







CV计算机视觉核心06-计算机视觉中的图像分类实例(以矿泉水瓶分类作为案例)
一、自建数据集的加载
方法1:
以下是不借助API,手动完成自建数据的读取加载:
数据的分类目录结构:
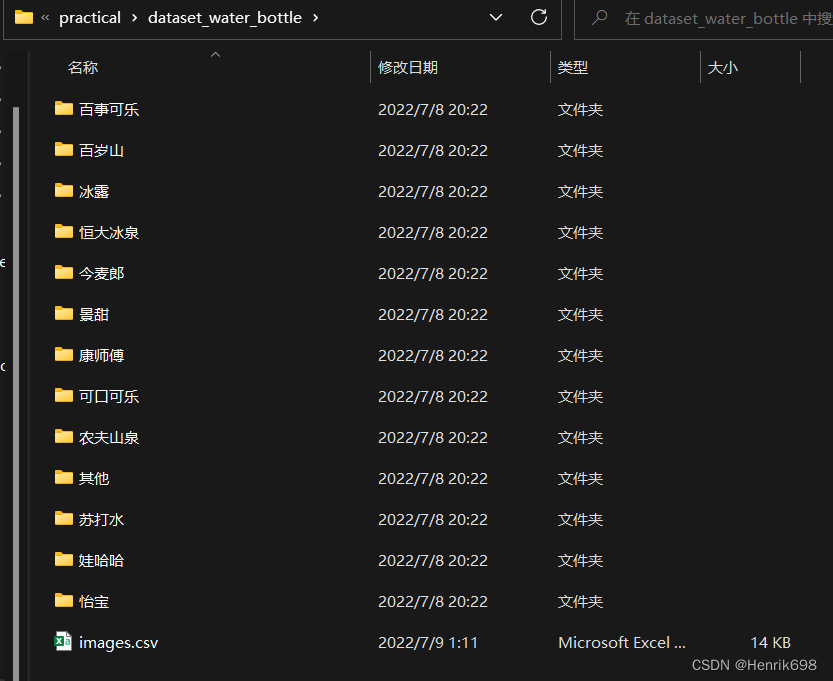
文件名:bottle.py
import torch
import os, glob
import random, csv
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
import visdom
import time
import torchvision
class Bottle(Dataset):
def __init__(self, root, resize, mode):
super(Bottle, self).__init__()
self.root = root
self.resize = resize
self.name2label = {}
for name in sorted(os.listdir(os.path.join(root))):
if not os.path.isdir(os.path.join(root, name)):
continue
self.name2label[name] = len(self.name2label.keys())
print(self.name2label)
# image_path,label
self.images, self.labels = self.load_csv('images.csv')
if mode == 'train': # 取60%做training
# len(self.images)的长度是1167,取60%做为train模式的图片
self.images = self.images[:int(0.6 * len(self.images))]
self.labels = self.labels[:int(0.6 * len(self.labels))]
elif mode == 'val': # 取20%做validation, 60%-80%
self.images = self.images[int(0.6 * len(self.images)):int(0.8 * len(self.images))]
self.labels = self.labels[int(0.6 * len(self.labels)):int(0.8 * len(self.labels))]
else: # mode为test,取80%到最末尾
self.images = self.images[int(0.8 * len(self.images)):]
self.labels = self.labels[int(0.8 * len(self.labels)):]
def load_csv(self, filename):
if not os.path.exists(os.path.join(self.root, filename)):
images = []
for name in self.name2label.keys():
# 'bottom\\'
images += glob.glob(os.path.join(self.root, name, '*.png'))
images += glob.glob(os.path.join(self.root, name, '*.jpg'))
images += glob.glob(os.path.join(self.root, name, '*.jpeg'))
print(len(images), images)
random.shuffle(images)
with open(os.path.join(self.root, filename), mode='w', newline='') as f:
writer = csv.writer(f)
for img in images:
name = img.split('\\')[-2]
label = self.name2label[name]
writer.writerow([img, label])
print('writen into csv file:', filename)
# read from csv file
images, labels = [], []
with open(os.path.join(self.root, filename)) as f:
reader = csv.reader(f)
