







一、什么是短网址?
我们的URL地址常常会因为需要携带各式各样的参数,或者随着业务增长,变得越来越长。对于用户而言,过长的链接体验必然是不好的。这时候短网址就应用而生了,也称为短链接。
短网址,就是把普通网址,就是将长的URL网址,通过程序计算等方式,转换成比较短的网址。比如:http://t.cn/RlB2PdD 这种,在短信、微博、推特这种限制字数的应用里,好处不言而喻。短、字符少、美观、便于发布、传播。
早期短链接广泛应用于图片上传网站,通过缩短网址URL链接字数,达到减少代码字符串的目的。更便于使用者引用网址,写入代码中,节省字符数空间。常见于网店图片分类的使用,因有字符限制,运用短链接,达到外链图片的目的,自微博盛行以来,在微博字数有限的特色下,短链接也盛行于微博网站,以节省字数,给博主发布更多文字的空间。
短网址主要有几个作用:
- 缩短原链接长度,便于营销推广
- 数据统计,在重定向的过程中进行PV、UV等数据统计
- 屏蔽原链接域名
百度短网址 http://dwz.cn/
谷歌短网址服务 https://goo.gl/ (需科学上网)号称是最快的 ?
二、短网址的实现原理解析
当我们在浏览器里输入 http://t.cn/RlB2PdD 时
- DNS首先解析获得 http://t.cn 的
IP地址 - 当
DNS获得IP地址以后(比如:74.125.225.72),会向这个地址发送HTTPGET请求,查询短码RlB2PdD - http://t.cn 服务器会通过短码
RlB2PdD获取对应的长 URL - 请求通过
HTTP301转到对应的长 URL https://m.helijia.com 。
这里有个小的知识点,为什么要用 302 跳转而不是 301 呢?
301是永久重定向,302是临时重定向。短地址一经生成就不会变化,所以用301是符合http语义的。但是如果用了301, Google,百度等搜索引擎,搜索的时候会直接展示真实地址,那我们就无法统计到短地址被点击的次数了,也无法收集用户的Cookie, User Agent 等信息,这些信息可以用来做很多有意思的大数据分析,也是短网址服务商的主要盈利来源。
所以选择302虽然会增加服务器压力,但是我想是一个更好的选择。
通过上面的分析,会发现我们的核心问题就是如何用长网址来生成对应的短网址。
三、短网址的长度设计
我们的需求是生成短网址,当然是尽可能地短,那到底什么样的长度合适呢?
短码一般是由 [a - z, A - Z, 0 - 9] 这62 个字母或数字组成,我们可以把短网址的字符串理解为一个62进制的数(想想16进制你就明白了),微博的短网址是7位,那么最大能表示{62}^7=3521614606208个网址,这是多少呢?可以说比现在互联网所有的链接都都多了好多数量级,这样就避免了短网址重复的问题。
现代的web服务器(例如Apache, Nginx)大部分都区分URL里的大小写,所以用大小写字母来区分不同的URL是没问题的。因此,正确答案:长度不超过7的字符串,由大小写字母加数字共62个字母组成。
四、短网址的生成算法
现在我们设定了短网址是一个长度为7的字符串,如何计算得到这个短网址呢?
两种算法:
- 自增序列算法:设置 id 自增,一个 10进制 id 对应一个 62进制的数值,1对1,也就不会出现重复的情况。这个利用的就是低进制转化为高进制时,字符数会减少的特性。
- 哈希算法:先hash得到一个64位整数,将它转化为62进制整数,截取低7位即可。
