







 本文详细介绍JVM调试工具及参数设置,涵盖JDK命令行工具如jps、jstat等,以及JVM参数如-Xmx、-XX:UseConcMarkSweepGC等,并解析GC日志。
本文详细介绍JVM调试工具及参数设置,涵盖JDK命令行工具如jps、jstat等,以及JVM参数如-Xmx、-XX:UseConcMarkSweepGC等,并解析GC日志。
本系列文章:
JVM(一)Java运行时区域、对象的使用
JVM(二)垃圾回收
JVM(三)类文件结构、类加载机制
JVM(四)JVM调试命令、JVM参数
JVM(五)JVM调优
一、JVM调试
1.1 JDK命令行工具
这些命令在JDK安装目录下的bin目录下。
- 1、jps
(JVM Process Status): 类似UNIX的ps命令。用于查看所有Java进程的启动类、传入参数和 Java 虚拟机参数等信息。 - 2、jstat
JVM statistics Monitoring,用于收集HotSpot虚拟机各方面的运行数据。 - 3、jmap
JVM Memory Map,用于生成heap dump文件。 - 4、jhat
JVM Heap Analysis Tool,用来分析jmap生成的dump,jhat内置了一个微型的HTTP/HTML服务器,生成dump的分析结果后,可以在浏览器中查看。 - 5、jstack
用于生成java虚拟机当前时刻的线程快照,线程快照就是当前虚拟机内每一
条线程正在执行的方法堆栈的集合。 - 6、jinfo
JVM Configuration info,用于实时查看和调整虚拟机运行参数。
1.1.1 jps:查看所有Java进程*
jps (JVM Process Status) 命令类似UNIX的ps命令。
jps :显示虚拟机执行主类名称以及这些进程的本地虚拟机唯一 ID(Local Virtual Machine Identifier,LVMID)。jps -q :只输出进程的本地虚拟机唯一ID。
示例:
C:\Users\SnailClimb>jps
7360 NettyClient2
17396
7972 Launcher
16504 Jps
17340 NettyServer
jps -l :输出主类的全名,如果进程执行的是Jar包,输出 Jar 路径。
C:\Users\SnailClimb>jps -l
7360 firstNettyDemo.NettyClient2
17396
7972 org.jetbrains.jps.cmdline.Launcher
16492 sun.tools.jps.Jps
17340 firstNettyDemo.NettyServer
jps -v:输出虚拟机进程启动时JVM参数。
jps -m:输出传递给Java进程main()函数的参数。
1.1.2 jstat:监视虚拟机各种运行状态信息
jstat(JVM Statistics Monitoring Tool) 使用于监视虚拟机各种运行状态信息的命令行工具。 它可以显示本地或者远程(需要远程主机提供 RMI 支持)虚拟机进程中的类信息、内存、垃圾收集、JIT编译等运行数据,在没有GUI,只提供了纯文本控制台环境的服务器上,它将是运行期间定位虚拟机性能问题的首选工具。
用于监视虚拟机各种运行状态信息,如虚拟机进程中的类装载、内存、垃圾收集、JIT编译等运行数据。jstat命令格式为:
jstat -<option> [-t] [-h<lines>] <vmid> [<interval> [<count>]]
如jstat -gc -h3 31736 1000 10,表示分析进程id为31736的gc情况,每隔1000ms打印一次记录,打印10次停止,每3行后打印指标头部。
常见的参数使用:
jstat -class vmid :显示 ClassLoader 的相关信息;
jstat -compiler vmid :显示 JIT 编译的相关信息;
jstat -gc vmid :显示与 GC 相关的堆信息;
jstat -gccapacity vmid :显示各个代的容量及使用情况;
jstat -gcnew vmid :显示新生代信息;
jstat -gcnewcapcacity vmid :显示新生代大小与使用情况;
jstat -gcold vmid :显示老年代和永久代的行为统计,从jdk1.8开始,该选项仅表示老年代,因为永久代被移除了;
jstat -gcoldcapacity vmid :显示老年代的大小;
jstat -gcpermcapacity vmid :显示永久代大小,从jdk1.8开始,该选项不存在了,因为永久代被移除了;
jstat -gcutil vmid :显示垃圾收集信息;
加上-t参数可以在输出信息上,加一个Timestamp列,显示程序的运行时间。
1.1.3 jinfo:实时地查看和调整虚拟机各项参数*
jinfo vmid:输出当前jvm进程的全部参数和系统属性 (第一部分是系统的属性,第二部分是JVM的参数)。
jinfo -flag name vmid :输出对应名称的参数的具体值。比如输出MaxHeapSize、查看当前jvm进程是否开启打印GC日志 ( -XX:PrintGCDetails:详细GC日志模式,这两个都是默认关闭的)。
C:\Users\SnailClimb>jinfo -flag MaxHeapSize 17340
-XX:MaxHeapSize=2124414976
C:\Users\SnailClimb>jinfo -flag PrintGC 17340
-XX:-PrintGC
使用jinfo,可以在不重启虚拟机的情况下,可以动态的修改jvm的参数。尤其在线上的环境特别有用。
jinfo -flag [+|-]name vmid:开启或者关闭对应名称的参数。
C:\Users\SnailClimb>jinfo -flag PrintGC 17340
-XX:-PrintGC
C:\Users\SnailClimb>jinfo -flag +PrintGC 17340
C:\Users\SnailClimb>jinfo -flag PrintGC 17340
-XX:+PrintGC
1.1.4 jmap:生成堆转储快照*
jmap(Memory Map for Java)命令用于生成堆转储快照。 如果不使用jmap命令,要想获取Java堆转储,可以使用 “-XX:+HeapDumpOnOutOfMemoryError” 参数,可以让虚拟机在OOM异常出现之后自动生成dump文件,Linux命令下可以通过kill -3发送进程退出信号也能拿到dump文件。
jmap的作用并不仅仅是为了获取dump文件,它还可以查询finalizer执行队列、Java堆和永久代的详细信息,如空间使用率、当前使用的是哪种收集器等。和 jinfo 一样, jmap有不少功能在Windows平台下也是受限制的。
示例:将指定应用程序的堆快照输出到桌面。后面,可以通过 jhat、Visual VM 等工具分析该堆文件。
C:\Users\SnailClimb>jmap -
dump:format=b,file=C:\Users\SnailClimb\Desktop\heap.hprof 17340
Dumping heap to C:\Users\SnailClimb\Desktop\heap.hprof ...
