







前言
前一篇文章对 linux5.10 的 slab 分配器底层实现进行了探究与学习。进一步地,本篇文章将对 linux5.10 的 slub 分配器进行探究,对比看看两者的实现有何不同,做了哪些"必要的"改进。
slub 分配器
关于 slub 分配器的基本原理与 slab 分配器类似,只是相较于 slab 更快更直接以及更简单,主要对涉及的结构体进行学习,再以 kmalloc 为入口开始探究,并对比一下初始化过程的不同
主要数据结构
struct kmem_cache {
struct kmem_cache_cpu __percpu *cpu_slab;
/* Used for retrieving partial slabs, etc. */
slab_flags_t flags;
unsigned long min_partial;
unsigned int size; /* The size of an object including metadata */
unsigned int object_size;/* The size of an object without metadata */
struct reciprocal_value reciprocal_size;
unsigned int offset; /* Free pointer offset */
struct kmem_cache_order_objects oo;
/* Allocation and freeing of slabs */
struct kmem_cache_order_objects max;
struct kmem_cache_order_objects min;
gfp_t allocflags; /* gfp flags to use on each alloc */
int refcount; /* Refcount for slab cache destroy */
void (*ctor)(void *);
unsigned int inuse; /* Offset to metadata */
unsigned int align; /* Alignment */
unsigned int red_left_pad; /* Left redzone padding size */
const char *name; /* Name (only for display!) */
struct list_head list; /* List of slab caches */
};
struct kmem_cache_cpu {
void **freelist; /* Pointer to next available object */
unsigned long tid; /* Globally unique transaction id */
struct page *page; /* The slab from which we are allocating */
#ifdef CONFIG_SLUB_CPU_PARTIAL
struct page *partial; /* Partially allocated frozen slabs */
#endif
#ifdef CONFIG_SLUB_STATS
unsigned stat[NR_SLUB_STAT_ITEMS];
#endif
};
struct kmem_cache_node {
spinlock_t list_lock;
unsigned long nr_partial;
struct list_head partial;
}
struct page {
unsigned long flags; /* Atomic flags, some possibly
struct list_head slab_list;
