







文章目录
一、前言
理想情况下,我们应用对Yarn资源的请求应该立刻得到满足,但现实情况资源往往是有限的,特别是在一个很繁忙的集群,一个应用资源的请求经常需要等待一段时间才能得到相应的资源。在Yarn中,负责给应用分配资源的就是Scheduler。其实调度本身就是一个难题,很难找到一个完美的策略可以解决所有的应用场景。为此,Yarn提供了多种调度器和可配置的策略供我们选择。
试想一下,你现在所在的公司有一个hadoop的集群。但是A项目组经常做一些定时的BI报表,B项目组则经常使用一些软件做一些临时需求。那么他们肯定会遇到同时提交任务的场景,这个时候到底如何分配资源满足这两个任务呢?是先执行A的任务,再执行B的任务,还是同时跑两个?如果你存在上述的困惑,可以多了解一些yarn的资源调度器。
在Yarn框架中,调度器是一块很重要的内容。有了合适的调度规则,就可以保证多个应用可以在同一时间有条不紊的工作。最原始的调度规则就是FIFO,即按照用户提交任务的时间来决定哪个任务先执行,但是这样很可能一个大任务独占资源,其他的资源需要不断的等待。也可能一堆小任务占用资源,大任务一直无法得到适当的资源,造成饥饿。所以FIFO虽然很简单,但是并不能满足我们的需求。
可在Web页面查看:http://node03:8088/
二、调度器的选择
在Yarn中有三种调度器可以选择:FIFO Scheduler,Capacity Scheduler,Fair Scheduler。
大厂:如果对并发度要求比较高,选择公平调度器,要求服务器性能必须OK。
中小公司:集群服务器资源不太充裕选择容量调度器。
1.FIFO Scheduler:
FIFO Scheduler把应用按提交的顺序排成一个队列,这是一个先进先出队列,在进行资源分配的时候,先给队列中最头上的应用进行分配资源,待最头上的应用需求满足后再给下一个分配,以此类推。
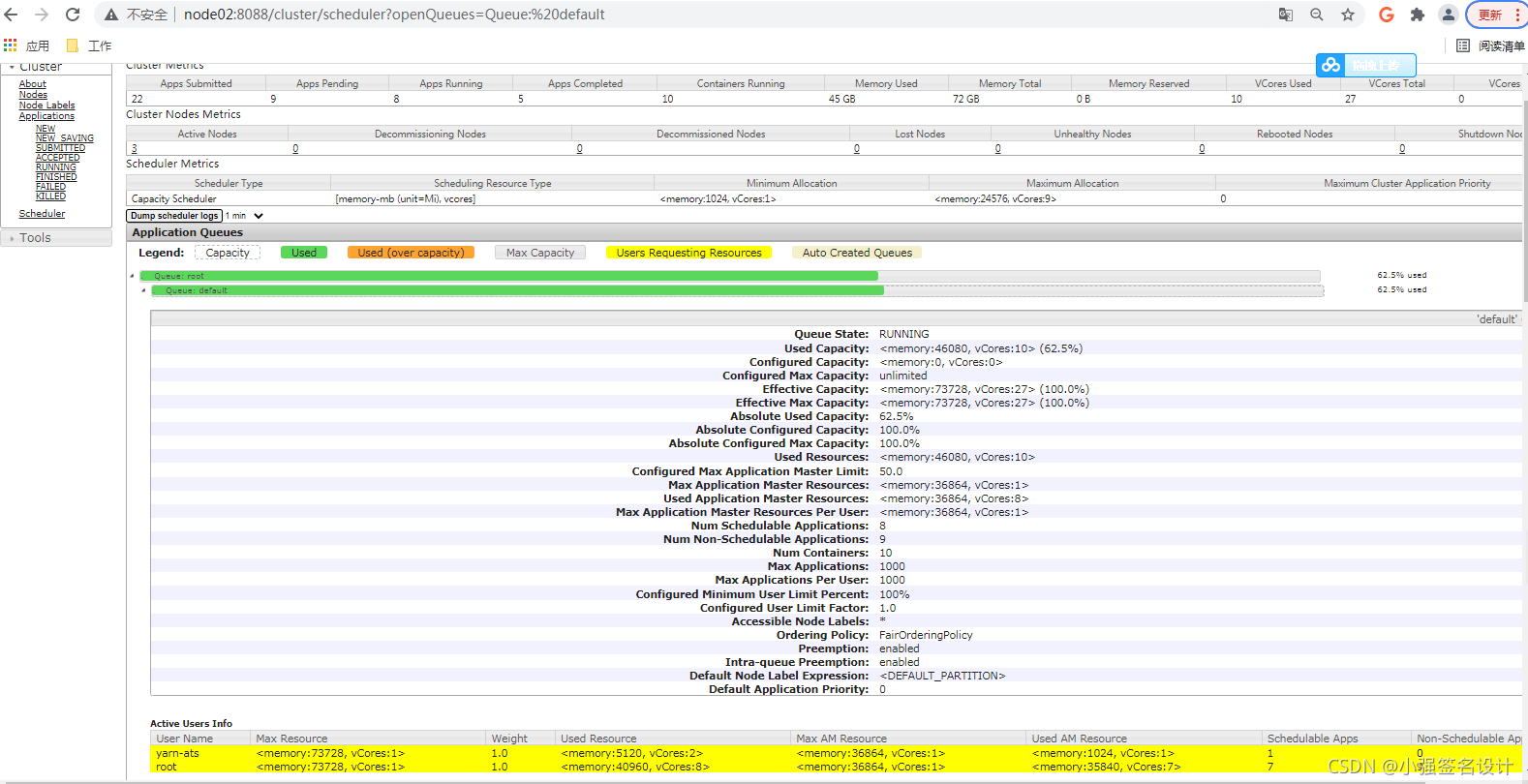
FIFO Scheduler是最简单也是最容易理解的调度器,也不需要任何配置,但它并不适用于共享集群。大的应用可能会占用所有集群资源,这就导致其它应用被阻塞。在共享集群中,更适合采用Capacity Scheduler或Fair Scheduler,这两个调度器都允许大任务和小任务在提交的同时获得一定的系统资源。下面 “Yarn调度器对比图” 展示了这几个调度器的区别,从图中可以看出,在FIFO 调度器中,小任务会被大任务阻塞。
2.Capacity Scheduler:
而对于Capacity调度器,有一个专门的队列用来运行小任务,但是为小任务专门设置一个队列会预先占用一定的集群资源,这就导致大任务的执行时间会落后于使用FIFO调度器时的时间。
3.Fair Scheduler:
在 Fair 调度器中,我们不需要预先占用一定的系统资源,Fair 调度器会为所有运行的 job 动态的调整系统资源。如下图所示,当第一个大 job 提交时,只有这一个 job 在运行,此时它获得了所有集群资源;当第二个小任务提交后,Fair 调度器会分配一半资源给这个小任务,让这两个任务公平的共享集群资源。
需要注意的是,在下图Fair调度器中,从第二个任务提交到获得资源会有一定的延迟,因为它需要等待第一个任务释放占用的 Container。小任务执行完成之后也会释放自己占用的资源,大任务又获得了全部的系统资源。最终的效果就是 Fair 调度器即得到了高的资源利用率又能保证小任务及时完成。
