







在从事数据分析过程中,经常接触一些大数据平台的概念,但由于不是计算机专业背景,刚开始看这些专业名词的时候还是比较迷糊。
最近看了一些关于hadoop生态系统的材料,本文是对这些文章材料的总结,希望可以形成对于该领域的知识体系。
1、系统架构图
hadoop 1.0:
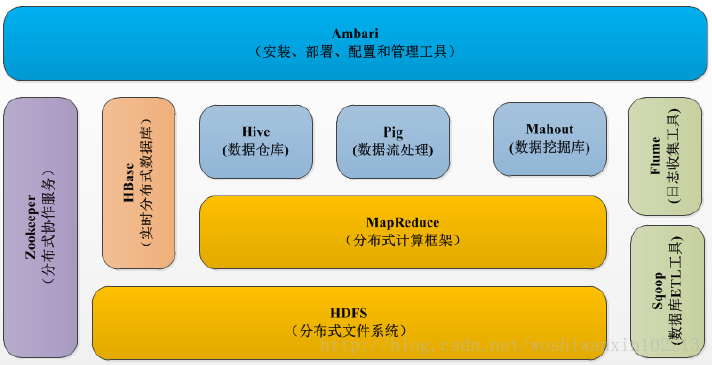
hadoop 2.0:
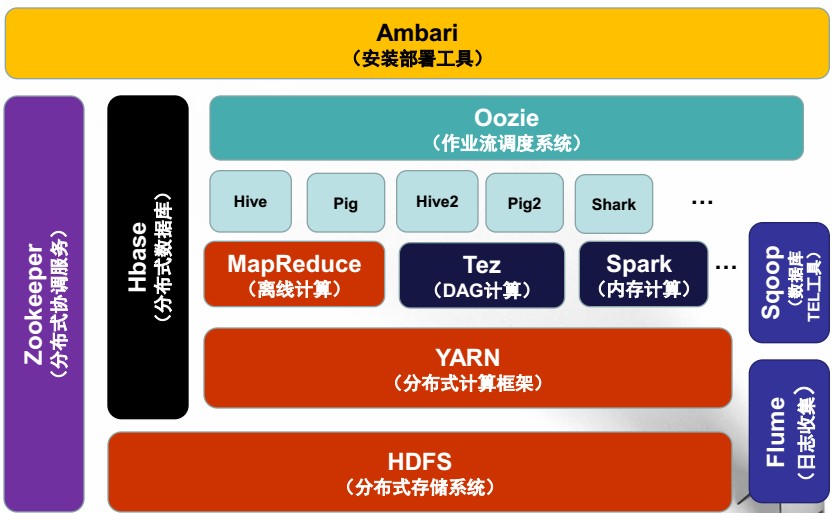
2、HDFS,分布式文件系统
HDFS是hadoop体系中最基础的系统,用于数据文件的存储和管理。
传统的文件存储系统是在单机上的,不能跨越不同的机器。而分布式文件系统可以连接成千上万机器,把数据平均分散存储到很多机器上,并且提供统一的管理方式。
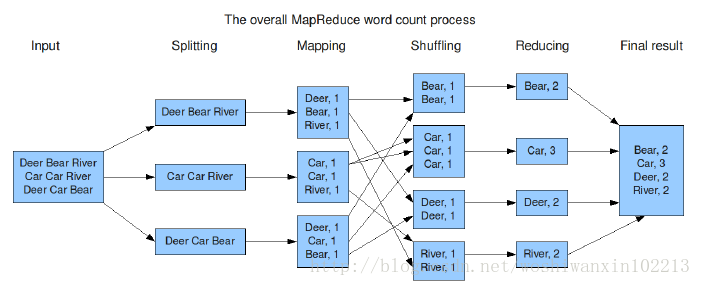
3、MapReduce,分布式计算框架
核心原理就是Map和Reduce,思想上就是把一个大的计算逻辑进行分解,然后将这些分解的结果进行汇总,即先分解任务,分工处理后再汇总结果。一个Map加一个Reduce就是一个Job,对于一个很复杂的逻辑,其实可以分解为很多Job,所有Job连起来实现复杂逻辑。
4、Hive(基于hadoop的数据仓库)、Pig(基于hadoop的数据流系统)
由于MapReduce是一个底层计算框架,要完成数据的分析处理工作,还是要进行一定的编码。所以需要有更高层、更抽象的语言层来描述算法和数据处理流程,将编码变得更加通用,使用更简单直观的语言编写程序。目前Hadoop中比较流程的有Hive和Pig。
Hive定义了一种类似SQL的查询语言(HQL),将SQL转化为MapReduce任务在hadoop上执行。
Pig则是将脚本转化为MapReduce任务在hadoop上执行。
Hive和Pig通常用于离线分析。
而SparkSQL是在Spark上实现SQL的解决方案。
5、Mahout(数据挖掘算法库)
Mahout的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加便捷地创建智能应用程序。
现在已经包含了聚类、分类、推荐引擎和频繁项集等广泛应用的数据挖掘方法。
除了算法,还包含数据的输入/输出工具、与其他存储系统集成等数据挖掘支持架构。
6、Hbase(分布式数据库)
