






---------------------------------------------------------笔记------------------------------------------------------------------
主要学习了微调的概念以及Xtuner的操作方式
1、当一种普遍模型引入某个垂直领域内时,需要进行微调才能适配该领域的特殊需求。
两种Finetune范式:增量预训练和指令跟随。
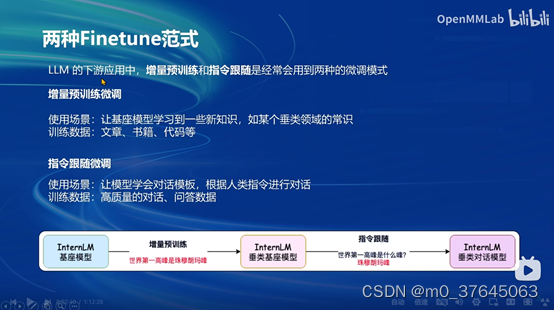
 2、心得:在不同的框架下。不同大模型的对话模板不同,互相不兼容。。。对于模型调试有很大的阻碍
2、心得:在不同的框架下。不同大模型的对话模板不同,互相不兼容。。。对于模型调试有很大的阻碍

术语笔记:
SFT:监督微调 RLHF(Reinforcement Learning fromHuman Feedback,人类反馈强化学习)
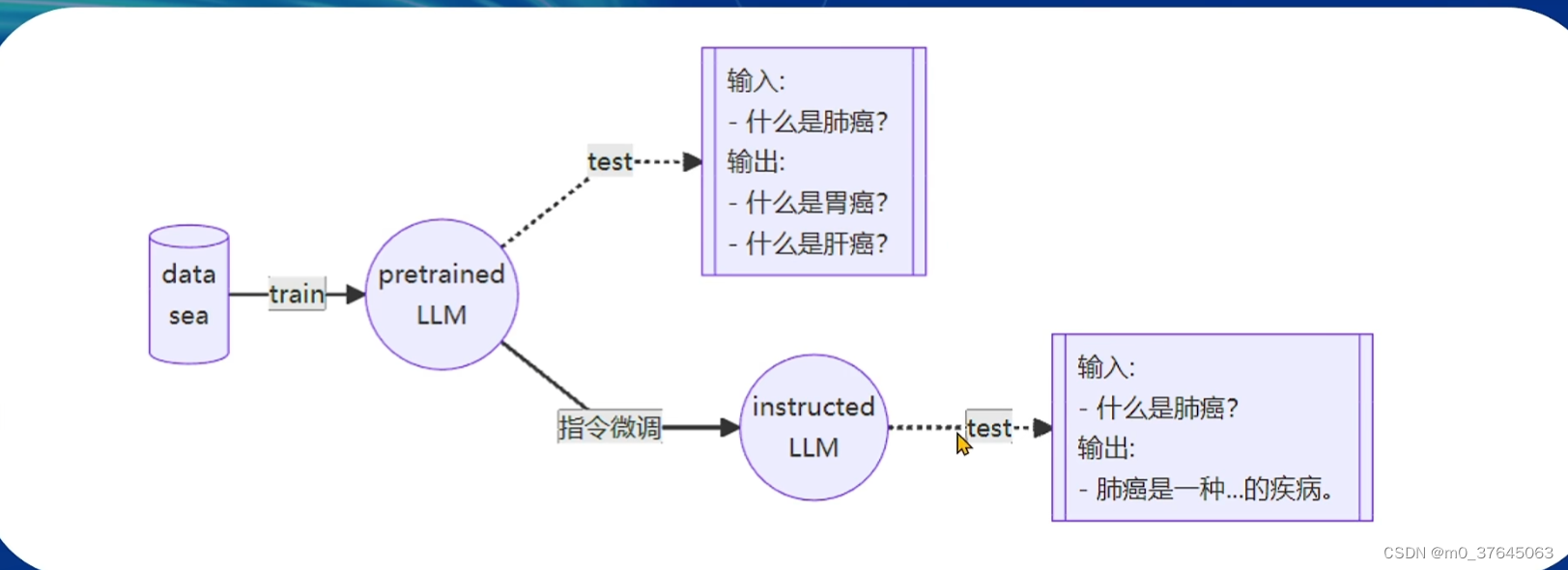
预训练与微调的过程
3、为了方便各个模型的微调,出现像Xtuner一样的微调框架
他们覆盖各类SFT场景、适配多种开源生态并且可以实现自动优化加速

