







文章目录
一、Java
1.jdbc:
JDBC 连接hive2, 程序挺简单, 跟其他数据库查询类似, 连接/执行查询/得到结果:
package com.huiq.bigdata.test;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class ApiQueryTest {
private static String driverName = "org.apache.hive.jdbc.HiveDriver";
public static void main(String[] args){
try {
Class.forName(driverName);
Connection con = null;
con = DriverManager.getConnection("jdbc:hive2://node01:10000/ods_test_schema1", "root", "123456");
Statement stmt = con.createStatement();
ResultSet res = null;
String sql = "select * from t1";
System.out.println("Running: " + sql);
res = stmt.executeQuery(sql);
System.out.println("ok");
while (res.next()) {
System.out.println(res.getString(1) + "\t" + res.getString(2));
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
Linux执行结果:
[root@node01 huiq]# java -cp hivejdbc-jar-with-dependencies.jar com.huiq.bigdata.test.ApiQueryTest
Running: select * from t1
ok
-103829163_116 116
-1406838352_113 113
-1511909649_130 130
-1789481461_141 141
IDEA在Windows中执行结果:
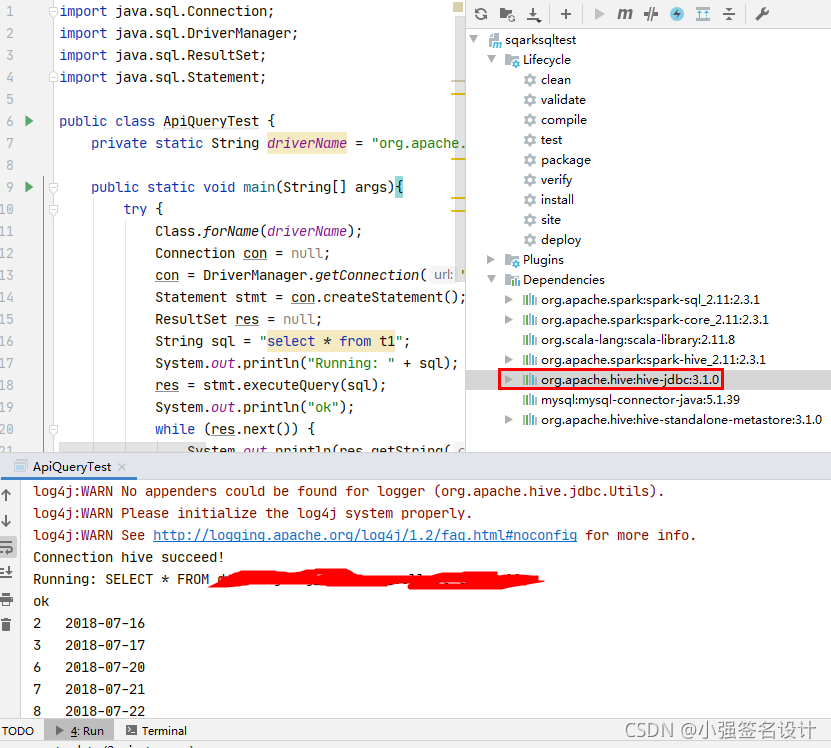
所需依赖:
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>3.1.0</version>
</dependency>
2.Spark Sql:
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.sql.SQLContext;
import org.apache.spark.sql.hive.HiveContext;
/**
* @author: huiq
* @createTime: 2021/8/27 13:55
* @description: 连接hive测试
*/
public class SparkSqlHiveTest
{
public static void main( String[] args )
{
SparkConf sparkConf = new SparkConf().setAppName("SparkHive").setMaster("local[2]");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
HiveContext hiveContext = new HiveContext(sc);
//不要使用SQLContext,部署异常找不到数据库和表
// SQLContext sqlContext = new SQLContext(sc);
//查询表前10条数据
// hiveContext.sql("select * from datawarehouse_ods_db.ods_ct_taglimit 10").show();
spark.sql("use datawarehouse_dws_db");
spark.sql("create table if not exists member_reg_num_day_tmp as \nselect \n to_date(reg_time) date_time,\n count(1) num \nfrom \n datawarehouse_dwd_db.dwd_us_user \nwhere \n reg_time!='' \ngroup by \n to_date(reg_time)");
sc.stop();
}
}
所需依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.3.1</version>
</dependency>
执行命令:
spark-submit --master local[2] --class com.huiq.bigdata.online.SparkSqlHiveTest hbase-jar-with-dependencies.jar
注:SQLContext和HiveContext区别和联系
Spark SQL程序的主入口是SQLContext类或它的子类。创建一个基本的SQLContext,你只需要SparkContext
除了基本的SQLContext,也可以创建HiveContext。SQLContext和HiveContext区别与联系为:
SQLContext现在只支持SQL语法解析器(SQL-92语法)
