







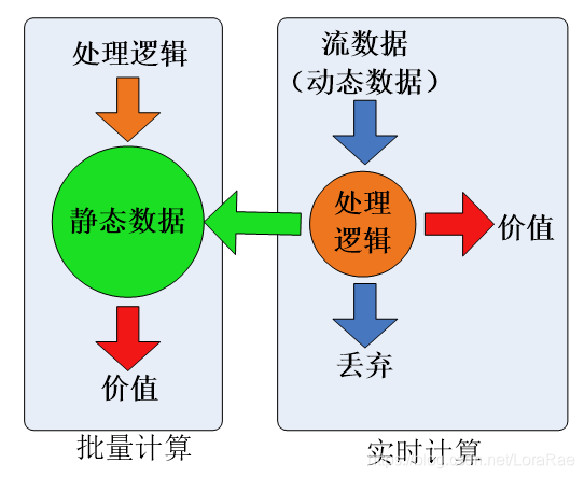
1 分布式流数据处理概述
流处理本质上是一种特殊形式的并行计算,它被设计用于数据只能处理一次的情况。这些并行计算环境多数实现在一个不可靠的网络层之上,这样的网络层会引入高得多的错误率。
• 协调:流框架的核心,存储用于拓扑处理的相关信息,同时处理一些分区任务,Zookeeper。
• 分区和融合:流处理系统的核心元素是分散-收集(scatter-gather)机制的某种实现,流处理应用的各种组件之间的数据交换通常是点对点形式。一个组件知道它必须生成数据供别的组件消费,多数系统会建立 处理单元间的数据传送机制,并在计算的每个阶段控制并行度。
• 事务:实时框架中事务处理的基本机制是回滚和重试,事务的维护会给系统带来巨大开销。如果没有事务也可以运行,那就不要用事务。
对于一个流计算系统来说,它应达到如下需求:
• 高性能:处理大数据的基本要求,如每秒处理几十万条数据
• 海量式:支持TB级甚至是PB级的数据规模
• 实时性:保证较低的延迟时间,达到秒级别,甚至是毫秒级别
• 分布式:支持大数据的基本架构,必须能够平滑扩展
• 易用性:能够快速进行开发和部署
• 可靠性:能可靠地处理流数据。
2 Storm分布式实时处理系统
Map reduce框架:主节点job tracker,从节点task tracker,用户提交任务给job tracker,job tracker分配给task Tracker,我们管这些任务叫job,运行的作业分为两种map 和reduce。
Storm:一个实时计算框架主节点 nimbus 从节点 supervisor用户提交作业给nimbus,nimbus把任务分配给supervisor,这些提交的任务就是topology(拓扑)运行的作业分为两种spout和bolt。Storm是流式的处理既stream,stream的内容是tuple(元组)

“经典”Storm:将应用构造为名为拓扑(topology)的有向无环图(Directed Acyclic Graph,DAG)。
Trident(推荐):是对拓扑的高层次抽象,该模型更聚焦于聚集和持久化这些常见操作
Storm组件
Storm集群由三个服务器守护进程组成,分别是ZooKeeper、nimbus和supervisor,这三个进程都必须正常运行。
ZooKeeper:分布式Storm集群依靠ZooKeeper进行协调,跟踪所有运行着的拓扑,以及所有supervisor的状态;
nimbus:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









