









 本文深入探讨Linux内核SLUB内存分配器的工作原理,包括三级缓存结构、分配算法及四种分配场景的具体实现。通过解析核心函数slab_alloc_node,帮助读者理解SLUB如何高效地管理内存。
本文深入探讨Linux内核SLUB内存分配器的工作原理,包括三级缓存结构、分配算法及四种分配场景的具体实现。通过解析核心函数slab_alloc_node,帮助读者理解SLUB如何高效地管理内存。
Linux 内存管理之SLUB分配器三 [ Object分配逻辑 ]
内存是需要被操作系统管理的资源,我们在不同层次的管理本质是一样的:
- 以怎样的数据结构管理空闲资源,这部分在上一小节中已经整理完成;
- 以怎样的算法分配/释放资源,本小节主要整理分配逻辑部分;
1. 框架
-
数据结构框图:
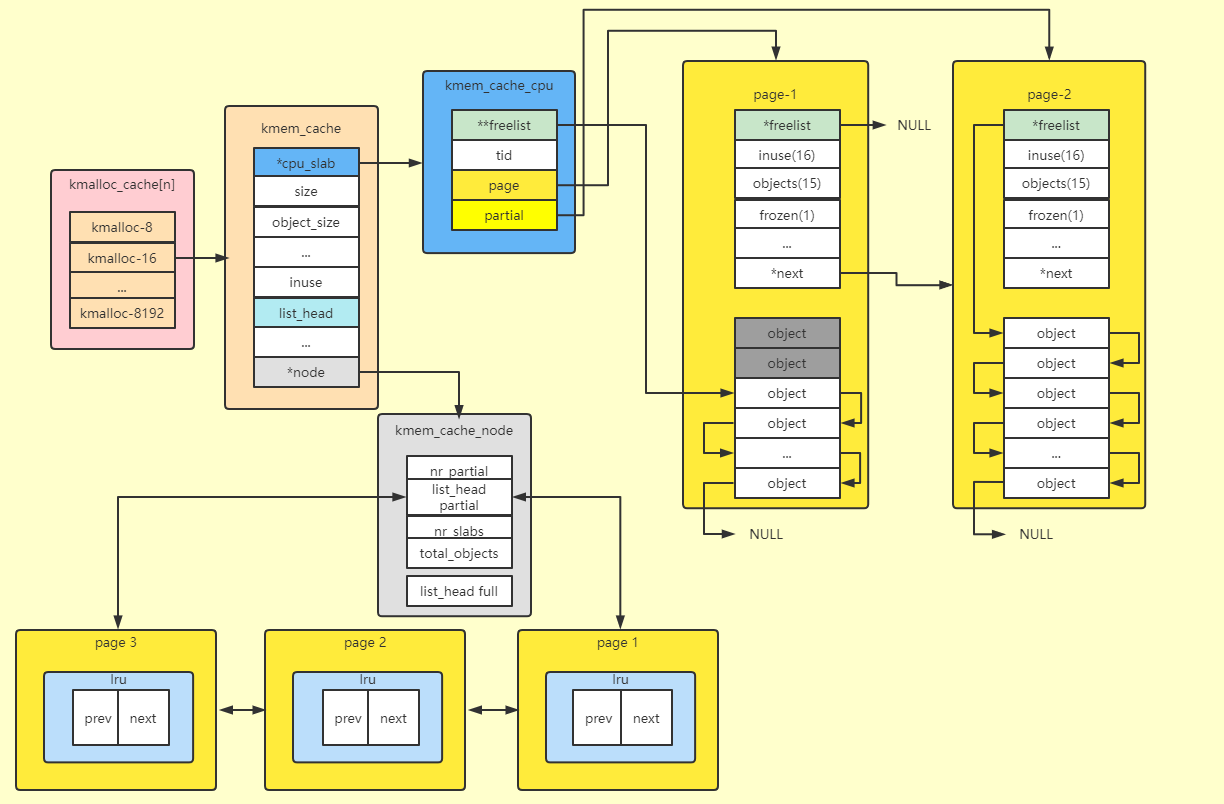
-
三级缓存结构:
基于上述数据结构,可以理解SLUB为三级缓存结构:
- 第一层,在freelist中寻找,速度最快;
- 第二层,在kmem_cache_cpu中寻找,需要切换page;
- 第三层,在kmem_cache_node中寻找;
与其他缓存机制一样,越向下寻找,资源消耗越多;
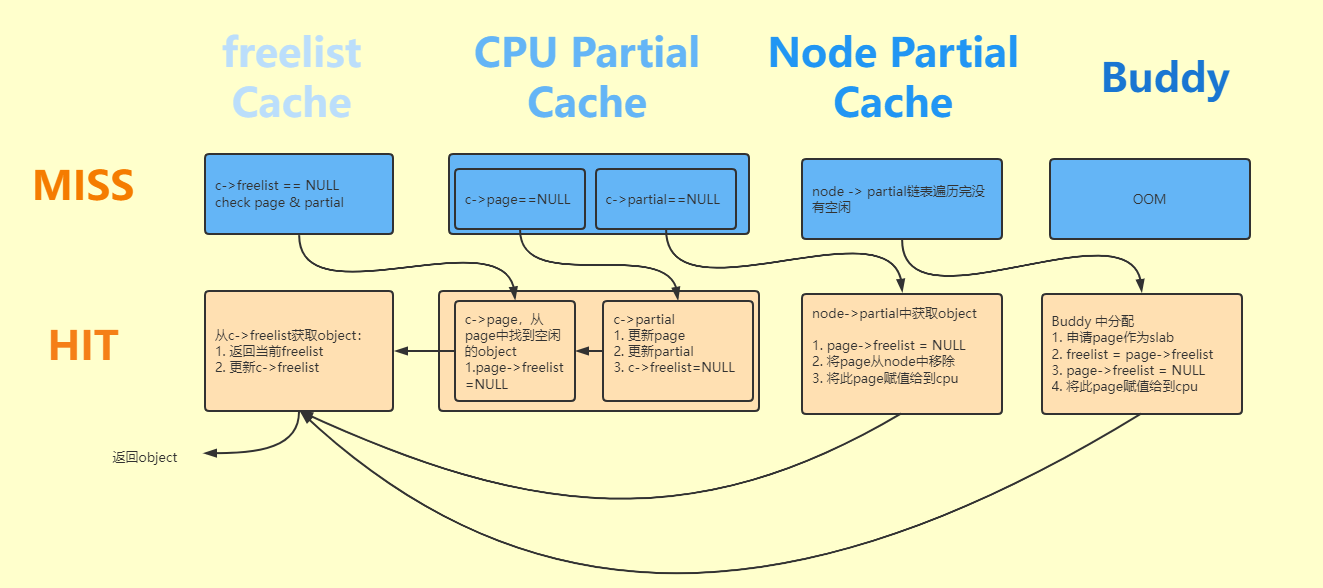
即将freelist、kmem_cache_cpu 、kmem_cache_node结构理解为三层缓存的结构,依次搜索空闲的object,直到找到为止;
2. 关于分配的四种case
整体逻辑都在上述图里了,这里详细介绍下各种case的细节处理,其核心入口函数为:slab_alloc_node;
2.1 基于freelist分配

