







🍌文章适合于所有的相关人士进行学习🍌
🍋各位看官看完了之后不要立刻转身呀🍋
🍑期待三连关注小小博主加收藏🍑
🍉小小博主回关快 会给你意想不到的惊喜呀🍉
文章目录

🌋前言
今天我们来讲解Logistic回归模型的相关理论知识和代码,其实Logistic回归模型是线性回归模型的广义模式,但是和岭回归和Lasso回归还不一样,他不像岭回归和Lasso回归实在多重线性回归模型上去做出改进,加入惩罚项,详情请看岭回归和Lasso回归。而Logistic回归有自己的想法。具体请看下方讲解。

🌋Logistic回归模型理论讲解
🌏Logistic引出
我们从上节课中可以得到线性回归模型的方程是:

我们进行了Logit变换,可以得到如下的形式,

做了一次Logit变换,经过非线性的Logit函数变换为[0,1]之间的概率值,这里我们举一个例子,比如说现在有一张照片,我们通过计算判断他是狗的概率是85%,判断他是猫的概率是15%,那么我们最后得到的结果就是判断他是狗。这样就通过概率来进行了分类,所以我们说Logistic和之前讲到的模型不一样的地方这里也是一个非常大的点,就是我们之前介绍的是用来做预测的,而我们这次讲的内容是做分类的。我们将线性回归部分用z来替代。画图就可以得到下方的图:
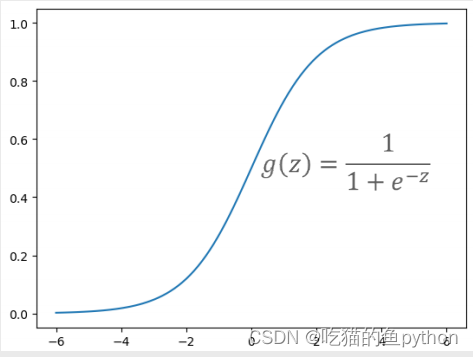
由于z的范围是正无穷到负无穷的,所以当z趋近于正无穷时候,分母则趋近于1,那么结果也必定趋近于1.当z趋近于负无穷的时候,那么分母也趋近于正无穷,那么最后的结果必定趋近于0.特殊情况就是当z等于0的时候,那么这个时候函数等于0.5,这个0.5的意义也非常大,就是判断正负例子的临界点。也称之为敏感点。比如说我们举一个例子,如果我们想买一个商品,通过判断我们想要购买的概率是0.6,那么比0.5大,所以我们就判定为要买。
🌏模型变换
我们将y取1的概率定位p,那么y取0就是1-p。用其做商,得到:

如果我们再给他加上一个ln,那么他就又变成了线性回归模型的函数,可以说是非常巧妙,数学本来就是一个非常巧妙的东西,非常神奇!!!

其实也等价于这种形式:

这里当y等于0的时候,自然就是1-h b(X)的1-y次方这种形式。
当y等于1的时候,也就是前面这种形式。
🌏构造最大似然函数
构造似然函数,实在数理统计学中的相关知识,似然函数是一种关于统计模型的参数的函数,表示模型参数的似然性。
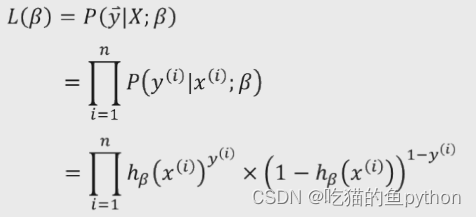
我们构造出如上的似然函数,这里是对其进行累乘,为了求其最大值。那么我们就像能不能把他变成累加,因为累加毕竟比累乘要好运算啊,那么我们就在其前方加上log函数,因为加上log后,依旧也是求解最大值,所以对函数本身求解并没有任何影响,所以我们加上log后:

但是求最大值我们还是没有思路,因为之前一致再求最小值,所以我们在前面加上负号,就是求其最小值了。数学的巧妙地方就在这里,就像是拆积木一样,然后在拼接上一样,非常有趣。
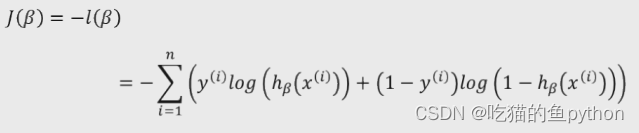
这个时候我们就有思路了就是求其偏导数,然后令偏导数等于0,这样就可以求解了,但是由于B的个数多余方程组的个数,也就是这个意思:
- x+y+z=3
- x+y=2
这里我们能求出x,y,z的数值吗,明显是不能的,所以我们在这里又对目标函数进行了梯度下降得到下方:

🌏参数含义解释
那么这里的byta究竟是什么意思呢??一脸懵比中,我们继续来举个例子:
假如影响肿瘤的因素有性别和肿瘤体积这两个因素,对应的参数分别是byta1和byta2,那么根据Logistic回归模型来判断其发生比也叫做优势比:
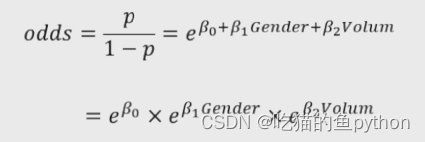
假设男用1来表示,女用0来表示。
那么我们可以得到:

这里如果结果比一大,就说明了男性患癌症的概率要比女性大。相反则女性比男性大。
同理我们对于肿瘤体积的讲解如下:

解释也一样。
🌋验证模型
🌏混淆矩阵
我们之前说到的线性回归模型用到检测模型好坏的方法是使用均方误差的方法来极爱检测,也就是MSE。
我们这次则使用其他的方法来进行检测,首先我们来介绍混淆矩阵。

- 表示正确预测负例的样本个数,用TN表示。
- 表示预测为负例但实际为正例的个数,用FN表示。
- 表示预测为正例但实际为负例的个数,用FP表示。
- 表示正确预测正例的样本个数,用TP表示。
这里就设计到了几个概念:
- 准确率:表示正确预测的正负例样本数与所有样本数量的比值,即(A+D)/(A+B+C+D)。
- 正例覆盖率:表示正确预测的正例数在实际正例数中的比例,即D/(B+D) 。
- 负例覆盖率:表示正确预测的负例数在实际负例数中的比例,即A/(A+C)。
- 正例命中率:表示正确预测的正例数在预测正例数中的比例,即D/(C+D)。
🌏ROC曲线
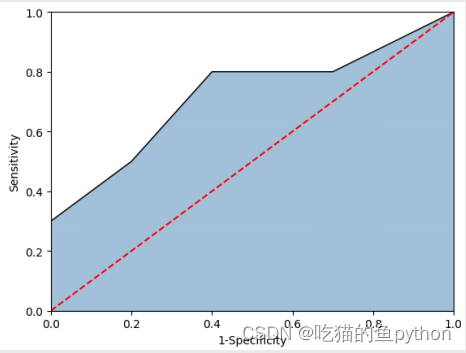
这就是ROC曲线,那么他又是什么呢?
图中的红色线为参考线,即在不使用模型的情况下, Sensitivity 和 1-Specificity 之比恒等于 1。通常绘制 ROC曲线,不仅仅是得到左侧的图形,更重要的是计算 折线下的面积,即图中的阴影部分,这个面积称为AUC。 在做模型评估时,希望AUC的值越大越好,通常情况下, 当AUC在0.8以上时,模型就基本可以接受了。
🌏KS曲线