HiveContext现在支持SQL语法解析器和HiveSQL语法解析器,默认为HiveSQL语法解析器,用户可以通过配置切换成SQL语法解析器,来运行HiveSQL不支持的语法。
使用HiveContext可以使用Hive的UDF,读写Hive表数据等Hive操作。SQLContext不可以对Hive进行操作。
Spark SQL未来的版本会不断丰富SQLContext的功能,做到SQLContext和HiveContext的功能容和,最终可能两者会统一成一个Context
HiveContext包装了Hive的依赖包,把HiveContext单独拿出来,可以在部署基本的Spark的时候就不需要Hive的依赖包,需要使用HiveContext时再把Hive的各种依赖包加进来。
SQL的解析器可以通过配置spark.sql.dialect参数进行配置。在SQLContext中只能使用Spark SQL提供的”sql“解析器。在HiveContext中默认解析器为”hiveql“,也支持”sql“解析器。
二、Scala
1.Spark Sql:
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
/**
* @Auther: huiq
* @Date: 2021/7/23
* @Description: 连接hive测试
*/
object SparkSqlHiveTest {
def main(args: Array[String]): Unit = {
//初始化spark
val sparkConf = new SparkConf().setMaster("local[2]").setAppName(this.getClass.getSimpleName)
val spark: SparkSession = SparkSession.builder().enableHiveSupport().config(sparkConf).getOrCreate()
//选择Hive库
spark.sql("use datawarehouse_dws_db");
spark.sql("create table if not exists member_reg_num_day_tmp as \nselect \n to_date(reg_time) date_time,\n count(1) num \nfrom \n datawarehouse_dwd_db.dwd_us_user \nwhere \n reg_time!='' \ngroup by \n to_date(reg_time)");
spark.stop();
}
}
所需依赖:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.11</artifactId>
<version>2.3.1</version>
</dependency>
执行命令:
spark-submit --master local[2] --class com.huiq.bigdata.online.SparkSqlHiveTest hbase-jar-with-dependencies.jar
注:如果要在IDEA中纯maven项目中执行的话需要把服务器上的hive-site.xml、hdfs-site.xml、core-site.xml文件放到resource目录下;但是在springboot项目下整合却报错:Exception in thread "main" java.lang.NoSuchFieldError: HIVE_STATS_JDBC_TIMEOUT,可能是springboot内部有什么处理导致依赖冲突,可能需要重新编译spark-hive的jar包,思路可参考spark hive java.lang.NoSuchFieldError: HIVE_STATS_JDBC_TIMEOUT
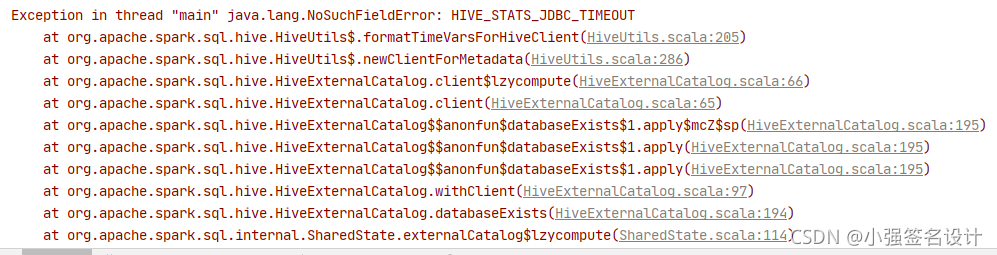
遇到的问题:org.apache.thrift.TApplicationException: Required field 'filesAdded' is unset! Struct:InsertEventRequestData(filesAdded:null)

解决:把sql语句转换成这样的可以成功:spark.sql("select \n to_date(reg_time) date_time,\n count(1) num \nfrom \n datawarehouse_dwd_db.dwd_us_user \nwhere \n reg_time!='' \ngroup by \n to_date(reg_time)").write.mode(SaveMode.Overwrite).saveAsTable("datawarehouse_dws_db.member_reg_num_day_tmp")
Java代码的话为:hiveContext.sql("select \n to_date(reg_time) date_time,\n count(1) num \nfrom \n rongrong_datawarehouse_dwd_db.dwd_rongrong_us_user \nwhere \n reg_time!='' \ngroup by \n to_date(reg_time)").write().mode(SaveMode.Overwrite).saveAsTable("rongrong_datawarehouse_dws_db.member_reg_num_day_tmp");
注:所遇到的问题上面Spark Sql的java版本同样适用。
三、踩坑之路
1. Required field ‘client_protocol’ is unset!