Heap dump file created
1.1.5 jhat : 分析heapdump文件
jhat用于分析heapdump文件,它会建立一个HTTP/HTML服务器,让用户可以在浏览器上查看分析结果。
C:\Users\SnailClimb>jhat C:\Users\SnailClimb\Desktop\heap.hprof
Reading from C:\Users\SnailClimb\Desktop\heap.hprof...
Dump file created Sat May 04 12:30:31 CST 2019
Snapshot read, resolving...
Resolving 131419 objects...
Chasing references, expect 26 dots..........................
Eliminating duplicate references..........................
Snapshot resolved.
Started HTTP server on port 7000
Server is ready.
访问 http://localhost:7000/。
1.1.6 jstack:生成虚拟机当前时刻的线程快照*
jstack(Stack Trace for Java)命令用于生成虚拟机当前时刻的线程快照。线程快照就是当前虚拟机内每一条线程正在执行的方法堆栈的集合。
生成线程快照的目的主要是定位线程长时间出现停顿的原因,如线程间死锁、死循环、请求外部资源导致的长时间等待等都是导致线程长时间停顿的原因。线程出现停顿的时候通过jstack来查看各个线程的调用堆栈,就可以知道没有响应的线程到底在后台做些什么事情,或者在等待些什么资源。
线程死锁的代码示例:
public class DeadLockDemo {
private static Object resource1 = new Object();//资源 1
private static Object resource2 = new Object();//资源 2
public static void main(String[] args) {
new Thread(() -> {
synchronized (resource1) {
System.out.println(Thread.currentThread() + "get resource1");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "waiting get resource2");
synchronized (resource2) {
System.out.println(Thread.currentThread() + "get resource2");
}
}
}, "线程 1").start();
new Thread(() -> {
synchronized (resource2) {
System.out.println(Thread.currentThread() + "get resource2");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
System.out.println(Thread.currentThread() + "waiting get resource1");
synchronized (resource1) {
System.out.println(Thread.currentThread() + "get resource1");
}
}
}, "线程 2").start();
}
}
结果:
Thread[线程 1,5,main]get resource1
Thread[线程 2,5,main]get resource2
Thread[线程 1,5,main]waiting get resource2
Thread[线程 2,5,main]waiting get resource1
线程A通过synchronized (resource1)获得resource1的监视器锁,然后通过 Thread.sleep(1000);让线程A休眠1s,为的是让线程B得到resource1执行,然后获取到resource2的监视器锁。线程A和线程B休眠结束了都开始企图请求获取对方的资源,然后这两个线程就会陷入互相等待的状态,这也就产生了死锁。
通过jstack命令分析:
C:\Users\SnailClimb>jps
13792 KotlinCompileDaemon
7360 NettyClient2
17396
7972 Launcher
8932 Launcher
9256 DeadLockDemo
10764 Jps
17340 NettyServer
C:\Users\SnailClimb>jstack 9256
输出的部分内容:
Found one Java-level deadlock:
=============================
"线程 2":
waiting to lock monitor 0x000000000333e668 (object 0x00000000d5efe1c0, a
java.lang.Object),
which is held by "线程 1"
"线程 1":
waiting to lock monitor 0x000000000333be88 (object 0x00000000d5efe1d0, a
java.lang.Object),
which is held by "线程 2"
Java stack information for the threads listed above:
===================================================
"线程 2":
at DeadLockDemo.lambda$main$1(DeadLockDemo.java:31)
- waiting to lock <0x00000000d5efe1c0> (a java.lang.Object)
- locked <0x00000000d5efe1d0> (a java.lang.Object)
at DeadLockDemo$$Lambda$2/1078694789.run(Unknown Source)
at java.lang.Thread.run(Thread.java:748)
"线程 1":
at DeadLockDemo.lambda$main$0(DeadLockDemo.java:16)
- waiting to lock <0x00000000d5efe1d0> (a java.lang.Object)
- locked <0x00000000d5efe1c0> (a java.lang.Object)
at DeadLockDemo$$Lambda$1/1324119927.run(Unknown Source)
at java.lang.Thread.run(Thread.java:748)
Found 1 deadlock.