图中的两条折线分别代表各分位点下的正例覆盖率和1 -负例覆盖率,通过两条曲线很难对模型的好坏做评估,一般会选用最大的KS值作为衡量指标。KS的计算公式为: KS= Sensitivity-(1- Specificity)= Sensitivity+ Specificity-1。对于KS值而言,也是希望越大越好,通常情况下,当KS值大于0.4时,模型基本可以接受。
🌏Logistic回归参数说明
LogisticRegression(tol=0.0001, fit_intercept=True,class_weight=None, max_iter=100)
tol:用于指定模型跌倒收敛的阈值。
fit_intercept:bool类型参数,是否拟合模型的截距项,默认为True。
class_weight:用于指定因变量类别的权重,如果为字典,则通过字典的形式。{class_label:weight}传递每个类别的权重;如果为字符串’balanced’,则每个分类的权重与实际样本中的比例成反比,当各分类存在严重不平衡时,设置为’balanced’会比较好;如果为None,则表示每个分类的权重相等。
max_iter:指定模型求解过程中的最大迭代次数, 默认为100。
🌋代码部分讲解
数据我还是会放在我的下载资源当中。各位小伙伴可以到里面进行下载。
绘制ks线的python代码
# 导入第三方模块
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
# 自定义绘制ks曲线的函数
def plot_ks(y_test, y_score, positive_flag):
# 对y_test重新设置索引
y_test.index = np.arange(len(y_test))#np.arange()一个参数时候 从0开始到len()结束 默认步长为1
# 构建目标数据集
target_data = pd.DataFrame({'y_test':y_test, 'y_score':y_score})#类似生成一个电子表格
# 按y_score降序排列
target_data.sort_values(by = 'y_score', ascending = False, inplace = True)
# 自定义分位点
cuts = np.arange(0.1,1,0.1)
# 计算各分位点对应的Score值
index = len(target_data.y_score)*cuts#20*0.1 按照步长0.1继续乘法2
scores = np.array(target_data.y_score)[index.astype('int')] #降序排列之后 选择索引为index的数值取值
# 根据不同的Score值,计算Sensitivity和Specificity
Sensitivity = []
Specificity = []
for score in scores:
# 正例覆盖样本数量与实际正例样本量
positive_recall = target_data.loc[(target_data.y_test == positive_flag) & (target_data.y_score>score),:].shape[0]
positive = sum(target_data.y_test == positive_flag)
# 负例覆盖样本数量与实际负例样本量
negative_recall = target_data.loc[(target_data.y_test != positive_flag) & (target_data.y_score<=score),:].shape[0]
negative = sum(target_data.y_test != positive_flag)
Sensitivity.append(positive_recall/positive)
Specificity.append(negative_recall/negative)
print(Sensitivity,Specificity)
# 构建绘图数据
plot_data = pd.DataFrame({'cuts':cuts,'y1':1-np.array(Specificity),'y2':np.array(Sensitivity),
'ks':np.array(Sensitivity)-(1-np.array(Specificity))})
# 寻找Sensitivity和1-Specificity之差的最大值索引
max_ks_index = np.argmax(plot_data.ks)
plt.plot([0]+cuts.tolist()+[1], [0]+plot_data.y1.tolist()+[1], label = '1-Specificity')
plt.plot([0]+cuts.tolist()+[1], [0]+plot_data.y2.tolist()+[1], label = 'Sensitivity')
# 添加参考线
plt.vlines(plot_data.cuts[max_ks_index], ymin = plot_data.y1[max_ks_index],
ymax = plot_data.y2[max_ks_index], linestyles = '--')
# 添加文本信息
plt.text(x = plot_data.cuts[max_ks_index]+0.01,
y = plot_data.y1[max_ks_index]+plot_data.ks[max_ks_index]/2,
s = 'KS= %.2f' %plot_data.ks[max_ks_index])
# 显示图例
plt.legend()
# 显示图形
plt.show()
这里就是画出两条线,然后将参考线画出来就ok了,非常简单!!!
完整代码
# 导入第三方模块
import pandas as pd
import numpy as np
from sklearn import model_selection
from sklearn import linear_model
# 读取数据
sports = pd.read_csv(r'Run or Walk.csv')
# 提取出所有自变量名称
predictors = sports.columns[4:]
# 构建自变量矩阵
X = sports.ix[:,predictors]
# 提取y变量值
y = sports.activity
# 将数据集拆分为训练集和测试集
X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size = 0.25, random_state = 1234)
# 利用训练集建模
sklearn_logistic = linear_model.LogisticRegression()
sklearn_logistic.fit(X_train, y_train)
# 返回模型的各个参数
print(sklearn_logistic.intercept_, sklearn_logistic.coef_)#其中4.35是截距项 后面是各项指数的系数
# 模型预测
sklearn_predict = sklearn_logistic.predict(X_test)
# 预测结果统计
pd.Series(sklearn_predict).value_counts()
# 导入第三方模块
from sklearn import metrics
# 混淆矩阵
cm = metrics.confusion_matrix(y_test, sklearn_predict, labels = [0,1])
cm
Accuracy = metrics.scorer.accuracy_score(y_test, sklearn_predict)
Sensitivity = metrics.scorer.recall_score(y_test, sklearn_predict)
Specificity = metrics.scorer.recall_score(y_test, sklearn_predict, pos_label=0)
print('模型准确率为%.2f%%:' %(Accuracy*100))
print('正例覆盖率为%.2f%%' %(Sensitivity*100))
print('负例覆盖率为%.2f%%' %(Specificity*100))
# 混淆矩阵的可视化
# 导入第三方模块
import seaborn as sns
import matplotlib.pyplot as plt
%matplotlib
# 绘制热力图
sns.heatmap(cm, annot = True, fmt = '.2e',cmap = 'GnBu')
# 图形显示
plt.show()
# y得分为模型预测正例的概率
y_score = sklearn_logistic.predict_proba(X_test)[:,1]
# 计算不同阈值下,fpr和tpr的组合值,其中fpr表示1-Specificity,tpr表示Sensitivity
fpr,tpr,threshold = metrics.roc_curve(y_test, y_score)
# 计算AUC的值
roc_auc = metrics.auc(fpr,tpr)
# 绘制面积图
plt.stackplot(fpr, tpr, color='steelblue', alpha = 0.5, edgecolor = 'black')
# 添加边际线
plt.plot(fpr, tpr, color='black', lw = 1)
# 添加对角线
plt.plot([0,1],[0,1], color = 'red', linestyle = '--')
# 添加文本信息
plt.text(0.5,0.3,'ROC curve (area = %0.2f)' % roc_auc)
# 添加x轴与y轴标签
plt.xlabel('1-Specificity')
plt.ylabel('Sensitivity')
# 显示图形
plt.show()
这里我们今天的讲解就全部完成了。
🍌文章适合于所有的相关人士进行学习🍌
🍋各位看官看完了之后不要立刻转身呀🍋
🍑期待三连关注小小博主加收藏🍑
🍉小小博主回关快 会给你意想不到的惊喜呀🍉

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