本部分没有什么特别的,实际只做了两件事情:
- 将c->freelist 指向的object返回;
- 将next_object赋值给到 c->freelist;
2.2 基于kmem_cache_cpu分配
如果上述c->freelist中object已经被分配完,则此时c->freelist为NULL,我们需要到kmem_cache_cpu中分配,分为两种情况:
- c->page是存在的,首先从此page中搜索;
- 如上述不存在则从kmem_cache_cpu->partial链表中搜索;
2.2.1 c->page中分配

当2.1中object为空时,即会进入此流程:
- 获取page中的freelist指针并返回;
- 更新page->freelist为NULL,这个细节需要注意;
- 获取到page中下一个空闲的object,并将其赋值给到kmem_cache_cpu->freelist,则下次可以直接获取;
2.2.2 c->partial中分配
另外需要注意的是,2.2.1 虽然有整理出来code流程,但是理论上是不存在这种可能性的,因为每次从page中获取到freelist后,page->freelist都为NULL,即这里get_freelist基本是失败的,详情如下:

此流程中c->freelist和page->freelist都为NULL(按照设计流程在freelist为空时就是这种情况)
- 将c->page设置为NULL,进入c->partial链表中搜索;
- 更新page 和 partial的指针,接下来的处理与2.2.1中相同;
2.3 基于kmem_cache_node分配
如果上述c->partial 为NULL,即当前的kmem_cache_cpu上没有page了,则需要从node中分配:
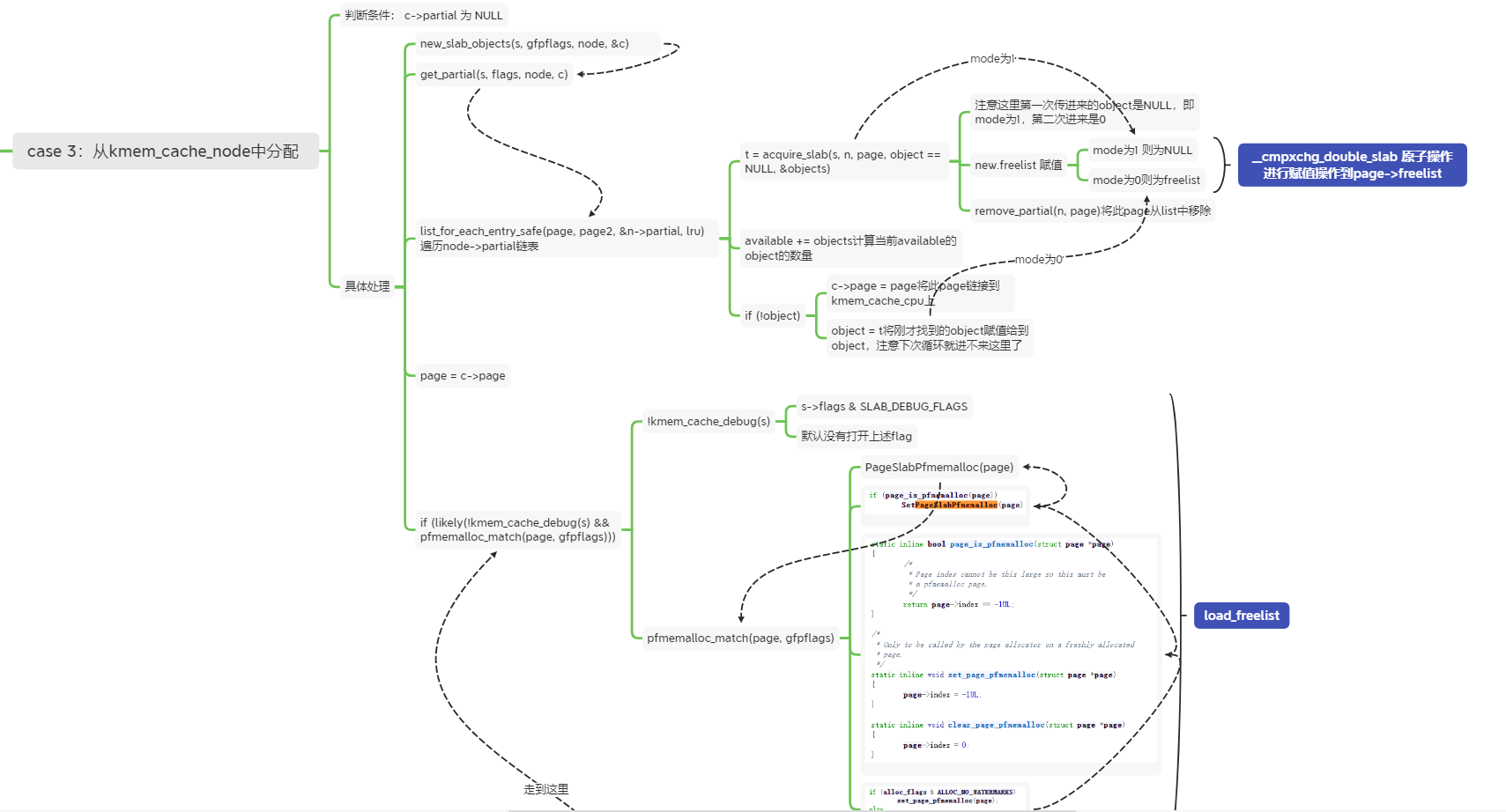
这里的处理逻辑也很简单:
-
遍历当前node上的partial链表,找到page->freelist
- 这部分有些细节需要注意:
- 进行acquire_slab操作时第一次传入的object为空,mode为1
- 在mode为1的情况下,会将page->freelist设置为NULL
- acquire_slab的返回值后续会赋值给到object并返回,即第二次进入acquire时mode为0;
- 第二次及以后会将page挂到cpu->partial上,直到数量达到一半;
- 这部分有些细节需要注意:
-
将当前的page赋值给到kmem_cache_cpu->page上
-
跳出去后进行几个判断,然后load_freelist操作
- kmem_cache_debug:默认是没有配置debug flag的,所以这里是OK的;
- pfmemalloc_match(page, gfpflags):这里是判断watermark标志是否存在,根据flag判断这里是返回true;
即上述两个判断都满足后进行load_freelist操作,更新CPU结构上的freelist指针;
static void *get_partial_node(struct kmem_cache *s, struct kmem_cache_node *n,
struct kmem_cache_cpu *c, gfp_t flags)
{
struct page *page, *page2;
void *object = NULL;//注意这里object为NULL
int available = 0;
