






HAT: Overcoming Catastrophic Forgetting with Hard Attention to the Task(ICML, 2018)
HAT:通过对任务的集中注意力来克服灾难性遗忘
目录
传送门
Abstract摘要
灾难性遗忘发生在神经网络在后续任务训练后丢失在前一个任务中学习到的信息。这个问题对于具有顺序学习能力的人工智能系统来说仍然是一个障碍。在本文中,我们提出了一种基于任务的硬注意力机制,它可以在不影响当前任务学习的情况下保留之前任务的信息
通过随机梯度下降,对每个任务同时学习硬注意力掩码,并且利用以前的掩码来调节这种学习。我们表明,所提出的机制对于减少灾难性遗忘是有效的,将当前的遗忘率降低了45%到80%。我们还展示了它对于不同超参数选择的鲁棒性,并且它提供了许多监控功能。该方法具有控制所学习知识的稳定性和紧凑性的可能性,我们认为这对在线学习或网络压缩应用也有吸引力。
1.Introduction
2.Putting Hard Attention to the Task 把注意力集中在任务上
2.1Motivation 动机
推动提出的方法的主要观察是,任务定义,或者更实用地说,它的标识符,对网络的运行至关重要。考虑区分鸟和狗图像的任务,当训练网络这样做时,它可能会学习一些中间特征集。如果第二个任务是使用相同的数据来区分棕色和黑色动物(假设它只包含棕色或黑色的鸟类和狗),网络可能会学习到一组新的特征,其中一些特征与第一个特征没有太多重叠。因此,如果两个任务中的训练数据相同,一个重要的区别应该是任务描述或标识符。我们的目的是学习使用任务标识符来调节每一层,并在以后利用这种习得的条件作用来防止忘记以前的任务。
2.2Architecture 体系结构
为了满足当前任务t的条件,我们采用分层注意机制(图1)。给定层l, hl的单元2的输出,我们按元素乘以h0l = atl ?hl。然而,与普通注意力机制的一个重要区别是,atl不是形成概率分布,而是嵌入etl的单层任务的门控版本,
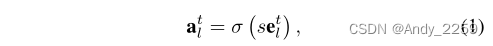
其中σ(x)∈[0,1]是门函数,s是正的标度参数。我们在实验中使用的是s型门,但也可以使用其他门控机制。所有层l = 1,…L−1除了最后一层,即L层之外,其他操作相同,其中atL是二进制硬编码的。层L的操作相当于一个多头输出(Bakker & Heskes, 2003),通常用于灾难性遗忘的背景下(例如Rusu等人,2016;Li & Hoiem, 2017;Nguyen等人,2017)。
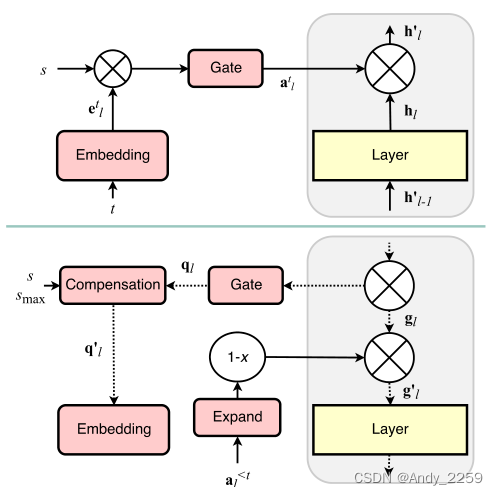
Figure 1. Schematic diagram of the proposed approach: forward
(top) and backward (bottom) passes.
