







1 引言
在前面的文章,我介绍了基于LM studio的大模型部署和API调用,本文将介绍一个实际的项目案例,即利用Python构建一个本地化的知识库来加深大家对于大模型本地化应用的理解。构建基于Python的大模型本地知识库成为提升信息检索效率和保障数据隐私的关键手段。对于企业和个人用户而言,这不仅能加速日常工作的信息查找过程,支持更明智的决策制定,同时也提供了一个深入学习最新自然语言处理技术的机会。相较于直接使用开源工具,亲手搭建这一系统能够加深对底层技术的理解,增强系统的灵活性,并促进技术创新,从而更好地满足特定需求并控制成本。
2 前置知识
零基础本地部署DEEPSEEK大模型教程(LM Studio版)_lm studio部署deepseek-CSDN博客
LLM Studio本地部署deepseek的API调用,基于Python实现简易对话客户端_llmstudio本地接口-CSDN博客
3. 技术背景和设计架构
3.1 技术背景
本项目采用了基于检索增强生成(Retrieval-Augmented Generation, RAG)的技术路线。RAG结合了信息检索(IR)和序列到序列(Seq2Seq)模型的优点,通过从大量文档中检索相关信息并将其作为上下文提供给生成模型,可以有效提升回答的准确性和相关性。RAG能够利用外部知识库来补充模型的知识盲点,特别适用于需要引用具体文档内容或事实的任务。
文档预处理
系统首先需要对不同格式的文档进行读取和预处理。这是因为直接处理原始文档格式效率低下且难以管理。采用RecursiveCharacterTextSplitter对文本进行分割,确保每个文本块大小适中,既不过于冗长导致检索不准确,也不过于简短影响理解。此步骤为后续的向量化和索引建立奠定了基础。
向量化与索引建立
选择HuggingFace Embeddings进行文本嵌入是因为它提供了高效、高质量的文本表示方法,这些表示能捕捉文本的语义信息,从而支持精确的相似度搜索。Chroma作为向量数据库的选择,则是因为其优秀的性能和易用性,适合存储和查询大规模文本向量。同时,BM25模型被用来构建额外的检索层,它根据词频和逆文档频率计算文档的相关性得分,这对于处理未见过的查询尤其有用。这种混合检索策略能够在保持高召回率的同时提高检索精度。
混合检索机制
RAG的核心在于将检索得到的信息与生成模型结合起来,以产生更加精准的回答。通过结合向量相似度搜索和BM25检索结果,系统能够提供比单一方法更全面的答案。这种方式不仅增强了系统的鲁棒性,还能更好地应对复杂的查询场景。
3.2 整体架构图

3.3 核心模块
-
文档处理层:PDF/Word/TXT解析
-
向量化层:文本分块与嵌入模型
-
存储层:Chroma向量数据库
-
检索层:BM25+向量混合检索
-
生成层:DeepSeek API调用
-
交互层:GUI可视化界面
4. 环境准备
# 基础环境
pip install python>=3.10
conda install pytorch torchvision torchaudio -c pytorch #需要自行安装pytorch
# 核心依赖
pip install langchain chromadb rank-bm25 pypdf2 python-docx \
sentence-transformers pillow requests -i https://mirrors.aliyun.com/pypi/simple/
# 可选GUI组件
pip install customtkinter==5.2.05. 完整代码
import tkinter as tk
from tkinter import ttk, filedialog, scrolledtext, messagebox
import requests
import os
from threading import Thread
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.vectorstores import Chroma
from langchain.embeddings import HuggingFaceEmbeddings
from rank_bm25 import BM25Okapi
from functools import lru_cache
import PyPDF2
import docx
import json
from typing import List, Dict, Tuple