4.Yarn调度器对比图:
三、Capacity调度器
1.介绍:
Capacity 调度器允许多个组织共享整个集群,每个组织可以获得集群的一部分计算能力。通过为每个组织分配专门的队列,然后再为每个队列分配一定的集群资源,这样整个集群就可以通过设置多个队列的方式给多个组织提供服务了。除此之外,队列内部又可以垂直划分,这样一个组织内部的多个成员就可以共享这个队列资源了,在一个队列内部,资源的调度是采用的是先进先出(FIFO)策略。
通过上面那幅图,我们已经知道一个 job 可能使用不了整个队列的资源。然而如果这个队列中运行多个 job,如果这个队列的资源够用,那么就分配给这些 job,如果这个队列的资源不够用了呢?其实 Capacity 调度器仍可能分配额外的资源给这个队列,这就是 “弹性队列”(queue elasticity) 的概念。
在正常的操作中,Capacity 调度器不会强制释放 Container,当一个队列资源不够用时,这个队列只能获得其它队列释放后的 Container 资源。当然,我们可以为队列设置一个最大资源使用量,以免这个队列过多的占用空闲资源,导致其它队列无法使用这些空闲资源,这就是 ”弹性队列” 需要权衡的地方。
Capacity 调度器说的通俗点,可以理解成一个个的资源队列。这个资源队列是用户自己去分配的。比如我大体上把整个集群分成了AB两个队列,A队列给A项目组的人来使用。B队列给B项目组来使用。但是A项目组下面又有两个方向,那么还可以继续分,比如专门做BI的和做实时分析的。那么队列的分配就可以参考下面的树形结构
root
------A[60%]
|---A.bi[40%]
|---A.realtime[60%]
------B[40%]
A队列占用整个资源的60%,B队列占用整个资源的40%。A队列里面又分了两个子队列,一样也是2:3分配。
虽然有了这样的资源分配,但是并不是说A提交了任务,它就只能使用60%的资源,那40%就空闲着。只要资源实在处于空闲状态,那么A就可以使用100%的资源。但是一旦B提交了任务,A就需要在释放资源后,把资源还给B队列,直到AB平衡在3:2的比例。
粗粒度上资源是按照上面的方式进行,在每个队列的内部,还是按照 FIFO 的原则来分配资源的。
2.capacity调度器具有以下的几个特性:
- 层次化的队列设计,这种层次化的队列设计保证了子队列可以使用父队列设置的全部资源。这样通过层次化的管理,更容易合理分配和限制资源的使用。
- 容量保证,队列上都会设置一个资源的占比,这样可以保证每个队列都不会占用整个集群的资源。
- 安全,每个队列又严格的访问控制。用户只能向自己的队列里面提交任务,而且不能修改或者访问其他队列的任务。
- 弹性分配,空闲的资源可以被分配给任何队列。当多个队列出现争用的时候,则会按照比例进行平衡。
- 多租户租用,通过队列的容量限制,多个用户就可以共享同一个集群,同事保证每个队列分配到自己的容量,提高利用率。
- 操作性,yarn 支持动态修改调整容量、权限等的分配,可以在运行时直接修改。还提供给管理员界面,来显示当前的队列状况。管理员可以在运行时,添加一个队列;但是不能删除一个队列。管理员还可以在运行时暂停某个队列,这样可以保证当前的队列在执行过程中,集群不会接收其他的任务。如果一个队列被设置成了 stopped,那么就不能向他或者子队列上提交任务了。
- 基于资源的调度,协调不同资源需求的应用程序,比如内存、CPU、磁盘等等。