图1。所提出的方法的示意图:向前(上)和向后(下)通过。
公式1的门控机制背后的思想是形成硬的、可能是二元的注意力面具,充当“抑制突触”(McCulloch & Pitts, 1943),因此可以激活或禁用每一层单元的输出
通过这种方式,类似于PathNet (Fernando et al., 2017),我们动态地创建和破坏跨层的路径,这些路径可以在学习新任务时保存下来。然而,与PathNet不同的是,HA T中的路径不是基于模块,而是基于单个单元。因此,我们不需要预先分配模块大小,也不需要为每个任务设置模块的最大数量。给定一些网络架构,HA T学习并自动对单个单元路径进行维度,最终影响单个层的权重。此外,HA T不是使用遗传算法在单独的阶段学习路径,而是使用反向传播和SGD与网络的其余部分一起学习它们。
2.3Network Training 网络训练
为了在学习新任务时保留在以前任务中学习到的信息,我们根据以前所有任务的累积注意力来调整梯度。为了获得累积注意向量,在学习任务t并获得atl后,再进行递归计算
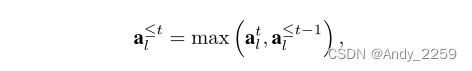
对于≤0 l使用元素最大值和全零向量。这保留了对以前任务很重要的单元的注意力值,使它们能够调节未来任务的训练。
为了调节任务t + 1的训练,我们修改了第l层的梯度gl,ij,与当前和前一层的累积注意力最小值相反:
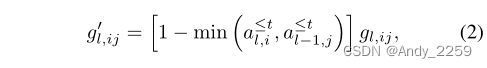
其中,单位指标I和j分别对应于输出(l)和输入(l−1)层。换句话说,我们展开向量a≤t l和a≤t l−1,以匹配层l的梯度张量的维度,然后执行逐元素的最小值、减法和乘法(图1)。如果输入数据由图像或音频等复杂信号组成,我们不计算对输入数据的任何关注。然而,如果这些数据是由独立的或独立的特征组成的,也可以将它们视为某些层的输出,并应用相同的方法。
请注意,在公式2中,我们创建掩码以防止对先前任务重要的权重进行大规模更新
这与在HA t开发期间公开的PackNet (Mallya & Lazebnik, 2017)的方法类似。在PackNet中,经过启发式选择和重新训练后,找到一个二进制掩码,然后应用于冻结相应的网络权重。在这方面,HA T与PackNet有三个重要的不同之处。首先,我们的蒙版是基于单位的,基于权重的蒙版是自动从单位衍生出来的。因此,HA T也存储和维持了一种轻量级结构。其次,我们的面具是习得的,而不是启发式或规则驱动的。因此,HA T不需要预先分配压缩比,也不需要通过后训练步骤确定参数的重要性。第三,我们的掩码不一定是二进制的,允许0到1之间的中间值。如果我们想重用权重来学习其他任务,以牺牲一些遗忘为代价,或者我们想在更在线的模式下工作,忘记旧的任务来记住新任务,这可能是有用的。
2.4Hard Attention Training 硬注意力训练
为了得到一个完全二元的注意向量atl,可以使用单位阶跃函数作为门。然而,由于我们想用反向传播训练嵌入etl(图1),我们更喜欢可微函数。为了构造一个允许梯度流动的伪阶跃函数,我们使用一个具有正缩放参数s的sigmoid (Eq. 1)。引入这个缩放是为了控制伪阶跃函数的极化或“硬度”以及最终输出atl。我们的策略是在训练期间退火s,诱导梯度流,并在测试期间设置s = smax,使用smax ?使方程1近似于单位阶跃函数。注意,当s→∞时,我们得到atl,i→{0,1},当s→0时,我们得到atl,i→1/2。我们将使用后者来开始一个训练epoch,所有的网络单元都是同样活跃的,并在epoch内逐步极化它们。
在训练阶段,我们增量线性退火s的值
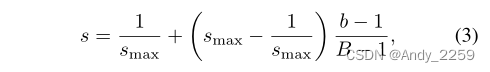
其中b = 1,…B是批索引,B是一个epoch中的批总数。超参数smax≥1控制学习任务的稳定性,换句话说,控制网络单元的可塑性。如果smax接近于1,那么门控机制就像常规的sigmoid函数一样工作,而不需要特别强制atl的二值化。这为单元提供了可塑性,模型能够在反向传播阶段忘记之前的任务(第2.3节)。反之,如果smax是一个较大的数字,则浇注机制开始作为单位阶跃函数运行
这为之前学习的任务提供了稳定性,防止了反向传播阶段相应权重的变化。
2.5Embedding Gradient Compensation 嵌入梯度补偿