HBase是一种构建在HDFS之上的面向列的分布式存储系统,优点在于可以实现高性能的并发读写操作,同时Hbase还会对数据进行透明的切分,这样使得存储本身具有水平伸缩性。
以key-value的形式存储数据,列可以动态增加,列为空就不占用空间,是NoSQL的典型代表产品。
适用于实时计算。
这位大哥关于HBase的解释讲得挺清晰易懂的。
https://zhidao.baidu.com/question/650211189221525965.html
7、Zookeeper(分布式协作服务)
8、Sqoop(数据同步工具)
是SQL- to - Hadoop的缩写,主要是传统数据库和Hadoop之间的桥梁,用于数据传输。
数据的导入和导出本质上是MapReduce程序,充分利用了MR的并行化和容错性。
9、Flume(日志收集工具)
Cloudera开源的日志收集系统。
将数据从产生、传输、处理并最终写入目标路径的过程抽象为数据流,在具体的数据流中,数据源支持在Flume中定制数据发送方,从而支持收集各种不同协议数据,同时,Flume数据流提供对日志数据进行简单处理的能力,如过滤、格式转换等。此外,Flume还具有能够将日志写往各种数据目标(可定制)的能力。总的来说,Flume是一个可扩展、适合复杂环境的海量日志收集系统。
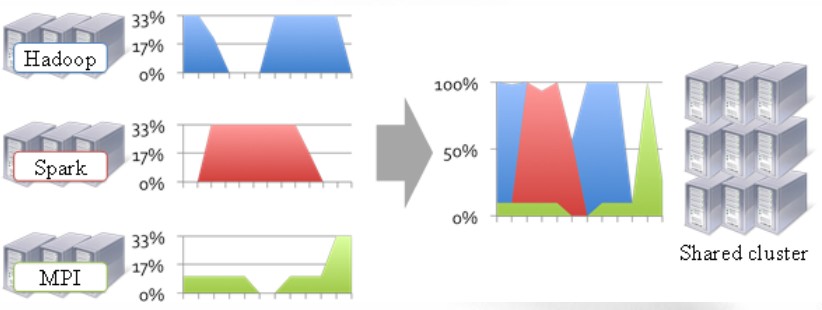
10、Yarn(资源管理系统)
Yarn是hadoop 2.0新增的系统,负责集群的资源管理和调度,使得多重计算框架可以运行在一个集群中。
11、Oozie(作业流调度系统)
对不同的计算框架和作业机型统一管理和调度,包括MapReduce、Stream、HQL、Pig等,这些作业之间存在依赖关系,同时包括周期性作业、定时执行作业、作业执行状态监控与报警。
Spark相关内容将在《Spark简介和总结》文章中详细阐述。
参考文章:
Hadoop生态系统介绍:http://blog.csdn.net/woshiwanxin102213/article/details/19688393
Hadoop生态系统:http://blog.csdn.net/u010270403/article/details/51493191
大数据技术生态:http://www.jianshu.com/p/fe97a452801a















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