import hashlib
class DeepSeekRAGApp:
def __init__(self, root):
self.root = root
self.root.title("DeepSeek Chat with Advanced RAG")
self.root.geometry("1000x700")
# 初始化聊天历史
self.chat_history = []
# DeepSeek API 配置
self.api_url = "http://10.80.32.223:1234/v1/chat/completions"
self.headers = {"Content-Type": "application/json"}
self.model = "deepseek-r1-distill-qwen-32b"
# RAG 增强配置
self.embedding_model = "sentence-transformers/all-MiniLM-L6-v2"
self.embeddings = HuggingFaceEmbeddings(model_name=self.embedding_model)
self.text_splitter = RecursiveCharacterTextSplitter(
chunk_size=500,
chunk_overlap=100,
length_function=len
)
self.vector_db = None
self.vector_db_path = "./chroma_db"
self.bm25_index = None
self.all_chunks = [] # 用于 BM25 检索的原始文本
self.cache_file = "./query_cache.json"
self.query_cache = {} # 初始化查询缓存
# 初始化 UI 和组件
self.setup_ui()
self.load_cache()
self.load_existing_knowledge_base()
def setup_ui(self):
"""初始化用户界面(带状态栏)"""
# 主框架
main_frame = tk.Frame(self.root)
main_frame.pack(fill=tk.BOTH, expand=True, padx=10, pady=10)
# 聊天记录显示
self.chat_display = scrolledtext.ScrolledText(
main_frame, wrap=tk.WORD, state='disabled', font=("Arial", 12))
self.chat_display.pack(fill=tk.BOTH, expand=True)
# 状态栏
self.status_var = tk.StringVar()
self.status_var.set("就绪 | 知识库: 未加载")
status_bar = tk.Label(main_frame, textvariable=self.status_var, bd=1, relief=tk.SUNKEN, anchor=tk.W)
status_bar.pack(fill=tk.X)
# 输入框架
input_frame = tk.Frame(self.root)
input_frame.pack(fill=tk.X, padx=10, pady=5)
# 用户输入框
self.user_input = tk.Text(input_frame, height=4, font=("Arial", 12))
self.user_input.pack(side=tk.LEFT, fill=tk.X, expand=True)
# 按钮框架
button_frame = tk.Frame(input_frame)
button_frame.pack(side=tk.RIGHT, fill=tk.Y)
# 发送按钮
self.send_button = ttk.Button(
button_frame, text="发送", command=self.send_message, width=10)
self.send_button.pack(pady=2)
# 知识库管理按钮
kb_button_frame = tk.Frame(self.root)
kb_button_frame.pack(fill=tk.X, padx=10, pady=5)
