







 文章详细阐述了Oracle数据库中LGWR进程如何处理日志缓冲区的内容,特别是logfilesync事件与事务提交、回滚的关系,以及如何影响系统性能。它提到了高提交率可能导致的系统开销,并提供了优化建议,如调整LGWR、事务批处理和IO子系统性能。此外,还介绍了使用OracleLogMiner分析重做日志和监控系统事件的方法。
文章详细阐述了Oracle数据库中LGWR进程如何处理日志缓冲区的内容,特别是logfilesync事件与事务提交、回滚的关系,以及如何影响系统性能。它提到了高提交率可能导致的系统开销,并提供了优化建议,如调整LGWR、事务批处理和IO子系统性能。此外,还介绍了使用OracleLogMiner分析重做日志和监控系统事件的方法。
log file sync
1.ORACLE在SGA中的日志缓冲区中记录事务和块改变,通过以各种时间条件将内容写入到日志文件,LGWR负责这项工作,写入的时间条件是:
A. 每隔3秒
B. 当日志缓冲区的1/3已满或具有1MB的重做条目时
C. 当用户提交或回滚事务时
D. 当DBWR进程给LGWR发出信号(当DBWR将脏块写入到数据文件之前写入)
2.由用户提交或回滚的写入称为"同步写入",其他的称为"后台写入"。log file sync只和同步写入有关。用户会话从来不需要等待后台写入的完成。
3.当用户会话通过提交或回滚完成一个事务时,必须用LGWR进程将会话的重做信息写入重做日志,会话才能继续其处理。在LGWR同步期间,LGWR进程在log file parallel write事件上等待同步写入完成,而用户会话则在log file sync事件上等待LGWR的完成。
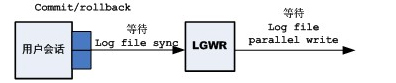
4.log file sync等待事件与事务的终止(提交或回滚)相关。当进程在log file sync事件上花费大量时间时,通常表明过多的提交或短事务。
5.每个COMMIT必须得到相关REDO写入磁盘的确认。
6.调整LGWR进程使其得到良好的磁盘吞吐量。如:不要将重做日志放在RAID5阵列;如果有大量的短周期的事务,则看能否批处理这些事务,使COMMIT次数减少。
7.查询会话中谁执行了大量的提交:
SELECT a.sid,
a.event, a.time_waited,
round(a.time_waited / c.sum_time_waited * 100, 2) || '%' pct_wait_time,
d.VALUE user_commits, round((SYSDATE - b.logon_time) * 24) hours_connected
FROM v$session_event a,
v$session b, (SELECT sid, SUM(time_waited) sum_time_waited
FROM v$session_event
WHERE event NOT IN ('smon timer', 'pmon timer', 'rdbms ipc message', 'Null event',
'parallel query dequeue', 'pipe get', 'client message',
'SQL*Net message to client', 'SQL*Net message from client', 'SQL*Net more data from client', 'dispatcher timer',
'virtual circuit status',
'lock manager wait for remote message', 'PX Idle Wait',
'PX Deq: Execution Msg', 'PX Deq: Table Q Normal', 'wakeup time manager', 'slave wait', 'i/o slave wait',
'jobq slave wait', 'null event', 'gcs remote message',
'gcs for action', 'ges remote message', 'queue messages') HAVING SUM(time_waited) > 0
GROUP BY sid) c,
v$sesstat d
WHERE a.sid = b.sid
AND a.sid = c.sid
AND a.sid = d.sid
AND d.statistic# =
(SELECT statistic# FROM v$statname WHERE NAME = 'user commits')
AND a.time_waited > 10000
AND a.event = 'log file sync'
ORDER BY hours_connected DESC, pct_wait_time8.可以使用Oracle Log Miner深入研究重做日志文件,这能查看系统范围的提交行。
9.IO的吞吐量也是考量之一,如下:
SELECT s.event, s.time_waited, s.average_wait
FROM v$system_event s
WHERE s.event IN ('log file parallel write', 'log file sync')
注:'log file parallel write'事件的平均等待时间大于10ms(1cs),这通常表示存在缓慢的IO吞吐量。10.产生该等待事件的主要原因:
| 高提交率 | 原因: >> 高提交率会增加开始与结束事务时的系统开销(事务表的更新、提交后的清除、回滚段的使用被记录在日志缓冲区中等等)。 解决方法: >> 以事务单元作为提交的准则。 >> 不要因为回滚段空间不足或死锁的原因而引入附加的提交。如果回滚段空间不够而造成不可以处理一个工作单位,可以分配足够的空间给UNDO表空间,并且设置适当的UNDO保留时间(通过初始化参数undo_retention设置)。 >> 来自于中间层的持久性连接,因为服务于许多前端用户,所以只能用10046事件进行跟踪,以观察应用程序的行为;或使用Oracle Log Miner查看重做日志文件。 |
| 缓慢的IO子系统 | 通过查询v$system_event视图,找出LGWR平均等待时间。小于1厘秒(cs)一般是可以接受的。 |
| 过大的日志缓冲区 | >> 日志缓冲区过小,会造成log buffer space事件上的等待,而日志缓冲区过大,会造成LGWR进程写入频率变慢,一次写入量变大。 >> 可以通过减少初始化参数_LOG_IO_SIZE的值,这将增LGWR的后台写入,从而减少log file sync等待时间,但这种方法仍然需要一定的系统开销,更为活跃的LGWR将在redo copy和redo writing锁存器方面添加更多的负载。 >> 获得_LOG_IO_SIZE设置值: select trunc(a.value/b.value*512) as "REDO每次写入字节数", trunc(1024*1024/3) as "9I系统设置写入字节数" WHERE s.NAME = 'redo blocks written') a, WHERE s.NAME = 'redo writes') b >> 较大的processes参数值也可增加log file sync的等待,在每个同步操作期间,LGWR必须扫描所有进程的数据结构查找哪些会话正在这个事件上等待,并将它们的重做写入到硬盘。 |


















 4717
4717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