但是哈希算法会有冲突,所以我们应该使用第一种方式来实现。10进制转成62进制的具体实现:
function string10to62(number) {
const chars = '0123456789abcdefghigklmnopqrstuvwxyzABCDEFGHIGKLMNOPQRSTUVWXYZ';
const charsArr = chars.split('');
const radix = chars.length;
let qutient = +number;
let arr = [];
do{
let mod = qutient % radix;
qutient = (qutient - mod) / radix;
arr.unshift(charsArr[mod]);
}while(qutient);
return arr.join('');
}但是短码 id 是从一位长度开始递增,短码的长度不固定,不过可以用 id 从指定的数字开始递增的方式来处理,确保所有的短码长度都一致。同时,生成的短码是有序的,可能会有安全的问题,可以将生成的短码id,结合长网址等其他关键字,进行md5运算生成最后的短码。
五、具体的实现流程图
实现流程图如下:
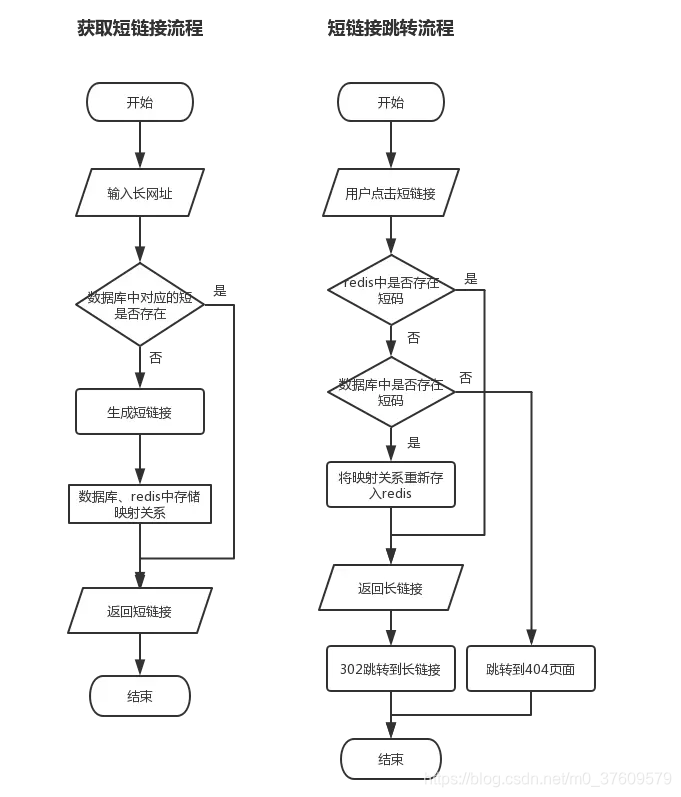
六、扩展
前面我们使用的是一个自增序列来实现id的不重复,但对于高并发环境下,自增序列的实现方式值得考量,同学们可能会说可以利用Redis的单线程自增函数来实现,当然是可以的,但我们不需要自行实现,有现成的轮子可以使用,那就是:
分布式发号器(Distributed ID Generator)。
关于分布式发号器的内容,我们下回再叙。
七、思考
一个长网址,对应一个短网址,还是可以对应多个短网址?
这也是个重大选择问题。一般而言,一个长网址,在不同的地点,不同的用户等情况下,生成的短网址应该不一样,这样,在后端数据库中,可以更好的进行数据分析。如果一个长网址与一个短网址一一对应,那么在数据库中,仅有一行数据,无法区分不同的来源,就无法做数据分析了。
以这个7位长度的短网址作为唯一ID,这个ID下可以挂各种信息,比如生成该网址的用户名,所在网站,HTTP头部的 User Agent等信息,收集了这些信息,才有可能在后面做大数据分析,挖掘数据的价值。短网址服务商的一大盈利来源就是这些数据。
正确答案:一对多
短网址系统参考代码:https://github.com/gentoo111/shortLink
我的微信公众号:架构真经(关注领取免费资源)

参考文章
- https://www.jianshu.com/p/d7c1edc0836e
- https://segmentfault.com/a/1190000012088345?utm_source=tag-newest
- https://blog.csdn.net/JH_Zhai/article/details/80379103
- https://www.jianshu.com/p/c9b49ac268e5
- https://www.zhihu.com/question/20103344/answer/573638467
- https://www.cnblogs.com/feiyafeiblog/p/8581853.html


















 1084
1084

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