self.upload_kb_button = ttk.Button(
kb_button_frame, text="上传知识库", command=self.upload_knowledge_base)
self.upload_kb_button.pack(side=tk.LEFT, padx=5)
self.incremental_update_button = ttk.Button(
kb_button_frame, text="增量更新", command=self.incremental_update)
self.incremental_update_button.pack(side=tk.LEFT, padx=5)
self.clear_kb_button = ttk.Button(
kb_button_frame, text="清空知识库", command=self.clear_knowledge_base)
self.clear_kb_button.pack(side=tk.LEFT, padx=5)
self.clear_chat_button = ttk.Button(
kb_button_frame, text="清空聊天", command=self.clear_chat)
self.clear_chat_button.pack(side=tk.RIGHT, padx=5)
# ------------------------ RAG 核心功能 ------------------------
def hybrid_search(self, query: str, top_k: int = 3) -> List[str]:
"""混合检索(BM25 + 向量搜索)"""
if not self.vector_db or not self.bm25_index:
return []
# 向量搜索
vector_results = self.vector_db.similarity_search(query, k=top_k)
vector_texts = [doc.page_content for doc in vector_results]
# BM25 搜索
tokenized_query = query.split()
bm25_scores = self.bm25_index.get_scores(tokenized_query)
top_indices = sorted(range(len(bm25_scores)), key=lambda i: -bm25_scores[i])[:top_k]
bm25_texts = [self.all_chunks[i] for i in top_indices]
# 合并去重
combined = list(set(vector_texts + bm25_texts))
return combined[:top_k*2] # 返回稍多结果供后续筛选
@lru_cache(maxsize=100)
def cached_search(self, query: str) -> Tuple[List[str], str]:
"""带缓存的检索(使用查询内容的哈希作为键)"""
query_hash = hashlib.md5(query.encode()).hexdigest()
# 检查缓存
if query_hash in self.query_cache:
return self.query_cache[query_hash], "[缓存] "
# 实际检索
results = self.hybrid_search(query)
self.query_cache[query_hash] = results
return results, ""
def build_prompt(self, question: str, context: List[str]) -> str:
"""构建增强版提示词"""
if not context:
return question
context_str = "\n\n".join([f"[参考 {i+1}]: {text}" for i, text in enumerate(context)])
return f"""请根据以下参考内容回答问题:
{context_str}
问题:{question}
要求:
1. 如果参考内容与问题无关,请回答"根据已有知识无法回答"
2. 引用参考内容时注明出处如[参考1]
