






前提
这篇文章只分析CoroutineContext的数据结构,并不分析为什么要这做。
数据结构

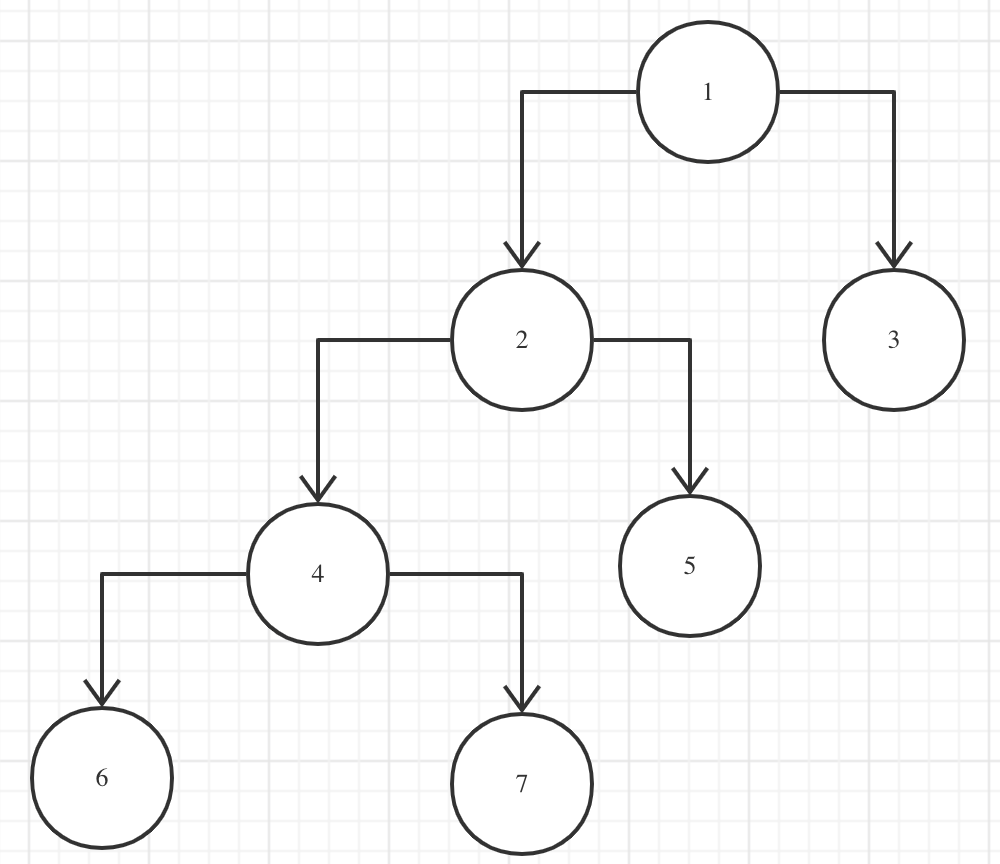
CoroutineContext 可以看做一个特殊的 二叉树,图(1) 就是它的结构:
它的特殊在于:
- 右边只能是非叶节点
- 有左节点,一定有右节点
- 中间节点只是用来连接左右两个子节点,没有实际的作用。
- 每个节点继承 CoroutineContext,看右图(部分继承图)
- 每种类型的节点有自己的plus()、minKey()和get()的方法。
这里大概说一下节点的类型,可以看到 图(2)
- CombinedContext:一定是非叶节点
- Element:一定不是中间节点
为什么是二叉树呢?
分析plus()的源码知道,每次加入给一个element都是CombinedContext来构建中间节点
CombinedContext 的构造函数:
CombinedContext(
private val left: CoroutineContext,
private val element: Element
)
可以发现:left 就是左子树,element就是右子树,element不可能是CombinedContext类型,说明右边只能是叶子节点
Get()
作用:后序遍历RLD,通过key可以来获取Element.
// from CombinedContext
override fun <E : Element> get(key: Key<E>): E? {
var cur = this
while (true) {
cur.element[key]?.let { return it } // 比对是不是 右叶子节点
val next = cur.left
if (next is CombinedContext) { // 判断是不是中间节点
cur = next // 替换为左子树根节点
} else {
return next[key] // 不是CombinedContext就一定是Element
}
}
}
// from EmptyCoroutineContext
public override fun <E : Element> get(key: Key<E>): E? = null
// from Element
public override operator fun <E : Element> get(key: Key<E>): E? = if (this.key === key) this as E else null
-
EmptyCoroutineContext:没有元素,直接为null
-
Element:判断是不是自己,不是就是返回null,是就返回自己
