






-----------------------------------------------------------笔记----------------------------------------------------------------
本节课主要学习模型测评的概念以及“司南”评测体系的评测实践
1、做模型评测的原因(摘自本节课课件)
- 首先,研究评测对于我们全面了解大型语言模型的优势和限制至关重要。尽管许多研究表明大型语言模型在多个通用任务上已经达到或超越了人类水平,但仍然存在质疑,即这些模型的能力是否只是对训练数据的记忆而非真正的理解。例如,即使只提供LeetCode题目编号而不提供具体信息,大型语言模型也能够正确输出答案,这暗示着训练数据可能存在污染现象。
- 其次,研究评测有助于指导和改进人类与大型语言模型之间的协同交互。考虑到大型语言模型的最终服务对象是人类,为了更好地设计人机交互的新范式,我们有必要全面评估模型的各项能力。
- 最后,研究评测可以帮助我们更好地规划大型语言模型未来的发展,并预防未知和潜在的风险。随着大型语言模型的不断演进,其能力也在不断增强。通过合理科学的评测机制,我们能够从进化的角度评估模型的能力,并提前预测潜在的风险,这是至关重要的研究内容。
- 对于大多数人来说,大型语言模型可能似乎与他们无关,因为训练这样的模型成本较高。然而,就像飞机的制造一样,尽管成本高昂,但一旦制造完成,大家使用的机会就会非常频繁。因此,了解不同语言模型之间的性能、舒适性和安全性,能够帮助人们更好地选择适合的模型,这对于研究人员和产品开发者而言同样具有重要意义。
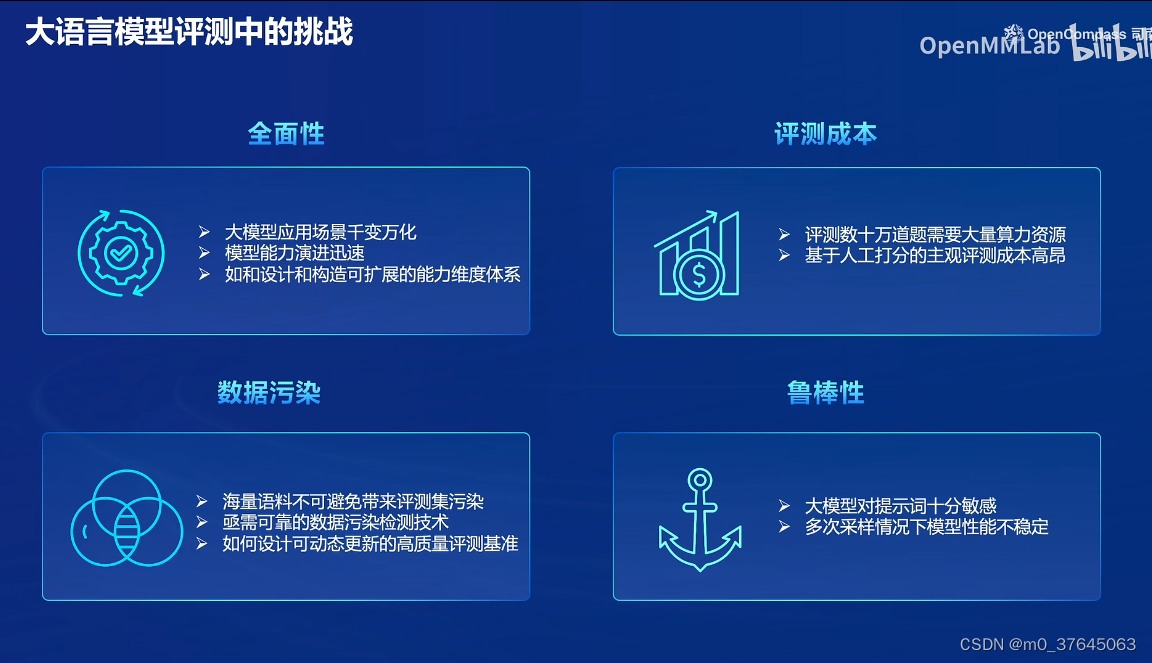
2、大模型评测过程中面临的挑战:全面性、评测成本、数据污染、鲁棒性
3、评测大模型的方式

4、大模型评测步骤
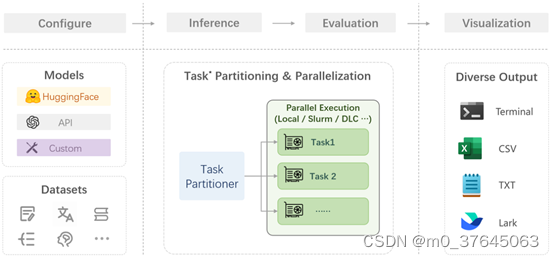
步骤包括:配置 -> 推理 -> 评估 -> 可视化
- 配置:这是整个工作流的起点。您需要配置整个评估过程,选择要评估的模型和数据集。此外,还可以选择评估策略、计算后端等,并定义显示结果的方式。
- 推理与评估:在这个阶段,OpenCompass 将会开始对模型和数据集进行并行推理和评估。推理阶段主要是让模型从数据集产生输出,而评估阶段则是衡量这些输出与标准答案的匹配程度。这两个过程会被拆分为多个同时运行的“任务”以提高效率,但请注意,如果计算资源有限,这种策略可能会使评测变得更慢。
- 可视化:评估完成后,OpenCompass 将结果整理成易读的表格,并将其保存为 CSV 和 TXT 文件。你也可以激活飞书状态上报功能,此后可以在飞书客户端中及时获得评测状态报告。
5、模型评估过程中包括客观评测与主观评测的方式。
主观评测与客观评测举例:

6、在模型评测过程中,提示词会很大程度上影响一个模型的输出结果
不恰当的提示词会影响模型的输出

-----------------------------------------------------------作业----------------------------------------------------------------
本次利用opencompass对internlm1.8B进行评测
1、安装opencompass环境
命令:studio-conda -o internlm-base -t opencompass
source activate opencompass
git clone -b 0.2.4 https://github.com/open-compass/opencompass
cd opencompass
pip install -e .
发现-e会使很多安装包没有安装,一定要pip install -r requirements.txt才能安装齐全
提示ALL DONE则完成环境安装
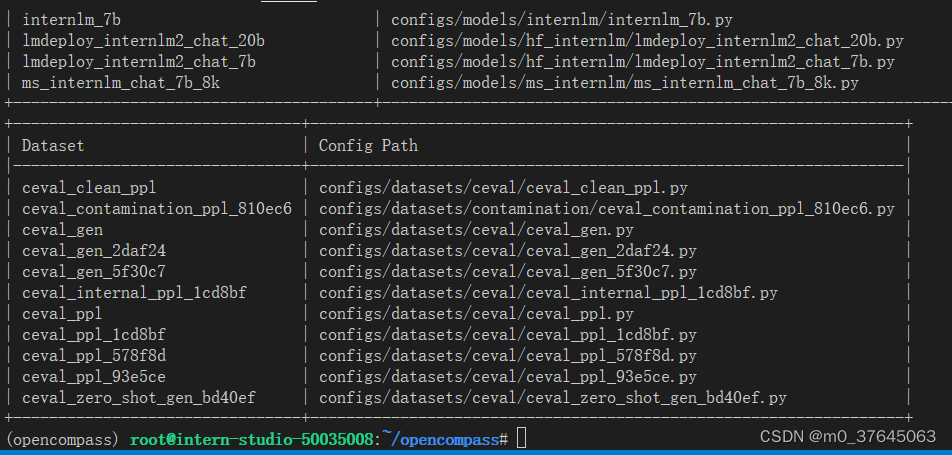
2、列出C-eval配置
知识补充:C-Eval是一个权威的中文AI大模型评测数据集,主要用于考察大模型的知识和推理能力。
- C-Eval由13948道多选题组成,覆盖了人文、社科、理工和其他专业四个大方向,共52个学科小类。
- 题目难度分为四个等级,分别是初中、高中、大学和专业,每个学科对应一个难度等级。
- 题目内容包括STEM(科学、技术、工程和数学教育)、Social Science(社会科学)、Humanity(人文科学)和其他学科大类。
3、修复mkl-service + Intel(R) MKL MKL_THREADING_LAYER=INTEL is incompatible with libgomp.so.1 ..问题后进行评测进程
建议:请将bug修复放在步骤最前面,这个课件很容易使学员进行重复操作
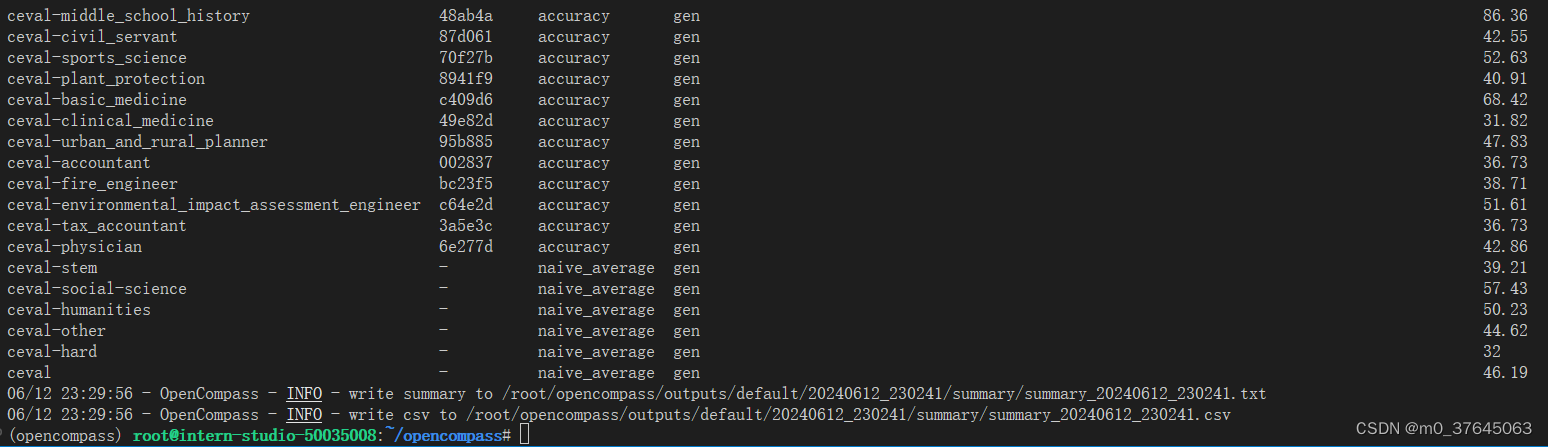
4、得出ceval数据集下的1.8B测评结果
进度条完成后会输出在C-EVAL数据集下模型评测的结果,在最右侧以分数进行表示。















 1161
1161

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