"""
# ------------------------ 知识库管理 ------------------------
def load_existing_knowledge_base(self):
"""加载已存在的知识库"""
if os.path.exists(self.vector_db_path):
try:
self.vector_db = Chroma(
persist_directory=self.vector_db_path,
embedding_function=self.embeddings
)
# 重建 BM25 索引
self.all_chunks = [doc.page_content for doc in self.vector_db.get()['documents']]
self.bm25_index = BM25Okapi([doc.split() for doc in self.all_chunks])
self.update_status(f"知识库已加载 | 文档块: {len(self.all_chunks)}")
except Exception as e:
self.update_status(f"加载知识库失败: {str(e)}")
def upload_knowledge_base(self):
"""上传并构建完整知识库"""
file_paths = filedialog.askopenfilenames(
filetypes=[("Text Files", "*.txt"), ("PDF Files", "*.pdf"), ("Word Files", "*.docx")])
if not file_paths:
return
try:
texts = self.read_files(file_paths)
chunks = self.split_texts(texts)
self.create_vector_db(chunks)
self.update_status(f"知识库构建完成 | 文档块: {len(chunks)}")
messagebox.showinfo("成功", "知识库构建完成!")
except Exception as e:
messagebox.showerror("错误", f"知识库构建失败: {str(e)}")
def incremental_update(self):
"""增量更新知识库"""
file_paths = filedialog.askopenfilenames(
filetypes=[("Text Files", "*.txt"), ("PDF Files", "*.pdf"), ("Word Files", "*.docx")])
if not file_paths:
return
try:
texts = self.read_files(file_paths)
new_chunks = self.split_texts(texts)
if self.vector_db is None:
self.create_vector_db(new_chunks)
else:
# 增量添加
self.vector_db.add_texts(new_chunks)
self.all_chunks.extend(new_chunks)
self.bm25_index = BM25Okapi([doc.split() for doc in self.all_chunks])
self.update_status(f"增量更新完成 | 新增: {len(new_chunks)} | 总计: {len(self.all_chunks)}")
messagebox.showinfo("成功", "知识库更新完成!")
except Exception as e:
messagebox.showerror("错误", f"增量更新失败: {str(e)}")
def clear_knowledge_base(self):
"""清空知识库"""
if messagebox.askyesno("确认", "确定要清空知识库吗?"):
try:
if os.path.exists(self.vector_db_path):
import shutil
shutil.rmtree(self.vector_db_path)
self.vector_db = None
self.all_chunks = []
self.bm25_index = None