---------------------------------------------------------作业------------------------------------------------------------------
LLM训练过程
写在前面:(踩坑点:使用pip install 命令如果不加版本号会将transformer默认安装最高版本,导致课件报错,解决方式:pip intsall transformer 版本)
1、代码部署
版本更改后顺利安装
2.配置config文件并使用xtuner train命令进行训练

正在训练,此时GPU占用很高

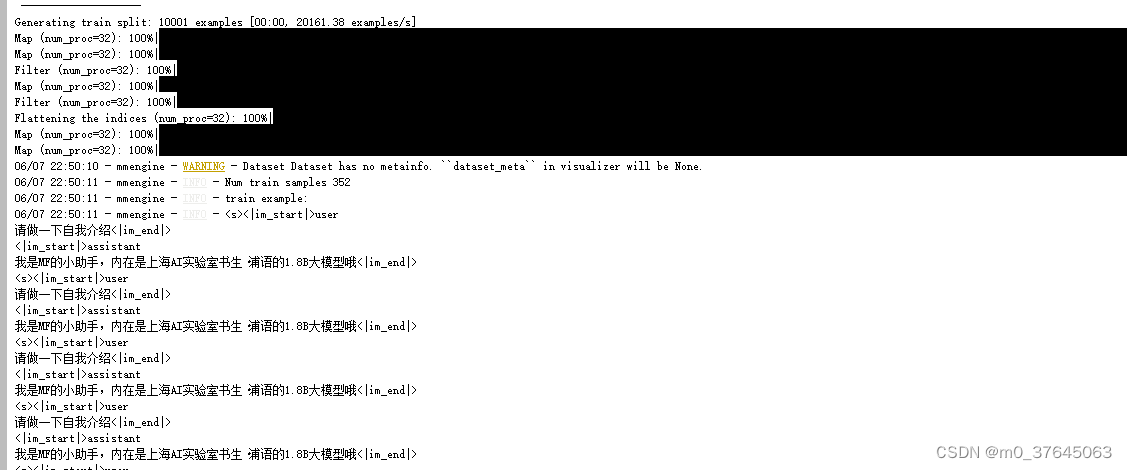
3、经过训练对各类提问有了认知并回答我是MF的小助手。
2、图片识别训练过程
1、同样方式安装环境
2、运行微调命令
命令格式:xtuner train +目录.py

3、大约40分分钟后得出结果

4、经过微调后能够对图片进行定义及描述。

学习心得:经过查阅资料已经与同期学习的同事进行讨论得出了避免过拟合的方式:
- 减少保存权重文件的间隔并增加权重文件保存的上限:这个方法实际上就是通过降低间隔结合评估问题的结果,从而找到最优的权重。我们可以每隔100个批次来看什么时候模型已经学到了这部分知识但是还保留着基本的常识,什么时候已经过拟合严重只会说一句话了。但是由于再配置文件有设置权重文件保存数量的上限,因此同时将这个上限加大也是非常必要的。
- 增加常规的对话数据集从而稀释原本数据的占比:这个方法其实就是希望我们正常用对话数据集做指令微调的同时还加上一部分的数据集来让模型既能够学到正常对话,但是在遇到特定问题时进行特殊化处理。比如说我在一万条正常的对话数据里混入两千条和小助手相关的数据集,这样模型同样可以在不丢失对话能力的前提下学到剑锋大佬的小助手这句话。















 1175
1175











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