struct kmem_cache *slab_cache; /* not slob */
/* Double-word boundary */
void *freelist; /* first free object */
struct {
/* SLUB */
unsigned inuse:16;
unsigned objects:15;
unsigned frozen:1;
};
atomic_t _refcount;
};
其中,page 用了很多共同体,笔者将其简化只留下与 slub 相关的。对比 slab 分配器数据结构,主要不同在于:
- slub 本地缓存 kmem_cache_cpu 相较于 slab 的 array_cache ,由存储 obj 指针的数组变为直接存储一整个 slub ,并添加了 partial 串联小部分可用 slub。该改变意味着本地缓存可分配容量变大,当需要分配内存时,基本上都能够通过本地缓存进行分配,缩短了分配路径提升了分配效率
- kmem_cache_node 结构被简化,由多链表变成单链表,且没有共享缓存,进一步缩短了分配路径
- 丢弃了 color 着色
对此,绘制关系图如下
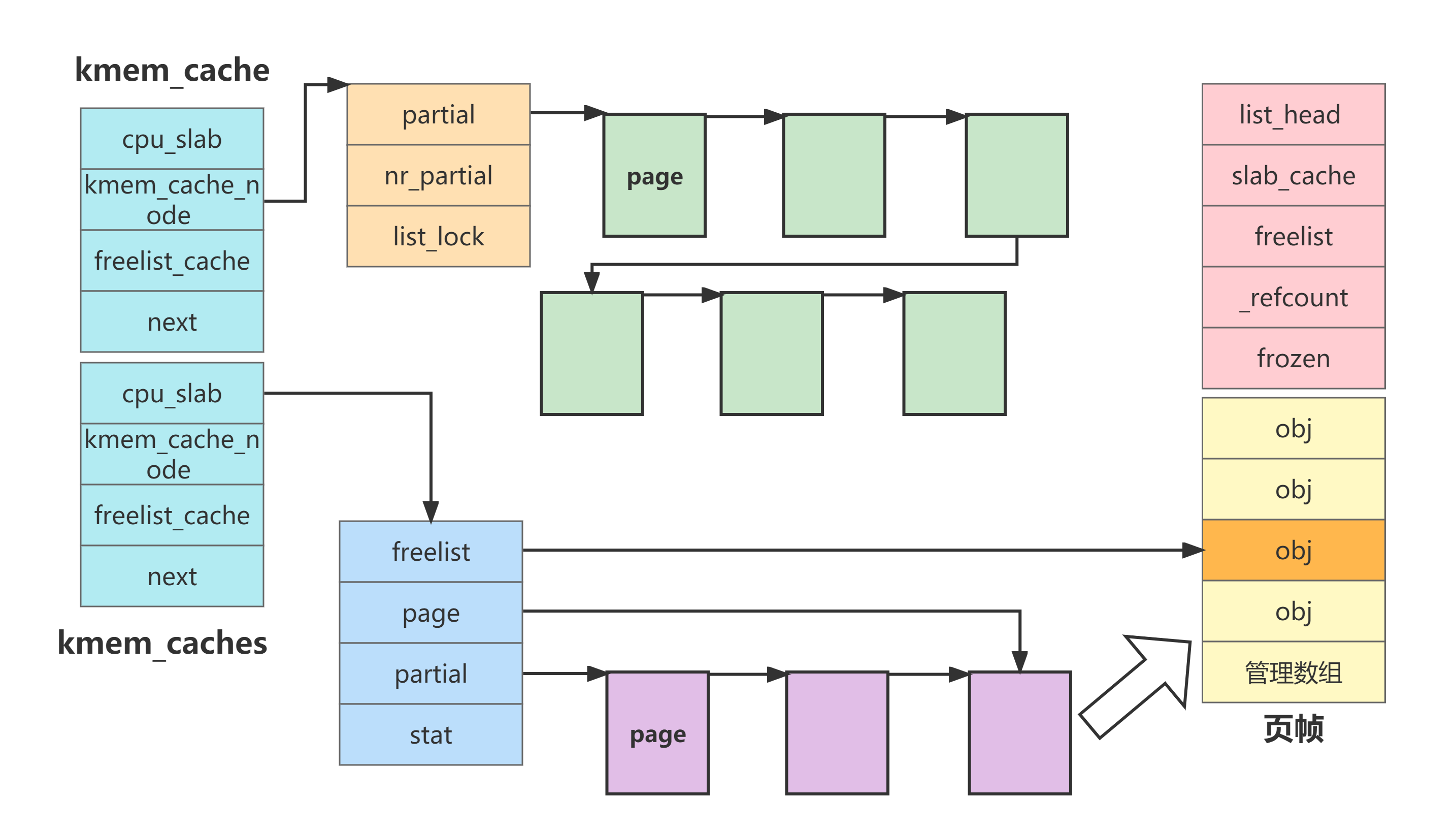
根据上述结构关系图,简单地描述一下 slub 分配器的分配过程,由于 slub 不在用 obj 指针数组来管理本地缓存,因此分配内存的流程会有所变化
- 首先根据 size 从 kmem_caches 中获取对应的 kmem_cache
- 从 kmem_cache 中获取本地缓存 kmem_cache_cpu ,根据其 freelist 可得到空闲 obj 的地址,该 obj 对应页由 page 指针记录
- 如果 freelist 为空说明当前 page 已经被分配完,则搜索 partial 关联的 slub 链表,看是否有空闲 obj ,有则将 freelist 指向,并修改 page 指针指向该 sub 所在页
- 如果 partial 依然没有空闲 slub ,则进入 kmem_cache_node 的 partial 链表进行进一步地搜索。如果搜索到空闲的 obj ,则只需要直接返回该 obj 地址,同时修改 kmem_cache_cpu 中 freelist 和 page 指针指向。
- 同时,判断 kmem_cache_cpu 中的 partial 串联的 slub 数量是否满足 slub_cpu_partial ,如果不满足则申请 page 并初始化为 slub 并添加到 kmem_cache_cpu 的 partial 中
从上述描述中,可以明显地感觉到, slub 并不需要对本地缓存进行过多的维护,对于 slab 而言,却需要总是更新 obj 指针数组的下标。
并且,可以看出本地缓存 kmem_cache_cpu 的 partial 一旦被初始化到指定数量后,就不会进行变更。变的只有 freelist 和 page 指针。意味着,本地缓存当前所使用的 slub 可能来自 kmem_cache_node 的 partial,也可能来自 kmem_cache_node 的 partial。且如果当前 slub 被分配完,搜寻下一个空闲 obj 的顺序仍然是先搜寻本地缓存的 partial ,再到 kmem_cache_node 的 partial
kmalloc
与 slub 的探究思路类似,从 kmalloc 入口进入,看看 slub 分配器如何进行内存分配的。
kmalloc = 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 457
457











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