3.调度器的配置:
yarn的默认配置是有一个默认的队列,事实上,是否使用Capacity Scheduler组件是可以配置的,但是默认配置就是这个Capacity Scheduler,如果想显式配置需要修改 conf/yarn-site.xml 内容如下:
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
可以看到默认是org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler这个调度器,那么这个调度器的名字是什么呢?我们可以在hadoop-2.6.0/etc/hadoop/capacity-scheduler.xml文件中看到
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>default</value>
<description>
The queues at the this level (root is the root queue).
</description>
</property>
配置项格式应该是yarn.scheduler.capacity..queues,也就是这里的root是一个queue-path,因为这里配置了value是default,所以root这个queue-path只有一个队列叫做default,那么有关default的具体配置都是形如下的配置项:
yarn.scheduler.capacity.root.default.capacity:一个百分比的值,表示占用整个集群的百分之多少比例的资源,这个queue-path下所有的capacity之和是100
yarn.scheduler.capacity.root.default.user-limit-factor:每个用户的低保百分比,比如设置为1,则表示无论有多少用户在跑任务,每个用户占用资源最低不会少于1%的资源
yarn.scheduler.capacity.root.default.maximum-capacity:弹性设置,最大时占用多少比例资源
yarn.scheduler.capacity.root.default.state:队列状态,可以是RUNNING或STOPPED
yarn.scheduler.capacity.root.default.acl_submit_applications:哪些用户或用户组可以提交人物
yarn.scheduler.capacity.root.default.acl_administer_queue:哪些用户或用户组可以管理队列
调度器的核心就是队列的分配和使用了,修改conf/capacity-scheduler.xml可以配置队列。Capacity调度器默认有一个预定义的队列—root,所有的队列都是它的子队列。队列的分配支持层次化的配置,使用.来进行分割,比如yarn.scheduler.capacity.<queue-path>.queues。下面是配置的样例,比如root下面有三个子队列:
<property>
<name>yarn.scheduler.capacity.root.queues</name>
<value>a,b,c</value>
<description>The queues at the this level (root is the root queue).