int objects;
...
spin_lock(&n->list_lock);
list_for_each_entry_safe(page, page2, &n->partial, lru) {
void *t;
...
//第一次进入时object值为NULL,就是说mode为1
t = acquire_slab(s, n, page, object == NULL, &objects);
if (!t)//返回值为page->freelist,这里不为空,第二次进来会是空;
break;
available += objects;
if (!object) {
c->page = page;
stat(s, ALLOC_FROM_PARTIAL);
object = t;//第一次进入后将t赋值给到object,即此时object不为空,mode为0
} else {
put_cpu_partial(s, page, 0);//后续会将page挂到kmem_cache_cpu上
stat(s, CPU_PARTIAL_NODE);
}
if (!kmem_cache_has_cpu_partial(s) || available > s->cpu_partial / 2) //直到数量满足1/2
break;
}
spin_unlock(&n->list_lock);
return object;
}
//acquire_slab
static inline void *acquire_slab(struct kmem_cache *s,
struct kmem_cache_node *n, struct page *page,
int mode, int *objects)
{
void *freelist;
unsigned long counters;
struct page new;
lockdep_assert_held(&n->list_lock);
freelist = page->freelist;
counters = page->counters;
new.counters = counters;
*objects = new.objects - new.inuse;
if (mode) {//第一次进入
new.inuse = page->objects;
new.freelist = NULL;//此值后续会赋值给到page->freelist
} else {
new.freelist = freelist;//mode为0的情况,不需要将page->freelist设置为NULL
}
VM_BUG_ON(new.frozen);
new.frozen = 1;
if (!__cmpxchg_double_slab(s, page, freelist, counters, new.freelist, new.counters, "acquire_slab"))
return NULL;
remove_partial(n, page);
WARN_ON(!freelist);
return freelist;
}
2.4 分配slab page

本部分主要考虑object的分配逻辑,所以没有详细分析new_slab部分内容,这部分内容下一小节整理

















 969
969

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