可以看到jstack命令,已经帮我们找到发生死锁的线程的具体信息。
1.2 JDK可视化分析工具
1.2.1 JConsole:Java监视与管理控制台
JConsole是基于JMX的可视化监视、管理工具。可以很方便的监视本地及远程服务器的Java进程的内存使用情况。你可以在控制台输出console命令启动或者在JDK目录下的bin目录找到jconsole.exe然后双击启动。
- 连接Jconsole
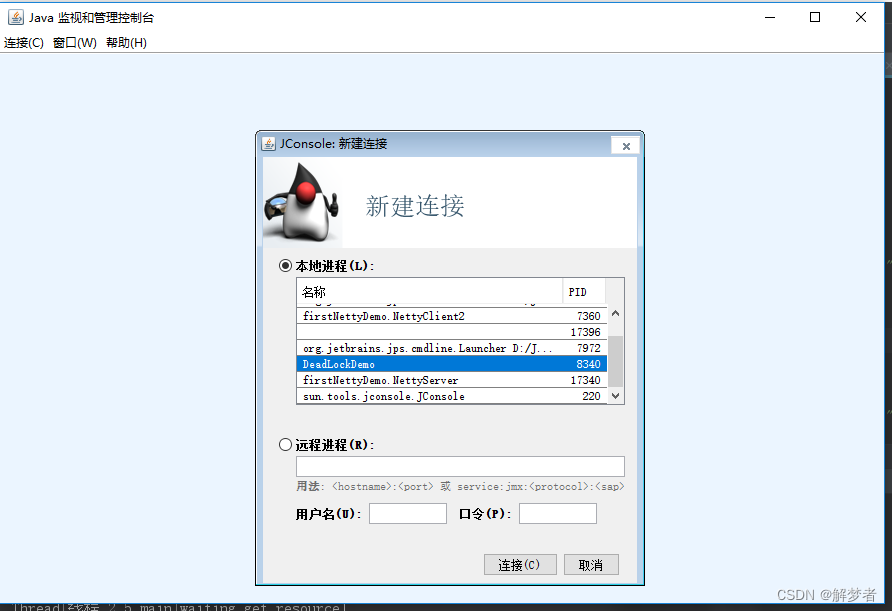
如果需要使用JConsole连接远程进程,可以在远程Java程序启动时加上下面这些参数:
-Djava.rmi.server.hostname=外网访问 ip 地址
-Dcom.sun.management.jmxremote.port=60001 //监控的端口号
-Dcom.sun.management.jmxremote.authenticate=false //关闭认证
-Dcom.sun.management.jmxremote.ssl=false
在使用JConsole连接时,远程进程地址如下:
外网访问 ip 地址:60001
- 查看Java程序概况
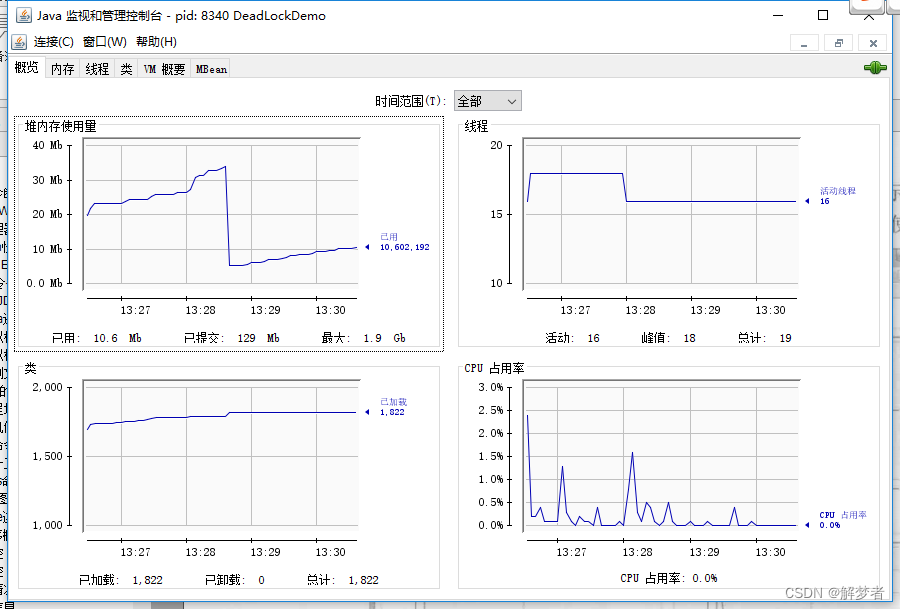
- 内存监控
JConsole可以显示当前内存的详细信息。不仅包括堆内存/非堆内存的整体信息,还可以细化到eden区、survivor区等的使用情况,如下图所示。
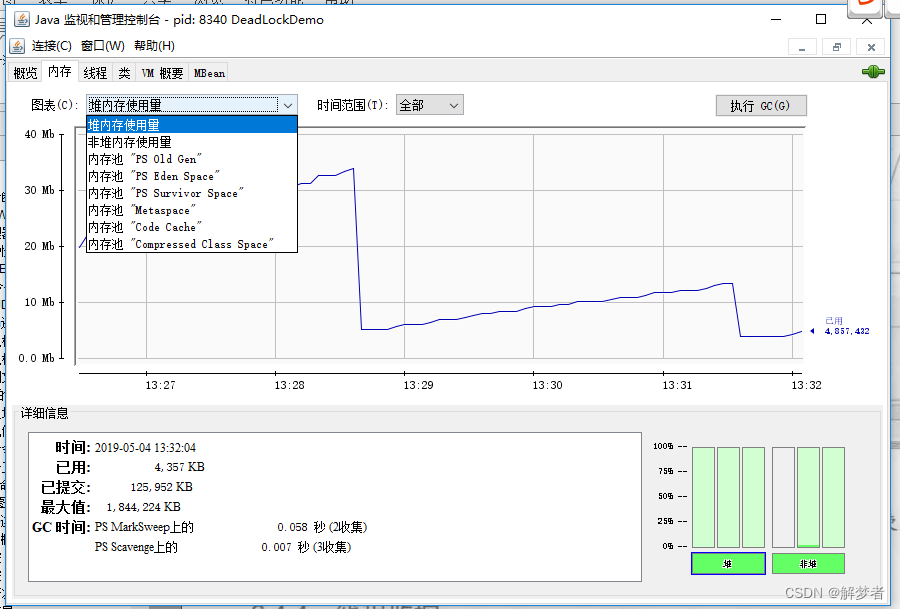
点击右边的“执行 GC(G)”按钮可以强制应用程序执行一个Full GC。
新生代GC(Minor GC):指发生新生代的的垃圾收集动作,Minor GC非常频繁,回收速度一般也比较快。
老年代GC(Major GC/Full GC):指发生在老年代的GC,出现了Major GC经常会伴随至少一次的Minor GC(并非绝对),Major GC的速度一般会比Minor GC的慢10倍以上。
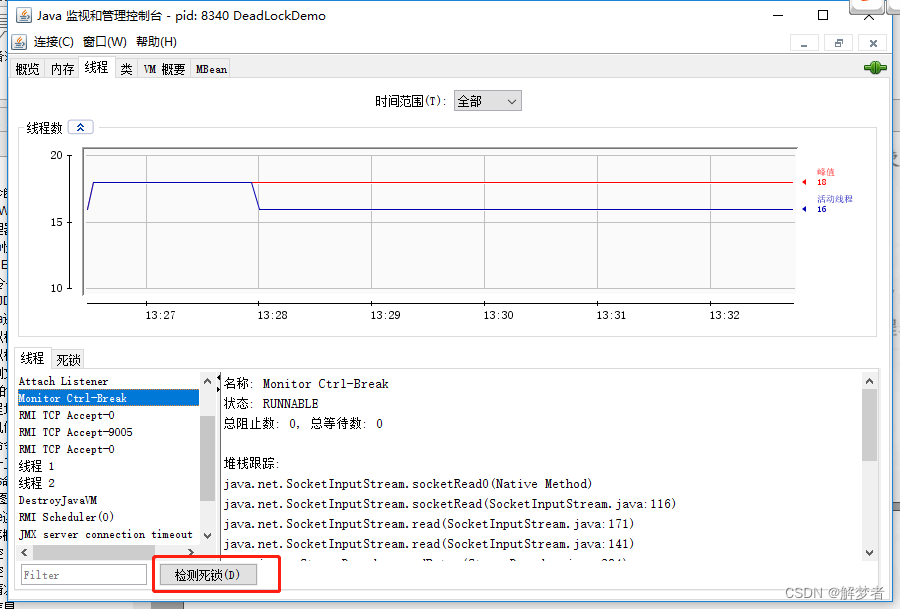
- 线程监控
类似jstack命令,不过这个是可视化的。
界面上有一个"检测死锁 (D)"按钮,点击这个按钮可以自动为你找到发生死锁的线程以及它们的详细信息。
1.2.2 Visual VM:多合一故障处理工具
VisualVM基于NetBeans平台开发,因此他一开始就具备了插件扩展功能的特性,通过插件扩展支持,VisualVM可以做到:
显示虚拟机进程以及进程的配置、环境信息(jps、jinfo)。
监视应用程序的CPU、GC、堆、方法区以及线程的信息(jstat、jstack)。
dump以及分析堆转储快照(jmap、jhat)。
方法级的程序运行性能分析,找到被调用最多、运行时间最长的方法。
离线程序快照:收集程序的运行时配置、线程dump、内存dump等信息建立一个快照,可以将快照发送开发者处进行Bug反馈。
…
二、JVM参数
JVM的参数分为三种:
- 标准参数,
-开头的参数,所有版本JDK都支持,直接输入java查看; - 非标准参数,
-X开头的参数,输入java -X查看,不同的JVM实现不同; - 不稳定参数,-
XX开头的参数,每个版本可能不同,使用java -XX:+PrintFlagsFinal查看。
2.1 常见垃圾回收器组合参数(Serial + Serial Old/ParNew + SerialOld/Parallel Scavenge + Parallel Old/G1)
- -XX:+UseSerialGC = Serial + Serial Old
适用于小型程序。默认情况下不会是这种选项,HotSpot会根据计算及配置和JDK版本自动选择收集器。 - -XX:+UseParNewGC = ParNew + SerialOld
在一般未明确指定Old区垃圾回收器时,就代表用的是SerialOld。这个组合已经很少用(在某些版本中已经废弃)。 - -XX:+UseConc(urrent)MarkSweepGC = ParNew + CMS + Serial Old