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.a.queues</name>
<value>a1,a2</value>
<description>The queues at the this level (root is the root queue).
</description>
</property>
<property>
<name>yarn.scheduler.capacity.root.b.queues</name>
<value>b1,b2,b3</value>
<description>The queues at the this level (root is the root queue).
</description>
</property>
上面的结构类似于:
root
------a[队列名字]
|---a1[子队列名字]
|---a2[子队列名字]
------b[队列名字]
|---b1[子队列名字]
|---b2[子队列名字]
|---b3[子队列名字]
------c[队列名字]
四、Fair调度器
1.介绍:
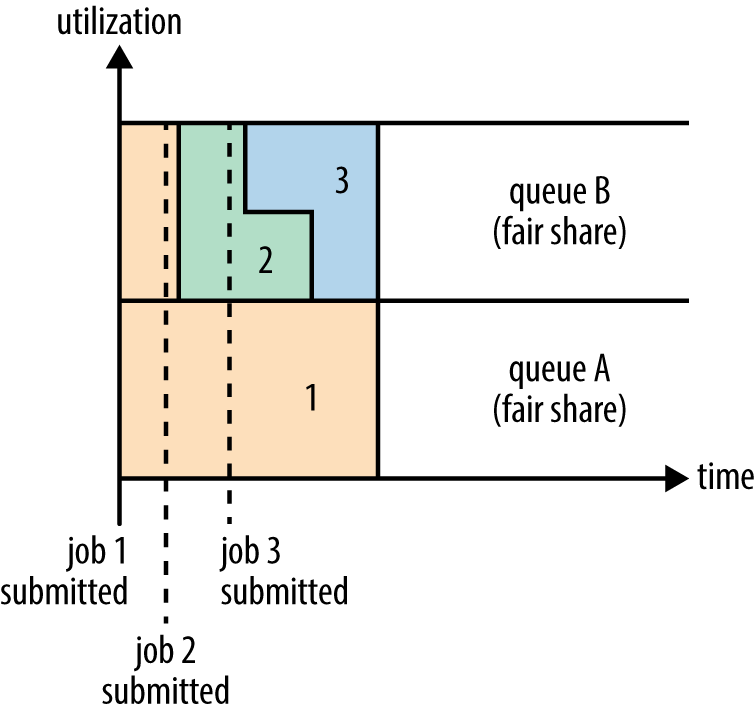
Fair调度器的设计目标是为所有的应用分配公平的资源(对公平的定义可以通过参数来设置)。在上面的 “Yarn调度器对比图” 展示了一个队列中两个应用的公平调度;当然,公平调度在也可以在多个队列间工作。举个例子,假设有两个用户A和B,他们分别拥有一个队列。当A启动一个job而B没有任务时,A会获得全部集群资源;当B启动一个job后,A的job会继续运行,不过一会儿之后两个任务会各自获得一半的集群资源。如果此时B再启动第二个job并且其它job还在运行,则它将会和B的第一个job共享B这个队列的资源,也就是B的两个job会用于四分之一的集群资源,而A的job仍然用于集群一半的资源,结果就是资源最终在两个用户之间平等的共享。过程如下图所示:
2.启用Fair Scheduler:
调度器的使用是通过yarn-site.xml配置文件中的yarn.resourcemanager.scheduler.class参数进行配置的,默认采用Capacity Scheduler调度器。如果我们要使用Fair调度器,需要在这个参数上配置FairScheduler类的全限定名: org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler。
3.抢占(Preemption):
当一个job提交到一个繁忙集群中的空队列时,job并不会马上执行,而是阻塞直到正在运行的job释放系统资源。为了使提交job的执行时间更具预测性(可以设置等待的超时时间),Fair调度器支持抢占。
抢占就是允许调度器杀掉占用超过其应占份额资源队列的 containers,这些 containers 资源便可被分配到应该享有这些份额资源的队列中。需要注意抢占会降低集群的执行效率,因为被终止的 containers 需要被重新执行。
可以通过设置一个全局的参数 yarn.scheduler.fair.preemption=true 来启用抢占功能。此外,还有两个参数(minimum share preemption timeout、fair share preemption timeout)用来控制抢占的过期时间(这两个参数默认没有配置,需要至少配置一个来允许抢占 Container)。
如果队列在 minimum share preemption timeout 指定的时间内未获得最小的资源保障,调度器就会抢占 containers。我们可以通过配置文件中的顶级元素 <defaultMinSharePreemptionTimeout> 为所有队列配置这个超时时间;我们还可以在 <queue> 元素内配置 <minSharePreemptionTimeout> 元素来为某个队列指定超时时间。
与之类似,如果队列在 fair share preemption timeout 指定时间内未获得平等的资源的一半(这个比例可以配置),调度器则会进行抢占 containers。这个超时时间可以通过顶级元素 <defaultFairSharePreemptionTimeout> 和元素级元素 <fairSharePreemptionTimeout> 分别配置所有队列和某个队列的超时时间。上面提到的比例可以通过 <defaultFairSharePreemptionThreshold> (配置所有队列)和 <fairSharePreemptionThreshold> (配置某个队列)进行配置,默认是0.5。