self.update_status("知识库已清空")
messagebox.showinfo("成功", "知识库已清空")
except Exception as e:
messagebox.showerror("错误", f"清空失败: {str(e)}")
def read_files(self, file_paths: List[str]) -> List[str]:
"""读取多种格式文件"""
texts = []
for file_path in file_paths:
try:
if file_path.endswith(".txt"):
with open(file_path, "r", encoding="utf-8") as f:
texts.append(f.read())
elif file_path.endswith(".pdf"):
with open(file_path, "rb") as f:
pdf_reader = PyPDF2.PdfReader(f)
texts.append("\n".join([page.extract_text() for page in pdf_reader.pages]))
elif file_path.endswith(".docx"):
doc = docx.Document(file_path)
texts.append("\n".join([para.text for para in doc.paragraphs]))
except Exception as e:
self.log_error(f"文件读取错误 {os.path.basename(file_path)}: {str(e)}")
return texts
def split_texts(self, texts: List[str]) -> List[str]:
"""文本分块处理"""
return self.text_splitter.split_text("\n\n".join(texts))
def create_vector_db(self, chunks: List[str]):
"""创建向量数据库"""
self.vector_db = Chroma.from_texts(
chunks,
self.embeddings,
persist_directory=self.vector_db_path
)
self.all_chunks = chunks
self.bm25_index = BM25Okapi([doc.split() for doc in chunks])
# ------------------------ 聊天功能 ------------------------
def send_message(self):
"""发送消息(带RAG检索)"""
question = self.user_input.get("1.0", tk.END).strip()
if not question:
return
self.update_chat_display("你", question)
self.user_input.delete("1.0", tk.END)
# 在新线程中处理
Thread(target=self.process_query, args=(question,)).start()
def process_query(self, question: str):
"""处理查询流程"""
try:
# 检索相关文档
context, cache_flag = self.cached_search(question)
if context:
self.update_chat_display("系统",
f"{cache_flag}检索到 {len(context)} 条相关内容")
# 构建提示词
prompt = self.build_prompt(question, context)
self.chat_history.append({"role": "user", "content": prompt})
# 调用API
response = self.call_deepseek_api(self.chat_history.copy())
if response:
self.chat_history.append({"role": "assistant", "content": response})