红色的字体代表在某些JDK版本上要加上,示例的在JDK1.8上不需要加红色的。 - -XX:+UseParallelGC = Parallel Scavenge + Parallel Old
JDK1.8默认的垃圾回收器组合。 - -XX:+UseParallelOldGC = Parallel Scavenge + Parallel Old
- -XX:+UseG1GC = G1
2.2 【通用JVM参数】
- -Xmn -Xms -Xmx -Xss
年轻代 最小堆(初试堆) 最大堆 栈空间,示例:
java -Xmx3550m -Xms3550m -Xmn2g -Xss128k
ms是memory start的简称,mx是memory max的简称,分别代表最小堆容量和最大堆容量。在通常情况下,服务器在运行过程中,堆空间不断地扩容和回缩,势必造成不必要的系统压力,所以在线上生产环境中,JVM的Xms和Smx设置成一样的大小,避免在GC后调整堆大小带来的额外压力。
- -XX:+UseTLAB
使用TLAB,默认打开【一般不需要调整】。 - -XX:+PrintTLAB
打印TLAB的使用情况【一般不需要调整】。 - -XX:TLABSize
设置TLAB大小【一般不需要调整】。 - -XX:+DisableExplicitGC
使显式调用System.gc()时不起作用 (System.gc()会产生FGC)。
System.gc()默认会触发一次Full GC,如果在代码中不小心调用了System.gc()会导致JVM间歇性的暂停。
- -XX:+PrintGC
打印GC信息。 - -XX:+PrintGCDetails
打印GC详细信息。 - -XX:+PrintHeapAtGC
GC的时候打印堆栈情况。 - -XX:+PrintGCTimeStamps
打印GC发生时的时间戳。 - -XX:+PrintGCApplicationConcurrentTime
打印应用程序时间(重要性低)。 - -XX:+PrintGCApplicationStoppedTime
打印应用程序暂停时长(重要性低)。 - -XX:+PrintReferenceGC
记录回收了多少种不同引用类型的引用(重要性低)。 - -verbose:class
打印类加载详细过程。 - -XX:+PrintVMOptions
可以在程序运行时,打印虚拟机接受的命令行显式参数。 - -XX:+PrintFlagsFinal / -XX:+PrintFlagsInitial
打印出最终的参数/初始的参数。 - -Xloggc:opt/log/gc.log
生成GC日志。 - -XX:MaxTenuringThreshold
升代年龄(该参数主要是控制新生代需要经历多少次GC晋升到老年代中的最大阈值),最大值15。 - -XX:PreBlockSpin
锁自旋次数。 - -XX:CompileThreshold
热点代码检测参数。
以上这些常用JVM参数,不建议更改。
2.3 Parallel常用参数
- -XX:SurvivorRatio
Eden和S区的比例【一般不需要调整】。
该值默认为8,即Eden占新生代的8/10,From幸存区和To幸存区各占新生代的1/10。 - -XX:PreTenureSizeThreshold
大对象阈值,即大于这个值的参数直接在老年代分配。 - -XX:+ParallelGCThreads
并行收集器的线程数,同样适用于CMS,一般设为和CPU核数相同。 - -XX:+UseAdaptiveSizePolicy
自动选择各区大小比例。
开启:-XX:+UseAdaptiveSizePolicy;
关闭:-XX:-UseAdaptiveSizePolicy
在JDK1.8 中,如果使用CMS,无论UseAdaptiveSizePolicy如何设置,都会将UseAdaptiveSizePolicy设置为false;不过不同版本的JDK存在差异;
