




 本文介绍了如何在Ubuntu20.04环境中部署商业版GPT模型ChatGLM3-6b,包括安装必要的软件依赖,从modelscope下载和调用模型,以及如何进行微调,特别是针对不同硬件环境(如V100显卡)的配置和常见问题的解决方案。
本文介绍了如何在Ubuntu20.04环境中部署商业版GPT模型ChatGLM3-6b,包括安装必要的软件依赖,从modelscope下载和调用模型,以及如何进行微调,特别是针对不同硬件环境(如V100显卡)的配置和常见问题的解决方案。
chatglm3-6b部署及微调
插播:如果你想私有化部署商业版gpt
演示地址:https://chat.apeto.cn
项目介绍:点我直达
- modelscope: https://modelscope.cn/models/ZhipuAI/chatglm3-6b/files
- github: https://github.com/THUDM/ChatGLM3
- 镜像: ubuntu20.04-cuda11.7.1-py38-torch2.0.1-tf1.15.5-1.8.1
- v100 16G现存 单卡
安装
软件依赖
# 非必要无需执行
# pip install --upgrade pip
pip install modelscope>=1.9.0
下载及调用
from modelscope import AutoTokenizer, AutoModel, snapshot_download
model_dir = snapshot_download("ZhipuAI/chatglm3-6b", revision = "v1.0.2")
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModel.from_pretrained(model_dir, trust_remote_code=True).half().cuda()
model = model.eval()
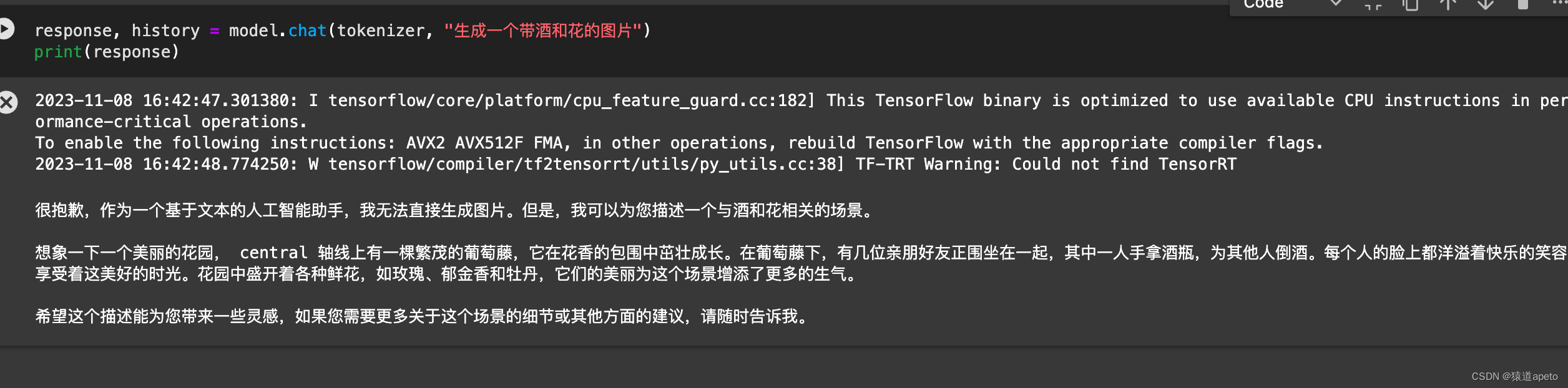
response, history = model.chat(tokenizer, "你好", history=[])
print(response)
response, history = model.chat(tokenizer, "晚上睡不着应该怎么办", history=history)
print(response)
微调
数据集: https://modelscope.cn/datasets/damo/MSAgent-Bench/summary
项目: https://github.com/modelscope/swift
项目下载
mkdir py
git clone https://github.com/modelscope/swift.git
cd swift
安装依赖:
# 已安装忽略
pip install ms-swift
# 已安装忽略
pip install modelscope>=1.9.0
# 设置pip全局镜像和安装相关的python包
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
git clone https://github.com/modelscope/swift.git
cd swift
pip install .[llm]
