN);
}
List<String> optionList = getOptionList();
// if the option list contains a TZ option, then set it.
if (optionList != null && optionList.size() > 1) {
TimeZone tz = TimeZone.getTimeZone((String) optionList.get(1));
cachingDateFormatter.setTimeZone(tz);
}
}
通过以上的分析,在PatternLayoutEncoder的工作逻辑应该是清晰了。
6. 发送日志事件
private void writeBytes(byte[] byteArray) throws IOException {
if(byteArray == null || byteArray.length == 0)
return;
lock.lock();
try {
this.outputStream.write(byteArray);
if (immediateFlush) {
this.outputStream.flush();
}
} finally {
lock.unlock();
}
}
这里的outputStream是什么呢?不同的子类实现不同,比如在ch.qos.logback.core.ConsoleAppender当中
protected ConsoleTarget target = ConsoleTarget.SystemOut;
@Override
public void start() {
OutputStream targetStream = target.getStream();
// enable jansi only on Windows and only if withJansi set to true
if (EnvUtil.isWindows() && withJansi) {
targetStream = getTargetStreamForWindows(targetStream);
}
setOutputStream(targetStream);
super.start();
}
在这里不难看出最后是通过System.out来操作的(具体参考ConsoleTarget类,对System.out的代理)。整理一下上面的逻辑,通过appender的encoder将日志事件转变为字节流,然后通过System.out进行输出操作。

















 4383
4383











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