这里特别要注意,element的key不是唯一的,可能多个element有同一个key,因为这样才能实现 加法,也就是plus方法。
-
CombinedContext:先对比右边的元素是不是,再对比左边的元素是不是。
CombinedContext(val left: CoroutineContext, val element: Element)由CombinedContext构造函数可以知道,CombinedContext 右边一定是Element.
示例分析
举个例子:后序遍历RLD,由于非叶节点,没有这里不考虑,所以遍历的顺序就是:3,5,7,6
minusKey()
作用:后序遍历RLD,找到Key相等的elementA,然后删除左子树
// from CombinedContext
public override fun minusKey(key: Key<*>): CoroutineContext {
element[key]?.let { return left } // 如果删除的是右叶子节点,返回左子树
// --- 说明 右边的值不符合,或者不存在 ---
val newLeft = left.minusKey(key)
return when {
newLeft === left -> this // 如果没有要删除的,那么返回本身
newLeft === EmptyCoroutineContext -> element // 如果左子树被删除了,则返回右叶子节
else -> CombinedContext(newLeft, element) // 如果是已经处理完的左子树,则重新组合父节点
}
}
// from Element
public override fun minusKey(key: Key<*>): CoroutineContext = if (this.key === key) EmptyCoroutineContext else this
// from EmptyCoroutineContext
public override fun minusKey(key: Key<*>): CoroutineContext = this
示例:后序遍历RLD,因为非叶节点是CombinedContext,没有key,所以不会被minus
分析可以知道:
- 当叶子节点是Element做减法的时候:如果相等那么返回EmptyCoroutineContext,如果不相等则返回本身。
- 当叶子节点是EmptyCoroutineContext,返回本身。
- 如果是非叶节点
- 如果删除的是右叶子节点,返回左子树
- 如果删除的是左叶子节点
- 如果没有要删除的,那么返回本身,递归向上
- 如果左子树被删除了,则返回右叶子节,递归向上
- 如果是已经处理完的左子树,则重新组合父节点,递归向上
示例分析
第一个示例:

第二个示例:

第三个示例:

fold()
作用:后序遍历LRD,执行operation方法。
这里存在问题,要重新分析。
// from CoroutineContext
public fun <R> fold(initial: R, operation: (R, Element) -> R): R
// from CombinedContext
public override fun <R> fold(initial: R, operation: (R, Element) -> R): R =
operation(left.fold(initial, operation), element)
// from EmptyCoroutineContext
public override fun <R> fold(initial: R, operation: (R, Element) -> R): R = initial
// from Element
public override fun <R> fold(initial: R, operation: (R, Element) -> R): R = operation(initial, this)
分析可以发现:
- CombinedContext:CombinedContext 会递归拿到 最左边的context进行operation操作,再返回和右边的element进行operation
- EmptyCoroutineContext:没有左边的值,直接返回要fold的
- Element:没有左边的值,直接用当前的context 和 要fold的值进行 operation
这里operation 的操作可以往上查找会发现在plus()中用到。
示例分析
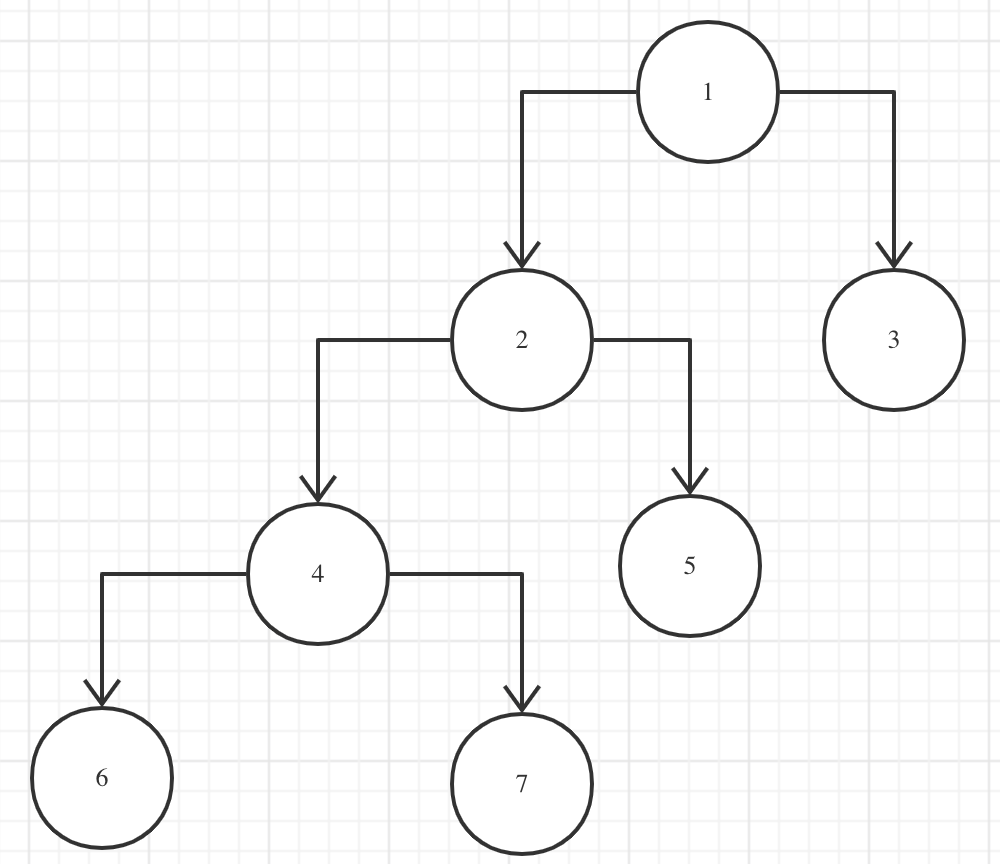
举个例子:后序遍历LRD,先对 (6,7) 操作,获取返回值A,再对 (A,5) 操作,返回B,再对(B,3)操作.
plus()
先看一下源码(加了一些花括号)
// from CoroutineContext
public operator fun plus(context: CoroutineContext): CoroutineContext =
if (context === EmptyCoroutineContext) {
this
} else { // fast path -- avoid lambda creation
context.fold(this) { acc, element -> // acc 代表左边已经构成的树,element是当前树这一层的 右节点
val removed = acc.minusKey(element.key) // 将数据分成两棵树且不重复,removed 和 element
if (removed === EmptyCoroutineContext) { // removed没有数据,直接返回element。
element
} else {
// make sure interceptor is always last in the context (and thus is fast to get when present)
val interceptor = removed[ContinuationInterceptor]
if (interceptor == null) { // 判断removed是具有Interceptor,没有则左子树为removed,右子树为element
CombinedContext(removed, element)
} else {
val left = removed.minusKey(ContinuationInterceptor) // 将removed根据是否具有Interceptor划分
if (left === EmptyCoroutineContext) { // removed 只有一个Interceptor
CombinedContext(element, interceptor)
} else { // 拿到前层级的右子树element 与 不具有interceptor的左子树组合
CombinedContext(CombinedContext(left, element), interceptor)
}
}
}
}
}
从 加树的最左边的叶子 开始加入到 被加树 中。
Fold 主要做三件事:
- 去重
- 去除EmptyCoroutineContext
- 保证ContinuationInterceptor一定处于第一层右边叶子节点。
示例分析
从左边加和右边加 形成的树不一样:

如果有Interceptor,那么他一定是处于树的第一层 右边叶子节点.

两个树相加:

总结
CoroutineContext :定义加入和减去node的标准,以及获取以自己为根节点的标准
Element:继承CoroutineContext,一定是叶子节点,有自己的get,plus,minus的标准
CombinedContext:继承CoroutineContext,一定是非叶节点,有自己的get,plus,minus的标准
对于整个Context的树来说:
- get:后序遍历RLD,对比key获取context,找不到返回null
- minusKey:后序遍历RLD,找到Key相等的elementA,删除对应的element,重新构建树
- fold:后序遍历LRD,意义在于先构建左子树,在递归向上与右子树结合
- plus:后序遍历LRD,需要保证ContinuationInterceptor一定处于第一层右边叶子节点。
附录——如何验证文章的正确性?
自定义Element
class Element1 : AbstractCoroutineContextElement(Key) {
companion object Key : CoroutineContext.Key<Element1>
override fun toString(): String {
return this::class.java.name
}
}
进行加法组合:
val context1 = Element1() + Element2()
val context2 = Element3() + Element4()
println(context1 + Element3())
println(context2 + context1)
println(context1 + context3)















 1909
1909











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