# 下面的脚本需要在此目录下执行
cd examples/pytorch/llm
# 如果你想要使用deepspeed
pip install deepspeed -U
# 如果你想要使用基于auto_gptq的qlora训练. (推荐, 效果优于bnb)
# 使用auto_gptq的模型: qwen-7b-chat-int4, qwen-14b-chat-int4, qwen-7b-chat-int8, qwen-14b-chat-int8
pip install auto_gptq optimum -U
# 如果你想要使用基于bnb的qlora训练.
pip install bitsandbytes -U
脚本sft.sh
sft.sh
将脚本放在swift/examples/pytorch/llm/scripts/chatglm3_6b/lora_ddp_ds这个目录下
- 单显卡: CUDA_VISIBLE_DEVICES=0
- 模型ID: model_id_or_path ZhipuAI/chatglm3-6b
- 模型版本: model_revision v1.0.2
- dtype: 如果是老显卡比如V100 是不支持bf16的 需要指定为: fp16
- 模板类型: template_type chatglm3
- 数据集: dataset damo-agent-mini-zh 这里采用达摩院的agent
- lora_rank和lora_alpha 注意: lora_alpha一定要是lora_rank 2倍质量最高
- hub_token: 你的modelscope平台的token该参数只有在push_to_hub设置为True时才生效.
- gradient_accumulation_steps 根据显卡性能调整 v100 我这里用的16 高级显卡可以设置32
- max_length 根据显卡性能调整 v100我这里用的是2048 高级显卡可以调整成4096
- 剩余其他参数默认即可
# v100 16G 单卡
nproc_per_node=1
PYTHONPATH=../../.. \
CUDA_VISIBLE_DEVICES=0 \
torchrun \
--nproc_per_node=$nproc_per_node \
--master_port 29500 \
llm_sft.py \
--model_id_or_path ZhipuAI/chatglm3-6b \
--model_revision v1.0.2 \
--sft_type lora \
--tuner_backend swift \
--template_type chatglm3 \
--dtype fp16 \
--output_dir output \
--dataset damo-agent-mini-zh \
--train_dataset_sample -1 \
--num_train_epochs 1 \
--max_length 2048 \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout_p 0.05 \
--lora_target_modules AUTO \
--gradient_checkpointing true \
--batch_size 1 \
--weight_decay 0. \
--learning_rate 1e-4 \
--gradient_accumulation_steps 16 \
--max_grad_norm 0.5 \
--warmup_ratio 0.03 \
--eval_steps 100 \
--save_steps 100 \
--save_total_limit 2 \
--logging_steps 10 \
--push_to_hub false \
--hub_model_id chatglm3-6b-lora \
--hub_private_repo true \
--hub_token 'token' \
--deepspeed_config_path 'ds_config/zero2.json' \
--only_save_model true \
运行脚本
注意: 要在 swift/examples/pytorch/llm 这个目录下进行 记得给脚本权限chmod +x llm/*.py
./scripts/chatglm3_6b/lora_ddp_ds/sft.sh
推理
infer.sh
将脚本放在swift/examples/pytorch/llm/scripts/chatglm3_6b/lora_ddp_ds这个目录下
# Experimental environment: v100
PYTHONPATH=../../.. \
CUDA_VISIBLE_DEVICES=0 \
python llm_infer.py \
--model_id_or_path ZhipuAI/chatglm3-6b \
--model_revision v1.0.2 \
--sft_type lora \
--template_type chatglm3 \
--dtype fp16 \
# --ckpt_dir "output/chatglm3-6b/vx_xxx/checkpoint-xxx" \
--eval_human false \
--dataset damo-agent-mini-zh \
--max_length 2048 \
--max_new_tokens 2048 \
--temperature 0.9 \
--top_k 20 \
--top_p 0.9 \
--do_sample true \
--merge_lora_and_save false \
常见问题
1.显卡驱动
RuntimeError: The NVIDIA driver on your system is too old (found version 11080). Please update your GPU driver by downloading and installing a new version from the URL: http://www.nvidia.com/Download/index.aspx Alternatively, go to: https://pytorch.org to install a PyTorch version that has been compiled with your version of the CUDA driver.
解决方案
错误提示显卡驱动较老 其实可能是torch版本太高导致的问题 我们用的是2.0.1 请检查你的版本是否是2.0.1
https://pytorch.org/get-started/previous-versions/
# 查看torch版本
python
import torch
print(torch.__version__)
# 查看CUDA版本
nvidia-smi
# 卸载过高的版本
pip uninstall torch
# 访问官方查看对应版本: https://pytorch.org/get-started/previous-versions/ 以cuda 11.8 pytorch:2.0.1 举例
conda install pytorch==2.0.1 torchvision==0.15.2 torchaudio==2.0.2 pytorch-cuda=11.8 -c pytorch -c nvidia




















 2959
2959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