UseAdaptiveSizePolicy不要和SurvivorRatio参数显示设置搭配使用,一起使用会导致参数失效;
由于AdaptiveSizePolicy会动态调整 Eden、Survivor 的大小,有些情况存在Survivor 被自动调为很小,比如十几MB甚至几MB的可能,这个时候YGC回收掉 Eden区后,还存活的对象进入Survivor 装不下,就会直接晋升到老年代,导致老年代占用空间逐渐增加,从而触发FULL GC,如果一次FULL GC的耗时很长(比如到达几百毫秒),那么在要求高响应的系统就是不可取的。
2.4 CMS常用参数
- -XX:+UseConcMarkSweepGC
使用CMS垃圾回收器。 - -XX:ParallelCMSThreads
CMS线程数量。 - -XX:CMSInitiatingOccupancyFraction
使用多少比例的老年代后开始CMS收集,默认是68%(近似值),如果频繁发生SerialOld卡顿,应该调小,(频繁CMS回收)。 - -XX:+UseCMSCompactAtFullCollection
在FGC时进行压缩。 - -XX:CMSFullGCsBeforeCompaction
多少次FGC之后进行压缩。 - -XX:+CMSClassUnloadingEnabled
回收方法区不用的class。 - -XX:CMSInitiatingPermOccupancyFraction
达到什么比例时进行Perm回收。 - -XX:GCTimeRatio
设置GC时间占用程序运行时间的百分比。 - -XX:MaxGCPauseMillis
停顿时间,是一个建议时间,GC会尝试用各种手段达到这个时间,比如减小年轻代。
2.5 G1常用参数
- -XX:+UseG1GC
使用GC垃圾回收器。 - -XX:MaxGCPauseMillis
每次年轻代垃圾回收的最长时间,如果无法满足此时间,JVM会自动调整年轻代大小,以满足此值。 - -XX:GCPauseIntervalMillis
GC的间隔时间。 - -XX:+G1HeapRegionSize
一个Region的大小可以通过参数-XX:G1HeapRegionSize设定,取值范围从1M到32M,且是2的指数(1 2 4 8 16 32)。如果不设定,那么G1会根据Heap大小自动决定。。
随着size增加,垃圾的存活时间更长,GC间隔更长,但每次GC的时间也会更长
(ZGC对此做了改进,是动态区块大小)。 - -XX:G1NewSizePercent
新生代最小比例,默认为5%。 - -XX:G1MaxNewSizePercent
新生代最大比例,默认为60%。 - -XX:GCTimeRatio
GC时间建议比例,G1会根据这个值调整堆空间,值为0-100的整数。
2.6 JVM参数使用示例
常见的调优用的是 -X命令。
如:java -XX:+PrintFlagsFinal命令可以查看所有的XX参数,如果在Linux环境下,可以+|grep CMS来过滤指定命令。
示例:
package Basic;
import java.util.List;
import java.util.LinkedList;
public class HelloGC {
public static void main(String[] args) {
System.out.println("HelloGC!");
List list = new LinkedList();
for(;;) {
byte[] b = new byte[1024*1024];
list.add(b);
}
}
}
在Eclipse上编写此程序会,会在项目的bin目录下生成对应的HelloGC.class文件,如在"E:\WorkSpace\HelloWorld\bin\Basic"目录:
在CMD窗口,切换到bin目录:

然后就可以调试各种参数。当然也可以在Eclipse中设置JVM参数,此处以CMD方式为例。执行java -XX:+PrintCommandLineFlags Basic.HelloGC命令,可以看默认的虚拟机参数设置:

图中的现象是:内存溢出(要区分内存泄露与内存溢出)。图中的参数:
-XX:InitialHeapSize=65738496 --> 起始堆大小
-XX:MaxHeapSize=1051815936 --> 最大堆大小
-XX:+UseCompressedClassPointers --> 之前提过的类型指针压缩
-XX:+UseCompressedOops --> 普通指针压缩
假如要设置参数,可以使用类似命令:java -Xmn10M -Xms40M -Xmx60M -XX:+PrintCommandLineFlags -XX:+PrintGC Basic.HelloGC。
-Xmn 新生代大小
-Xms 初始堆大小
-Xmx 最大堆大小
-XX:+PrintGC 显示GC回收信息
在打印GC方面,除了PrintGC,还有一些类似的命令:
PrintGCDetails 打印更详细的信息
PrintGCTimeStamps 打印GC时的时间
PrintGCCauses 打印GC产生的原因
上面命令的执行结果:
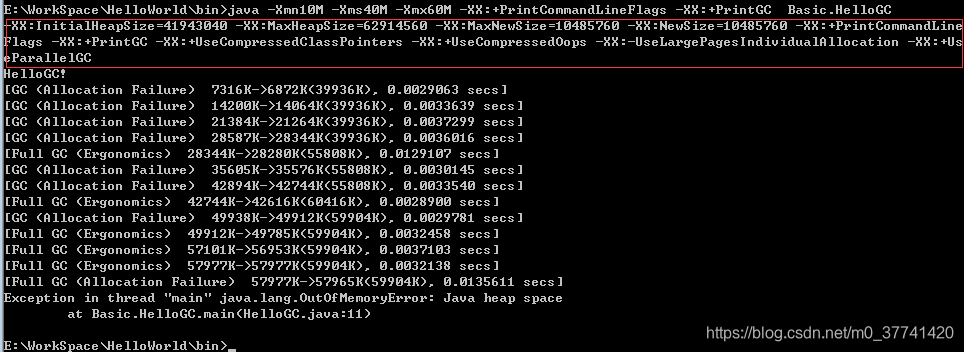
发现最大堆大小、最小堆大小、年轻代大小已经设置成功。
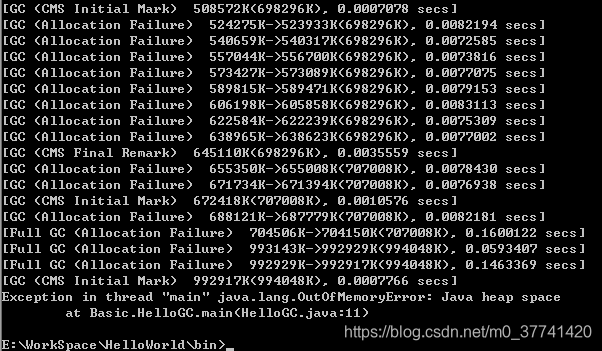
如果使用CMS的话,打印的信息会更详细一些,命令:java -XX:+UseConcMarkSweepGC -XX:+PrintCommandLineFlags -XX:+PrintGC Basic.HelloGC,结果:
2.7 相关问题
2.7.1 JVM选项-XX:+UseCompressedOops有什么作用?为什么要使用
当你将你的应用从32位的JVM迁移到64位的JVM时,由于对象的指针从32 位增加到了64位,因此堆内存会突然增加,差不多要翻倍。这也会对CPU缓存(容量比内存小很多)的数据产生不利的影响。因为,迁移到64位的JVM主要动机在于可以指定最大堆大小,通过压缩OOP可以节省一定的内存。通过-XX:+UseCompressedOops选项,JVM会使用32位的OOP,而不是64位的OOP。
2.7.2 怎样通过Java程序来判断JVM是32位还是64位
可以检查某些系统属性,如sun.arch.data.model或os.arch来获取该信息。
三、GC日志
GC日志级别从低到高,共有Trace,Debug,Info,Warning,Error,Off六种级别,日志级别决定了输
出信息的详细程度,默认级别为Info。
要查看GC日志的详细意义,可以参考:
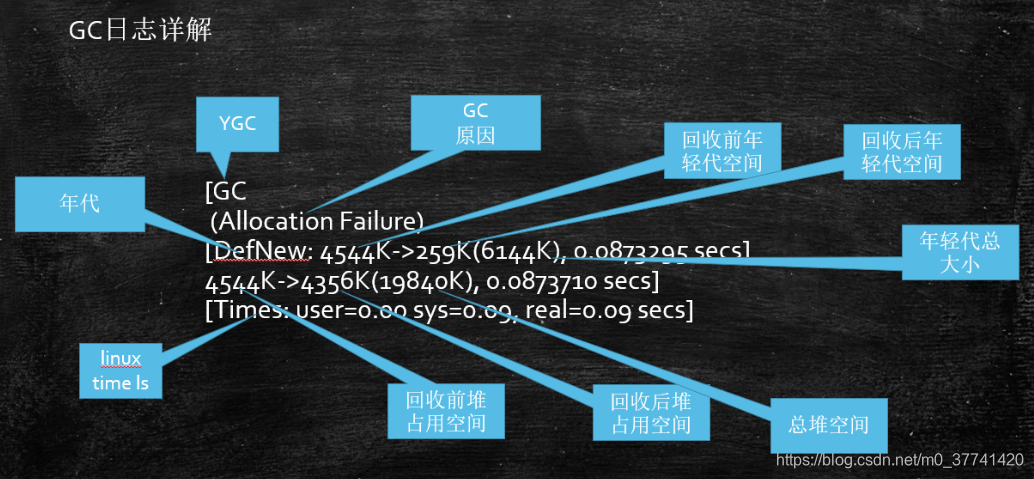
一般未显示"Full GC",就代表是YGC;
4544K->259K,分别代表回收前后的年轻代大小;6144K代表总的年轻代大小;
后面的代表此次回收所用的时间;
接着的4544K->4356K代表整个堆回收前后的大小;
19840K代表整个堆的大小;
后面的时间分别表示占了用户态多少时间、内核态多少时间、总共多少时间,具体为:
real:实际花费的时间,指的是从开始到结束所花费的时间。比如进程在等待I/O完成,这个阻塞时间也会被计算在内。
user:指的是进程在用户态(User Mode)所花费的时间,只统计本进程所使用的时间,是指多核。
sys:指的是进程在核心态(Kernel Mode)花费的CPU时间量,指的是内核中的系统调用所花费的时间,只统计本进程所使用的时间。
发生OOM时的详细dump信息:
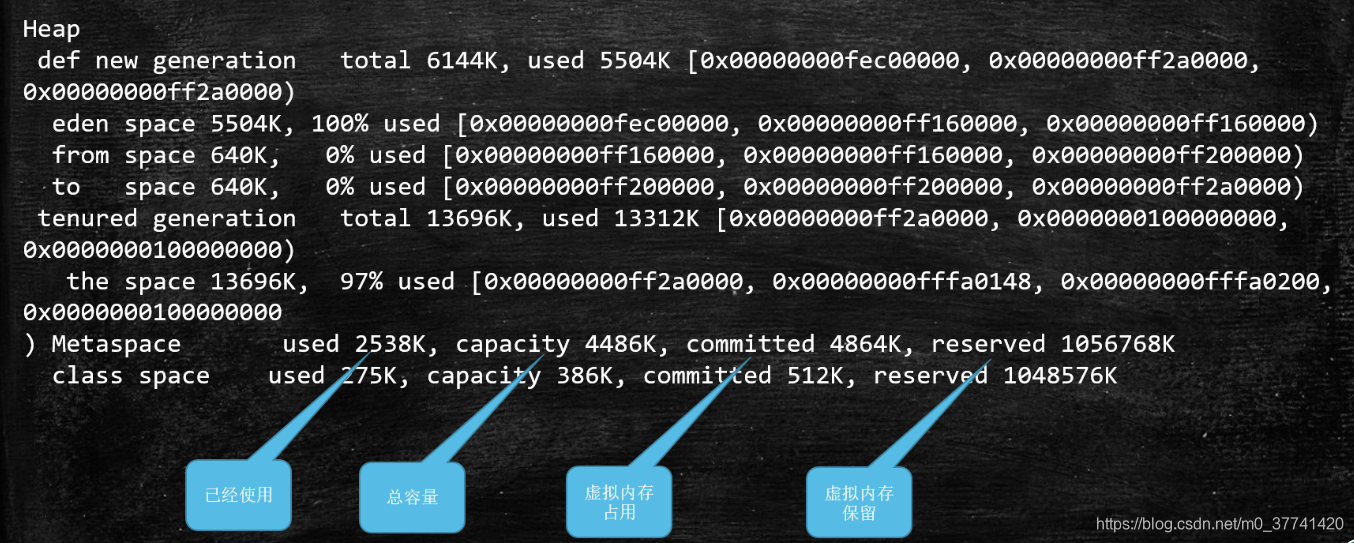
total = eden + 1个survivor。
eden space 5632K, 94% used [0x00000000ff980000,0x00000000ffeb3e28,0x00000000fff00000)
后面的内存地址指的是,起始地址,使用空间结束地址,整体空间结束地址。从第一个地址到第三个地址之间的长度是5632K。从第一个地址到第二个地址代表使用完的地址,占总地址的94%。