self.update_chat_display("DeepSeek", response)
except Exception as e:
self.update_chat_display("系统", f"处理出错: {str(e)}")
def call_deepseek_api(self, messages: List[Dict]) -> str:
"""调用DeepSeek API"""
try:
payload = {
"model": self.model,
"messages": messages,
"temperature": 0.7
}
response = requests.post(
self.api_url,
headers=self.headers,
json=payload,
timeout=60
)
response.raise_for_status()
return response.json()["choices"][0]["message"]["content"]
except requests.exceptions.RequestException as e:
self.log_error(f"API调用失败: {str(e)}")
return None
# ------------------------ 缓存管理 ------------------------
def load_cache(self):
"""加载查询缓存"""
if os.path.exists(self.cache_file):
try:
with open(self.cache_file, "r", encoding="utf-8") as f:
self.query_cache = json.load(f)
except:
self.log_error("缓存加载失败")
self.query_cache = {}
def save_cache(self):
"""保存查询缓存"""
try:
with open(self.cache_file, "w", encoding="utf-8") as f:
json.dump(self.query_cache, f)
except:
self.log_error("缓存保存失败")
# ------------------------ UI 工具 ------------------------
def update_chat_display(self, sender: str, message: str):
"""更新聊天显示(线程安全)"""
def _update():
self.chat_display.config(state='normal')
self.chat_display.insert(tk.END, f"{sender}: {message}\n\n")
self.chat_display.config(state='disabled')
self.chat_display.see(tk.END)
self.root.after(0, _update)
def update_status(self, message: str):
"""更新状态栏"""
self.status_var.set(message)
def log_error(self, message: str):
"""记录错误"""
self.update_chat_display("系统错误", message)
def clear_chat(self):
"""清空聊天记录"""
self.chat_display.config(state='normal')
self.chat_display.delete("1.0", tk.END)
self.chat_display.config(state='disabled')
self.chat_history = []
def on_closing(self):
"""窗口关闭事件"""
self.save_cache()
self.root.destroy()
if __name__ == "__main__":
root = tk.Tk()
app = DeepSeekRAGApp(root)
root.protocol("WM_DELETE_WINDOW", app.on_closing)
root.mainloop()6. 关键代码解析
6.1. RAG核心功能模块
混合检索实现 (hybrid_search)
