






今天介绍一下关于短的算法,短位UUID和短文本相似度。
短位UUID
uuid虽好,但是长度和内容不规则一直被当做它的诟病。本司目前业务中使用到了uuid然后存储在磁盘中。由于一份文件中使用的id数目不会超过1w左右,因此对文件瘦身处理时,uuid可以是处理的对象之一,使用短位uuid来取代。
import uuid
BASE_CHARS = 'abcdefghijklmnopqrstuvwxyz0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZ'
class ShortUUID:
def _gen_short_id(self):
u_id = str(uuid.uuid4()).replace("-", '')
buffer = []
for idx in range(0, 8):
start = idx * 4
end = idx * 4 + 4
val = int(u_id[start:end], 16)
buffer.append(BASE_CHARS[val % 0x3E])
return "".join(buffer)
if __name__ == '__main__':
count = 0
index = []
id_set = set()
short_uuid = ShortUUID()
for i in range(0, 10000000):
u_id = short_uuid._gen_short_id()
if u_id in id_set:
count += 1
index.append(str(i+1))
else:
id_set.add(u_id)
print(f"重复数:{count},重复率:{count / 10000000}")
本机测试生成1千万次id,存在一个重复。通过uuid生成的32位字符串中截取8位出来当作id使用,进制是62进制。百万级以下基本很难出现冲突,所以针对当前几千到几万不等的一份id是完全可以的。