Mataspeace,元数据区。最后一个是全元数据区所预留的全部空间,倒数第二个是已经占用的空间,倒数第一个是目前的容量是多少,第一个是真正使用的空间。
3.1 CMS日志
测试命令:
java -Xms20M -Xmx20M -XX:+PrintGCDetails -XX:+UseConcMarkSweepGC com.test.jvm.gc.T15_FullGC_Problem01
小例子:
[GC (Allocation Failure) [ParNew: 6144K->640K(6144K), 0.0265885 secs] 6585K->2770K(19840K), 0.0268035 secs] [Times: user=0.02 sys=0.00, real=0.02 secs]
ParNew:年轻代收集器
6144->640:收集前后的对比
(6144):整个年轻代容量
6585 -> 2770:整个堆的使用情况
(19840):整个堆大小
[GC (CMS Initial Mark) [1 CMS-initial-mark: 8511K(13696K)] 9866K(19840K), 0.0040321 secs] [Times: user=0.01 sys=0.00, real=0.00 secs]
//CMS Initial Mark : 初始标记
//8511 (13696) : 老年代使用(最大)
//9866 (19840) : 整个堆使用(最大)
[CMS-concurrent-mark-start]
[CMS-concurrent-mark: 0.018/0.018 secs] [Times: user=0.01 sys=0.00, real=0.02 secs]
//CMS-concurrent-mark : 并发标记
//这里的时间意义不大,因为是并发执行
[CMS-concurrent-preclean-start]
[CMS-concurrent-preclean: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
//标记Card为Dirty,也称为Card Marking
[GC (CMS Final Remark) [YG occupancy: 1597 K (6144 K)][Rescan (parallel) , 0.0008396 secs][weak refs processing, 0.0000138 secs][class unloading, 0.0005404 secs][scrub symbol table, 0.0006169 secs][scrub string table, 0.0004903 secs][1 CMS-remark: 8511K(13696K)] 10108K(19840K), 0.0039567 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
// CMS Final Remark : 重新标记
//STW阶段,YG occupancy:年轻代占用及容量
//[Rescan (parallel):STW下的存活对象标记
//weak refs processing: 弱引用处理
//class unloading: 卸载用不到的class
//scrub symbol(string) table:
//cleaning up symbol and string tables which hold class-level metadata and
//internalized string respectively
//CMS-remark: 8511K(13696K): 阶段过后的老年代占用及容量
//10108K(19840K): 阶段过后的堆占用及容量
[CMS-concurrent-sweep-start]
[CMS-concurrent-sweep: 0.005/0.005 secs] [Times: user=0.00 sys=0.00, real=0.01 secs]