在初步分析中,我们经验地观察到嵌入etl变化不大,并且在这些权重上梯度的大小较弱。经过一些研究,我们意识到问题的主要部分是由于引入的退火方案(Eq. 3)。为了说明退火方案对etl梯度的影响,考虑一个均匀分布的嵌入etl,i横跨标准sigmoid的活动范围,etl,i∈[−6,6]。如果我们不执行任何退火和集合s = 1,我们获得一个累积梯度后一个时代有一个钟形的形状和跨越整个乙状结肠范围(图2)。与之相反,如果我们集合s = smax,我们获得更大的规模,但在一个更低的范围(etl、我∈(−1,1)图2)。退火版本年代收益率分布的中间,有一个较低的范围比s = 1,低于s = smax大小
理想的情况是有一个大的范围,理想地跨越s = 1的范围,并且有一个大的累积震级,理想地与s = smax时活动区域的震级成正比。为了实现这一点,我们在更新etl之前应用梯度补偿。
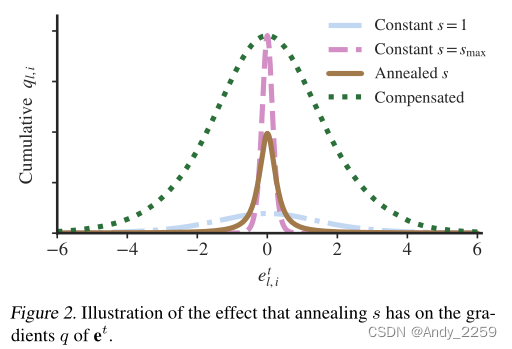
图2。说明了退火s对et的梯度q的影响。
从本质上讲,嵌入梯度补偿的思想是去除退火的sigmoid的影响,并人为地施加上一段所激励的期望范围和幅度。为此,我们用梯度ql,i除以经过退火处理的sigmoid的导数,再乘以所需的补偿,
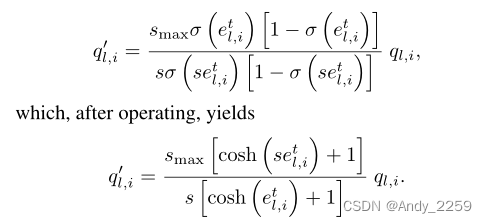
为了数值稳定性,我们钳制|setl,i|≤50,并约束etl,i保持在标准sigmoid, etl,i∈[−6,6]的活动范围内。无论如何,ql,i→0当我们达到这些极限时。也就是说,我们在伪阶跃函数的常数区域。还要注意,通过公式3,s的最小值永远不等于0。
2.6Promoting Low Capacity Usage 促进低容量使用
重要的是要认识到“活动”的硬注意值atl,i,即atl,i→1,直接决定了将用于任务t的单元。因此,为了为未来的任务保留一些模型容量,我们在注意向量集At = {at1,…atL−1}。为此,我们在损失函数L中添加了一个正则化项,该项考虑了到任务t−1为止的累积注意向量集,
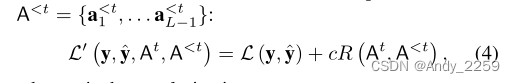
其中c是正则化常数,
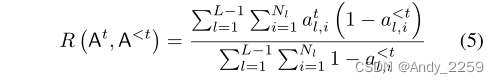
为正则化项,Nl对应于层l中的单元数。注意,式5对应于在At上的加权和归一化L1正则化。
这排除了正则化以前任务中参与的单元,从而在当前任务中不受约束地重用它们。超参数c≥0控制了每个任务所花费的容量(Eq. 4)。在某种意义上,它可以被认为是一个压缩常数,影响学习模型的紧凑性:c越高,主动注意值atl、i的数量越少,得到的网络越稀疏。我们为所有任务设置全局c,并让HA T适应每个单独任务的最佳压缩。
Y oon等人(2018)也考虑过在灾难性遗忘的背景下使用L1正则化来促进网络稀疏性,动态可扩展网络(DEN)是在开发HA t时引入的。在DEN中,plain L1正则化与相当多的启发式方法相结合,如l2转移、阈值和“语义漂移”测量,并应用于所谓的“选择性再训练”阶段的所有网络权重。在HA T中,我们在注意值上使用注意加权L1正则化,这是该方法单一训练阶段的独立部分。HA T不考虑网络权重,而是关注单位注意力。
3.Related Work
4.Experiments
5.Conclusion
我们引入了硬注意力机制HA T,通过关注任务嵌入,能够在学习新任务的同时保护之前任务的信息。这种硬注意力机制是轻量级的,从某种意义上说,它向基础网络添加了一小部分权重,并与主模型一起训练,使用反向传播和香草SGD的开销可以忽略不计。通过使用多个数据集和最先进的方法进行一系列实验,我们证明了在图像分类环境中控制灾难性遗忘的方法的有效性。HA T只有两个超参数,直观地表示学习知识的稳定性和紧凑性,我们演示的它们的调优对于获得良好的性能并不重要。此外,HA T提供了监视跨任务和层使用的网络容量、跨任务的单元重用以及为给定任务训练的模型的可压缩性的可能性
我们希望我们的方法在在线学习或网络压缩环境中也有用,这里提出的硬注意力机制也可能在灾难性遗忘问题之外找到一些适用性。
















 1862
1862











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