参考:
Yarn 调度器Scheduler详解
Yarn资源队列配置和使用
【Ambari】yarn资源调度之CapacityScheduler
Ambari2.7.4+HDP3.1.4.0中配置fair-scheduler
Yarn 队列设置
yarn自定义scheduler队列
ambari Capacity Scheduler 调度排序策略
hadoop详细笔记(十九)原理加强Yarn调度策略详解
YARN——正确理解容量调度的capacity参数
五、各组件执行任务时如何选择队列
1.hive指定队列:
hive 设置队列需要根据所使用的引擎进行对应的设置才会有效果,否则无效,设置引擎:
set hive.execution.engine=mr;
set hive.execution.engine=spark;
set hive.execution.engine=tez;
如果使用的是mr(原生mapreduce)
SET mapreduce.job.queuename=heheda;
如果使用的引擎是tez
set tez.queue.name=heheda;
设置队列(etl为队列名称,默认为default)
Hive提供三种可以改变环境变量的方法,分别是:
(1)、修改${HIVE_HOME}/conf/hive-site.xml配置文件;
在Hive中,所有的默认配置都在${HIVE_HOME}/conf/hive-default.xml文件中,如果需要对默认的配置进行修改,可以创建一个hive-site.xml文件,放在${HIVE_HOME}/conf目录下。里面可以对一些配置进行个性化设定。在hive-site.xml的格式如下:
<property>
<name>mapreduce.job.queuename</name>
<value>opdn1_zbwj</value>
</property>
(2)、命令行参数;
在启动Hive cli的时候进行配置,可以在命令行添加-hiveconf param=value来设定参数,例如:hive --hiveconf mapreduce.job.queuename=queue1。这样在Hive中所有MapReduce作业都提交到队列queue1中。这一设定对本次启动的会话有效,下次启动需要重新配置。
(3)、在已经进入cli时进行参数声明。下面分别来介绍这几种设定。
在已经进入cli时进行参数声明,可以在HQL中使用SET关键字设定参数,例如:
set mapred.job.queue.name=queue3;
set mapreduce.job.queuename=queue3;
set mapred.queue.names=queue3;
注意:老版本一般 mapred 开头,新版本是 mapreduce 开头。
如果set后面什么都不添加,这样可以查到Hive的所有属性配置,如下:
hive> set;
datanucleus.autoCreateSchema=true
datanucleus.autoStartMechanismMode=checked
datanucleus.cache.level2=false
datanucleus.cache.level2.type=none
datanucleus.connectionPoolingType=DBCP
datanucleus.identifierFactory=datanucleus
datanucleus.plugin.pluginRegistryBundleCheck=LOG
datanucleus.storeManagerType=rdbms
datanucleus.transactionIsolation=read-committed
datanucleus.validateColumns=false
datanucleus.validateConstraints=false
datanucleus.validateTables=false
............................
参考:
hive 设置队列
hive指定hadoop执行队列
Hive设置参数的三种方法
2.spark指定队列:
spark-shell --master yarn --queue wa
spark-submit --master yarn --queue wa
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