//标记已经完成,进行并发清理
[CMS-concurrent-reset-start]
[CMS-concurrent-reset: 0.000/0.000 secs] [Times: user=0.00 sys=0.00, real=0.00 secs]
//重置内部结构,为下次GC做准备
对于CMS而言,在日志中更多的是,关注GC是否频繁,和耗费的时间在不在允许范围之内。
3.2 G1日志
G1可以设置参数,表明每次回收建议的暂停时间,虚拟机参考这个时间,动态调整年轻代大小(以尽量拟合到设置的时间)。
G1的调优目标:尽量不要FGC。
在G1的日志中,YGC和Mixed GC常常是混在一起的。
[GC pause (G1 Evacuation Pause) (young) (initial-mark), 0.0015790 secs]
//young -> 年轻代 Evacuation-> 复制存活对象 (即表示是YGC)
//initial-mark 混合回收的阶段,这里是YGC混合老年代回收
[Parallel Time: 1.5 ms, GC Workers: 1] //一个GC线程
[GC Worker Start (ms): 92635.7]
[Ext Root Scanning (ms): 1.1]
[Update RS (ms): 0.0]
[Processed Buffers: 1]
[Scan RS (ms): 0.0]
[Code Root Scanning (ms): 0.0]
[Object Copy (ms): 0.1]
[Termination (ms): 0.0]
[Termination Attempts: 1]
[GC Worker Other (ms): 0.0]
[GC Worker Total (ms): 1.2]
[GC Worker End (ms): 92636.9]
[Code Root Fixup: 0.0 ms]
[Code Root Purge: 0.0 ms]
[Clear CT: 0.0 ms]
[Other: 0.1 ms]
[Choose CSet: 0.0 ms]
[Ref Proc: 0.0 ms]
[Ref Enq: 0.0 ms]
[Redirty Cards: 0.0 ms]
[Humongous Register: 0.0 ms]
[Humongous Reclaim: 0.0 ms]
[Free CSet: 0.0 ms]
[Eden: 0.0B(1024.0K)->0.0B(1024.0K) Survivors: 0.0B->0.0B Heap: 18.8M(20.0M)->18.8M(20.0M)]
//这是此次回收的一个总结:18.8M->18.8M,代表没有回收,有内存泄露。
[Times: user=0.00 sys=0.00, real=0.00 secs]
//以下是混合回收其他阶段
[GC concurrent-root-region-scan-start]
[GC concurrent-root-region-scan-end, 0.0000078 secs]
[GC concurrent-mark-start]
//无法evacuation(复制),进行FGC
[Full GC (Allocation Failure) 18M->18M(20M), 0.0719656 secs]
[Eden: 0.0B(1024.0K)->0.0B(1024.0K) Survivors: 0.0B->0.0B Heap: 18.8M(20.0M)->18.8M(20.0M)], [Metaspace: 38
76K->3876K(1056768K)] [Times: user=0.07 sys=0.00, real=0.07 secs]

















 1790
1790

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