def hybrid_search(self, query: str, top_k: int = 3) -> List[str]:
# 向量搜索 (语义匹配)
vector_results = self.vector_db.similarity_search(query, k=top_k)
vector_texts = [doc.page_content for doc in vector_results]
# BM25搜索 (关键词匹配)
tokenized_query = query.split()
bm25_scores = self.bm25_index.get_scores(tokenized_query)
top_indices = sorted(range(len(bm25_scores)), key=lambda i: -bm25_scores[i])[:top_k]
bm25_texts = [self.all_chunks[i] for i in top_indices]
# 合并去重
return list(set(vector_texts + bm25_texts))[:top_k*2]关键点:
-
同时使用向量搜索(语义相似度)和BM25(关键词匹配)
-
set()去重确保结果多样性 -
返回
top_k*2条结果供后续筛选
提示词构建 (build_prompt)
def build_prompt(self, question: str, context: List[str]) -> str:
context_str = "\n\n".join([f"[参考 {i+1}]: {text}" for i, text in enumerate(context)])
return f"""请根据以下参考内容回答问题:
{context_str}
问题:{question}
要求:
1. 如果参考内容与问题无关,请回答"根据已有知识无法回答"
2. 引用参考内容时注明出处如[参考1]
"""设计要点:
-
明确标注知识来源([参考1]格式)
-
加入回答约束条件防止幻觉
-
多文档片段用
\n\n分隔提高可读性
6.2. 知识库管理模块
增量更新 (incremental_update)
def incremental_update(self):
file_paths = filedialog.askopenfilenames() # 获取新文件
new_chunks = self.split_texts(self.read_files(file_paths))
if self.vector_db is None:
self.create_vector_db(new_chunks) # 首次创建
else:
self.vector_db.add_texts(new_chunks) # 增量添加
self.all_chunks.extend(new_chunks)
self.bm25_index = BM25Okapi([doc.split() for doc in self.all_chunks]) # 重建索引优势:
-
避免全量重建的成本
-
动态更新BM25索引
-
保持原有知识不变
文本分块处理 (split_texts)
def split_texts(self, texts: List[str]) -> List[str]:
return self.text_splitter.split_text("\n\n".join(texts))参数说明:
-
chunk_size=500:每个文本块约500字符 -
chunk_overlap=100:块间重叠100字符防止信息截断 -
separators:优先按段落/句子分界
6.3. 聊天交互模块
异步消息处理 (send_message + process_query)
def send_message(self):
question = self.user_input.get("1.0", tk.END).strip()
Thread(target=self.process_query, args=(question,)).start() # 新线程处理
def process_query(self, question: str):
context, _ = self.cached_search(question) # 检索
prompt = self.build_prompt(question, context) # 构建提示