短文本相似度
小薛的备忘录:
1.1:早点下班
1.2:回家做饭
小孟的备忘录:
第一件:早点下班
第二件:回家吃饭
小薛的 早点下班 和小孟的 早点下班 其实算是一个意思,只是前面有点前缀干扰。
import re
from simhash import Simhash
class ShortTextSimilarity:
# Levenshtein编辑距离
def _levenshtein(self, str1, str2):
len_str1 = len(str1) + 1
len_str2 = len(str2) + 1
matrix = [0 for n in range(len_str1 * len_str2)]
for i in range(len_str1):
matrix[i] = i
for j in range(0, len(matrix), len_str1):
if j % len_str1 == 0:
matrix[j] = j // len_str1
for i in range(1, len_str1):
for j in range(1, len_str2):
if str1[i - 1] == str2[j - 1]:
cost = 0
else:
cost = 1
matrix[j * len_str1 + i] = min(matrix[(j - 1) * len_str1 + i] + 1,
matrix[j * len_str1 + (i - 1)] + 1,
matrix[(j - 1) * len_str1 + (i - 1)] + cost)
edit_num = matrix[-1]
return 1 - edit_num / max(len(str1), len(str2))
# Jaccard相似度
def _jaccard(self, text1, text2):
char_set_1 = set(text1)
char_set_2 = set(text2)
union_char_set = char_set_1 & char_set_2
intersect_char_set = char_set_1 | char_set_2
return len(union_char_set) / len(intersect_char_set)
# Simhash
def _sim_hash(self, text1, text2):
a_simhash = Simhash(text1)
b_simhash = Simhash(text2)
max_hashbit = max(len(bin(a_simhash.value)), len(bin(b_simhash.value)))
distince = a_simhash.distance(b_simhash)
return 1 - distince / max_hashbit
# 最长公共子序列(LCS)
def _lcs_similarity(self, str_a, str_b):
lengths = [[0 for j in range(len(str_b) + 1)] for i in range(len(str_a) + 1)]
for i, x in enumerate(str_a):
for j, y in enumerate(str_b):
if x == y:
lengths[i + 1][j + 1] = lengths[i][j] + 1
else:
lengths[i + 1][j + 1] = max(lengths[i + 1][j], lengths[i][j + 1])
result = ""
x, y = len(str_a), len(str_b)
while x != 0 and y != 0:
if lengths[x][y] == lengths[x - 1][y]:
x -= 1
elif lengths[x][y] == lengths[x][y - 1]:
y -= 1
else:
assert str_a[x - 1] == str_b[y - 1]
result = str_a[x - 1] + result
x -= 1
y -= 1
longestdist = lengths[len(str_a)][len(str_b)]
ratio = longestdist / min(len(str_a), len(str_b))
return ratio
if __name__ == "__main__":
threshold = 0.8
ori_str = '1.1:早点下班'
tar_str = '第一件:早点下班'
short_text_similarity = ShortTextSimilarity()
levenshtein_similarity = short_text_similarity._levenshtein(ori_str, tar_str)
jaccard_similarity = short_text_similarity._jaccard(ori_str, tar_str)
sim_hash_similarity = short_text_similarity._sim_hash(ori_str, tar_str)
lcs_similarity_similarity = short_text_similarity._lcs_similarity(ori_str, tar_str)
print(f"Levenshtein: {levenshtein_similarity}, 是否相似: {levenshtein_similarity > threshold}")
print(f"Jaccard: {jaccard_similarity}, 是否相似: {jaccard_similarity > threshold}")
print(f"Simhash: {sim_hash_similarity}, 是否相似: {sim_hash_similarity > threshold}")
print(f"LCS: {lcs_similarity_similarity}, 是否相似: {lcs_similarity_similarity > threshold}")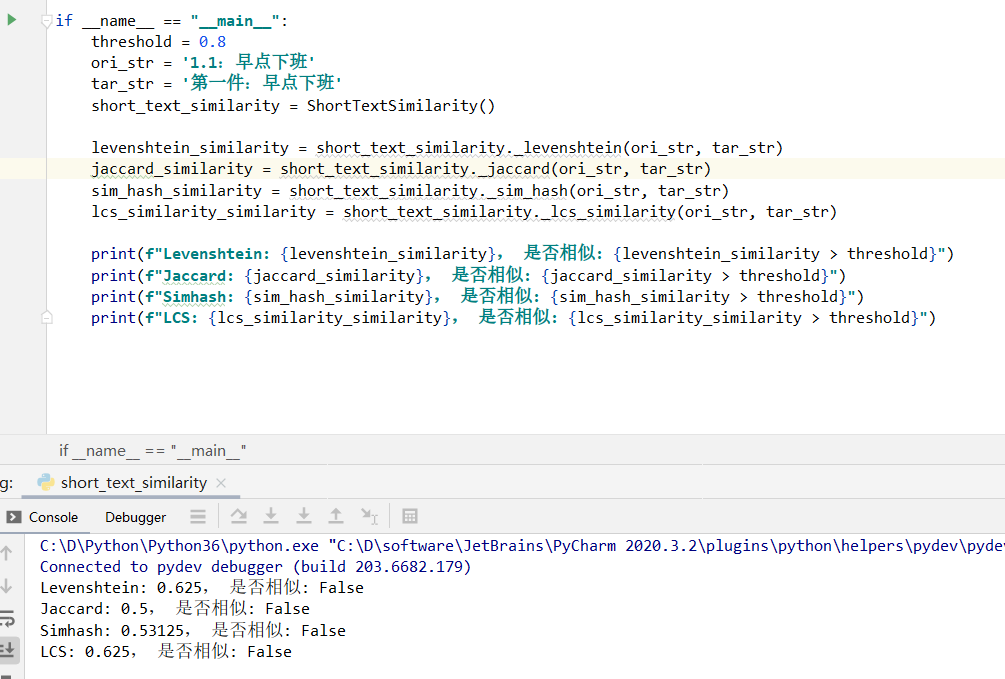
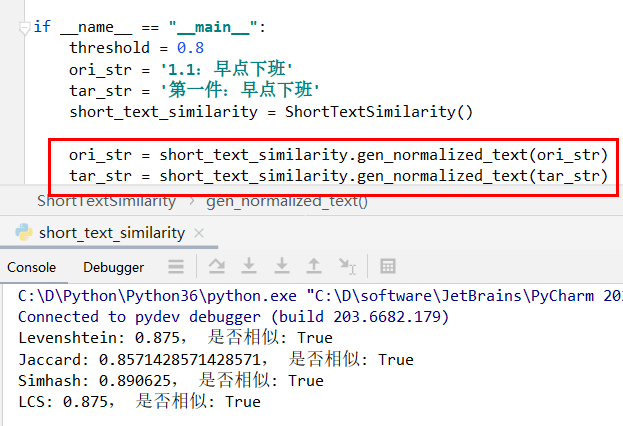
设置即使阈值设置0.7也是全军覆没,所以需要加点前置处理,给ShortTextSimilarity增加一个方法。
@staticmethod
def gen_normalized_text(text):
re_num = re.compile(r'[0-9IVX]+')
re_num_Chinese = re.compile(r'[零一二三四五六七八九十]+')
re_special_char = re.compile(r'[第件]+')
text = re_num.sub('D', text)
text = re_num_Chinese.sub('D', text)
text = re_special_char.sub('D', text)
return text
gitee: https://gitee.com/mjTree/MyPython/tree/master/algorithm

亚洲象
亚洲象:属于长鼻目、象科。亚洲象是亚洲现存的最大陆生动物,长达1米多的象牙,是雄象上颌突出口外的门齿,也是强有力的防卫武器。象的眼小耳大,四肢粗大强壮,尾短而细,皮厚多褶皱,全身稀疏短毛。体长5~6米,身高2.1~3.6米,体重达3~5吨。
亚洲象栖于亚洲南部热带雨林、季雨林及林间的沟谷、山坡、稀树草原、竹林及宽阔地带。喜群居,每群数头、数十头不等。在早、晚及夜间,亚洲象会外出觅食,它们主要食用草、树叶、嫩芽、树皮、竹笋、野芭蕉和棕叶芦等,也会吃农作物如香蕉和甘蔗。
野生象现已很少,中国的野生象仅分布于云南省南部与缅甸、老挝相邻的边境地区,数量十分稀少,屡遭猎杀,破坏十分严重。
属于国家一级保护动物。
















 1109
1109











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