log4j:WARN No appenders could be found for logger (org.apache.hadoop.util.Shell).
log4j:WARN Please initialize the log4j system properly.
log4j:WARN See http://logging.apache.org/log4j/1.2/faq.html#noconfig for more info.
java.sql.SQLException: Could not open client transport with JDBC Uri: jdbc:hive2://node01:10000/heheda_ods_db: Could not establish connection to jdbc:hive2://node01:10000/heheda_ods_db: Required field 'client_protocol' is unset! Struct:TOpenSessionReq(client_protocol:null, configuration:{set:hiveconf:hive.server2.thrift.resultset.default.fetch.size=1000, use:database=heheda_ods_db})
at org.apache.hive.jdbc.HiveConnection.<init>(HiveConnection.java:252)
at org.apache.hive.jdbc.HiveDriver.connect(HiveDriver.java:107)
at java.sql.DriverManager.getConnection(DriverManager.java:664)
at java.sql.DriverManager.getConnection(DriverManager.java:247)
Caused by: java.sql.SQLException: Could not establish connection to jdbc:hive2://node01:10000/heheda_ods_db: Required field 'client_protocol' is unset! Struct:TOpenSessionReq(client_protocol:null, configuration:{set:hiveconf:hive.server2.thrift.resultset.default.fetch.size=1000, use:database=heheda_ods_db})
at org.apache.hive.jdbc.HiveConnection.openSession(HiveConnection.java:734)
at org.apache.hive.jdbc.HiveConnection.<init>(HiveConnection.java:228)
... 4 more
Caused by: org.apache.thrift.TApplicationException: Required field 'client_protocol' is unset! Struct:TOpenSessionReq(client_protocol:null, configuration:{set:hiveconf:hive.server2.thrift.resultset.default.fetch.size=1000, use:database=heheda_ods_db})
at org.apache.thrift.TApplicationException.read(TApplicationException.java:111)
at org.apache.thrift.TServiceClient.receiveBase(TServiceClient.java:79)
at org.apache.hive.service.rpc.thrift.TCLIService$Client.recv_OpenSession(TCLIService.java:176)
at org.apache.hive.service.rpc.thrift.TCLIService$Client.OpenSession(TCLIService.java:163)
at org.apache.hive.jdbc.HiveConnection.openSession(HiveConnection.java:715)
... 5 more
原因:项目的 Pom 文件中 hive-jdbc 版本号没有与 hive Server 的version要保持一致
一开始的配置:
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>2.1.0</version>
</dependency>
修改后的配置:
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>3.1.0</version>
</dependency>
参考:
hive客户端连接服务端报错“Required field ‘client_protocol’ is unset! ”异常解决
Required field ‘client_protocol‘ is unset 原因探究
















 1352
1352











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