response = self.call_deepseek_api([{"role": "user", "content": prompt}])
self.update_chat_display("DeepSeek", response) # 更新UI关键设计:
-
使用
Thread防止界面卡顿 -
分离UI线程和工作线程
-
消息处理流水线化
API调用封装 (call_deepseek_api)
def call_deepseek_api(self, messages: List[Dict]) -> str:
payload = {
"model": self.model,
"messages": messages,
"temperature": 0.7 # 控制生成随机性
}
response = requests.post(self.api_url, json=payload, timeout=60)
return response.json()["choices"][0]["message"]["content"]参数说明:
-
temperature=0.7:平衡创造性和准确性 -
timeout=60:避免长时间无响应 -
兼容OpenAI API格式
6.4. 缓存优化模块
两级缓存系统
@lru_cache(maxsize=100) # 内存缓存
def cached_search(self, query: str) -> Tuple[List[str], str]:
query_hash = hashlib.md5(query.encode()).hexdigest()
if query_hash in self.query_cache: # 磁盘缓存
return self.query_cache[query_hash], "[缓存] "
# ...存储到self.query_cache并定期持久化缓存策略:
-
内存缓存:LRU算法保留最近100次查询
-
磁盘缓存:JSON持久化避免重启丢失
-
MD5哈希化查询内容作为键
6.5. UI关键组件
消息显示优化 (update_chat_display)
def update_chat_display(self, sender: str, message: str):
self.chat_display.config(state='normal')
# 颜色标记不同发送方
if sender == "你":
self.chat_display.tag_config("user", foreground="blue")
self.chat_display.insert(tk.END, f"{sender}: ", "user")
elif sender == "DeepSeek":
self.chat_display.tag_config("ai", foreground="green")
self.chat_display.insert(tk.END, f"{sender}: ", "ai")
# ...插入消息并自动滚动交互优化:
-
不同角色使用不同颜色
-
保持滚动条在底部
-
state='disabled'防止误编辑
状态管理
def update_status(self, message: str):
"""实时更新底部状态栏"""
self.status_var.set(f"{datetime.now().strftime('%H:%M:%S')} | {message}")显示信息:
-
当前时间戳
-
知识库文档数
-
最近操作状态
7. 实操演示
第一步 启动本地大模型服务,也可以是网上的大模型API服务
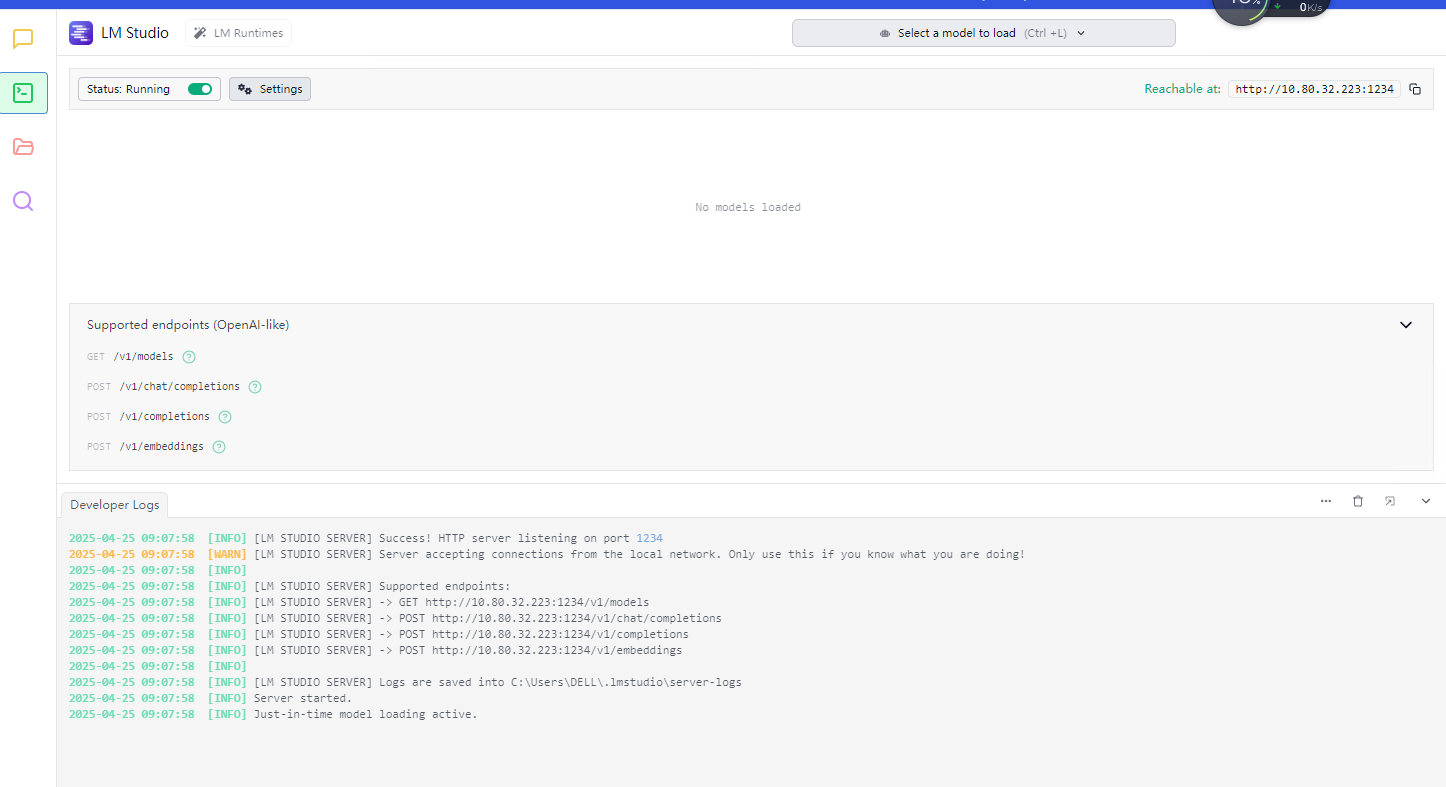
第二步 运行代码
这个步骤可能会有模型在互联网上无法直接下载,需要自行下载
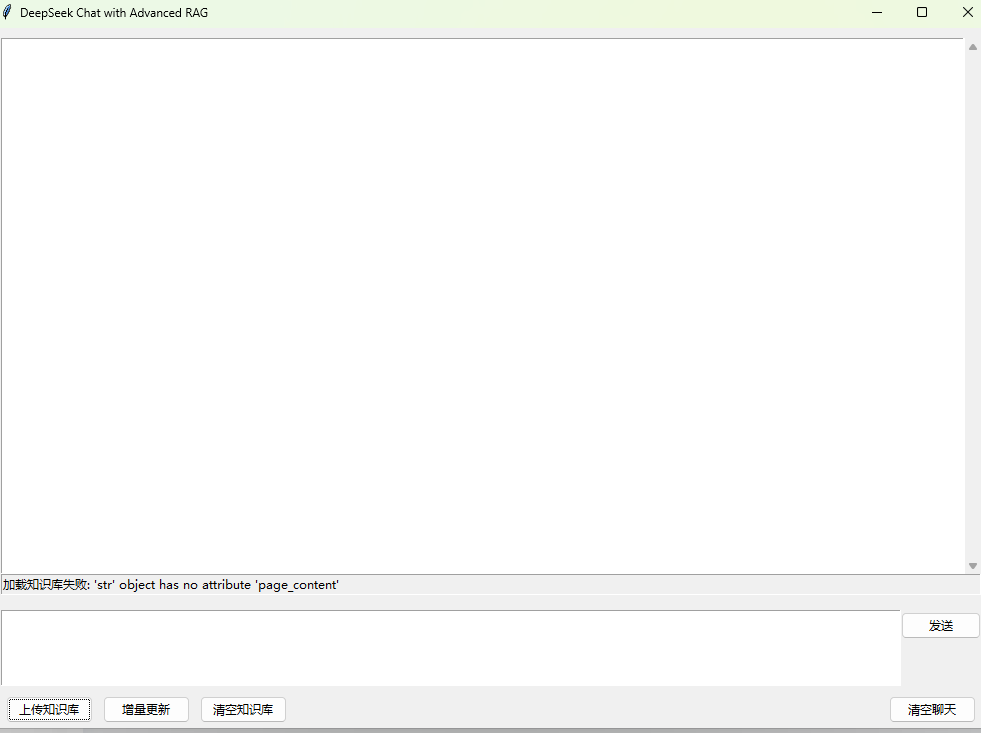
第三步 上传本地知识库
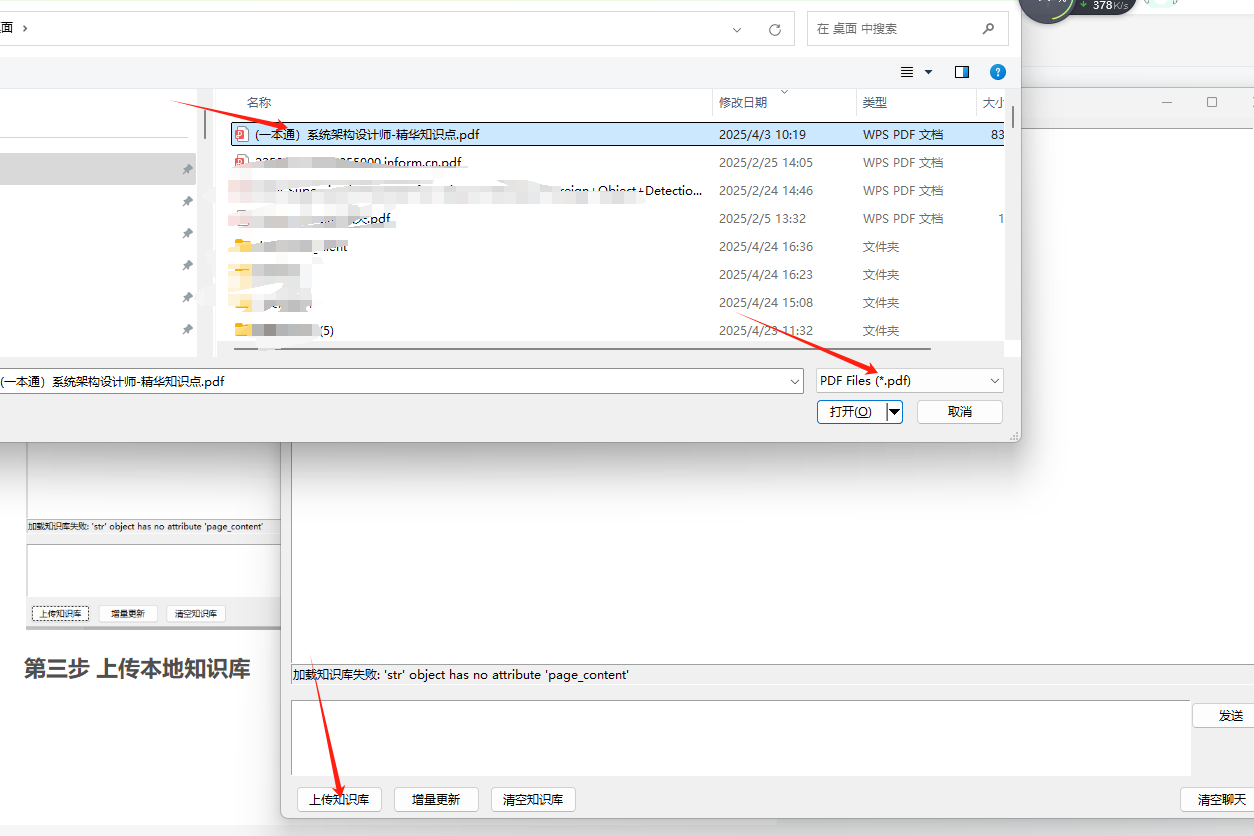
这个步骤可能需要一定时间 ,文档可能不能太大,受本地计算资源的影响
第四步 进行问答
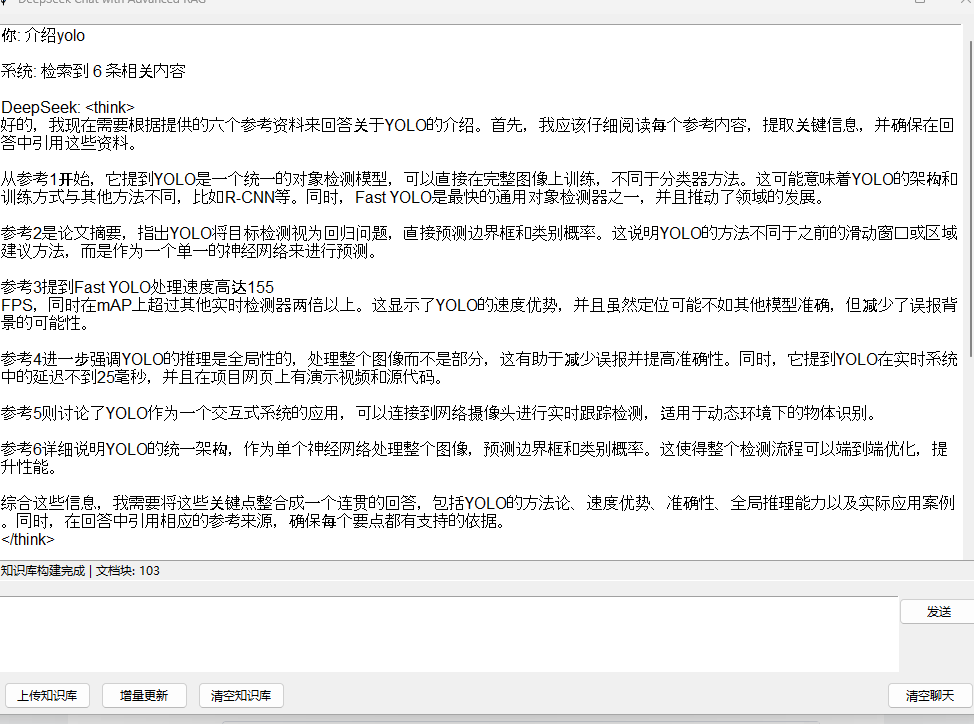
8 练习作业
- 服务端选择不同的模型,例如gemma-3
- 尝试使用deepseek等大模型厂家所提供的api
- 将客户端转至网页端,制作更精美的交互界面


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









