







目录
1. SparkStreaming
package com.lj.stream
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
object Driver01 {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setMaster("local").setAppName("stream")
val sc=new SparkContext(conf)
//--创建SparkStreaming上下文件对象,用于接收数据源,并生成DStream(离散的数据流)
//--SparkStreaming的批大小是时间单位
val ssc=new StreamingContext(sc,Seconds(5))
//--指定监听的数据源,常用的数据源
//--1.本地数据源
//--2.HDFS数据源
//--3.Kafak数据源
//--4.Socket数据源
val data=ssc.textFileStream("hdfs://lj02:9000/stream")
val result=data.flatMap {_.split(" ")}.map{(_,1)}.reduceByKey{_+_}
result.print
ssc.start
//--保持SparkStreaming一直开启,直到用户手动中断
ssc.awaitTermination()
}
}2. SparkStreaming对历史数据的累加处理
package com.lj.stream
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
/**
* 学习SparkStreaming对历史数据的累加处理
*/
object Driver02 {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setMaster("local").setAppName("stream")
val sc=new SparkContext(conf)
val ssc=new StreamingContext(sc,Seconds(5))
//--为了实现对历史批次数据的累加,需要指定一个目录来存储历史数据
//--路径可以指定在本地,可以指定在HDFS
ssc.checkpoint("file:///data/streamData")
val data=ssc.textFileStream("hdfs://lj02:9000/stream")
val r1=data.flatMap { _.split(" ") }.map { (_,1)}
val r2=r1.updateStateByKey{(seq,op:Option[Int])=>Some(seq.sum+op.getOrElse(0))}
r2.print
ssc.start()
ssc.awaitTermination()
}
}3. SparkStreaming的滑动窗口机制
package com.lj.stream
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
/**
* 学习SparkStreaming的滑动窗口机制
* 应用场景:每隔一段时间(滑动区间)计算下一个段时间(窗口长度)的数据
*/
object Driver03 {
def main(args: Array[String]): Unit = {
val conf=new SparkConf().setMaster("local").setAppName("stream")
val sc=new SparkContext(conf)
val ssc=new StreamingContext(sc,Seconds(5))
//--窗口机制也是需要对历史数据累加,所以也需要指定目录
ssc.checkpoint("f://data/windowdata")
val data=ssc.textFileStream("hdfs://lj02:9000/stream")
val r1=data.flatMap { _.split(" ") }.map { (_,1)}
//--①参:匿名函数,指定key的value需要如何计算 ②参:滑动区间 ③参:窗口长度
val r2=r1.reduceByKeyAndWindow((a:Int,b:Int)=>a+b,Seconds(10),Seconds(10))
r2.print
ssc.start
ssc.awaitTermination()
}
}4. 将Kafka和SparkStreaming整合
1. 准备工作
启动zookeeper
[root@lj02 home]# cd /home/software/zookeeper-3.4.8/bin/
[root@lj02 bin]# sh zkServer.sh start
启动kafka
[root@lj01 ~]# cd /home/software/kafka_2.11-1.0.0/bin/
[root@lj01 bin]# sh kafka-server-start.sh ../config/server.properties
[root@lj01 bin]# sh kafka-topics.sh --list --zookeeper lj02:2181 //查看主题
![]()
2. 导jar包:
整合jar:spark-streaming-kafka-0-8_2.11-2.2.0.jar
spark的所有jar
kafka的所有jar
package com.lj.stream.kafka
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
import org.apache.spark.streaming.StreamingContext
import org.apache.spark.streaming.Seconds
import org.apache.spark.streaming.kafka.KafkaUtils
/**
*
* 将Kafka和SparkStreaming整合
*/
object Driver {
def main(args: Array[String]): Unit = {
//--如果用spark本地单机模式去消费kafka数据
//--注意:local[N] N表示启动的线程数,至少是2个。
//--其中一个线程负责运行SparkStreaming,另外一个线程负责消费Kafka数据
//--如果只有一个线程,则消费不到Kafka数据
val conf=new SparkConf().setMaster("local[2]").setAppName("streamkafka")
val sc=new SparkContext(conf)
val ssc=new StreamingContext(sc,Seconds(5))
//--指定zk集群列表
val zkHosts="lj01:2181,lj02:2181,lj03:2181"
//--指定消费者组名
val group="gp1"
//--指定消费的主题,key是主题名,value是消费的线程数
val topics=Map("music"->1,"enbook"->1)
//--通过工具类去消费Kafka数据
val data=KafkaUtils.createStream(ssc, zkHosts, group, topics)
.map{x=>x._2}
data.print
ssc.start
ssc.awaitTermination()
}
}结果:
创建生产者
[root@lj01 bin]# sh kafka-console-producer.sh --broker-list lj01:9092 --topic lj
![]()
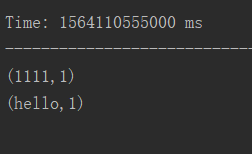
代码结果
















 2148
2148











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