for row in reader:
img, label = row
label = int(label)
images.append(img)
labels.append(label)
print('len(images):', len(images))
print('len(labels):', len(labels))
assert len(images) == len(labels)
print('read csv file:', filename)
return images, labels
def __len__(self):
return len(self.images)
# 这里传入的参数x是normalize过后的
def denormalize(self, x_hat):
mean = [0.557, 0.517, 0.496]
std = [0.210, 0.216, 0.222]
# normalize的过程:
# x_hat = (x-mean)/std
# x = x_hat*std+mean 这个就是逆操作过程
# x = [c,h,w]
# mean = [3] => boardcasting后
# unsqueeze()函数起升维的作用,参数表示在哪个地方加一个维度
mean = torch.tensor(mean).unsqueeze(1).unsqueeze(1)
std = torch.tensor(std).unsqueeze(1).unsqueeze(1)
print('mean.shape,std.shape:',mean.shape,std.shape)
x = x_hat * std + mean
return x
def __getitem__(self, idx):
# idx数值范围是[0-len(images)]
# self.images保存了所有的数据;self.labels保存了所有数据对应的label信息;
# img是一个string类型(还不是具体的图片,只是路径):'pokemon\\bulbasaur\\00000000.png'
# label是一个整数类型
img, label = self.images[idx], self.labels[idx]
tf = transforms.Compose([
# string path => image data
lambda x: Image.open(x).convert('RGB'),
transforms.Resize((int(self.resize * 1.25), int(self.resize * 1.25))),
transforms.RandomRotation(15),
transforms.CenterCrop(self.resize),
transforms.ToTensor(),
# normMean = [0.55671153 0.51730426 0.49580584]
# normStd = [0.21057842 0.21577705 0.222336]
transforms.Normalize([0.557, 0.517, 0.496], [0.210, 0.216, 0.222])
])
img = tf(img)
label = torch.tensor(label)
return img, label
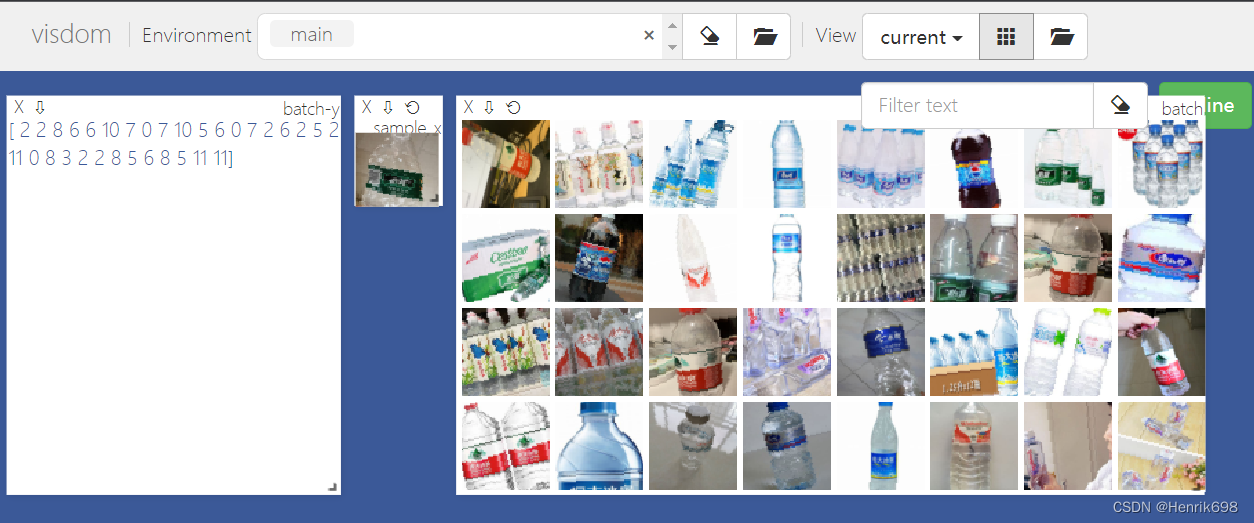
def main():
viz = visdom.Visdom()
db = Bottle('dataset_water_bottle', 64, 'train')
x, y = next(iter(db))
print('sample:', x.shape, y.shape, y)
viz.image(db.denormalize(x),win = 'sample_x',opts=dict(title="sample_x"))
loader = DataLoader(db,batch_size=32,shuffle=True)
for x,y in loader:
viz.images(db.denormalize(x),nrow=8,win='batch', opts=dict(title = 'batch'))
viz.text(str(y.numpy()), win='label',opts=dict(title='batch-y'))
time.sleep(20)
if __name__ == '__main__':
main()

方法2:
借助API直接实现数据的加载:
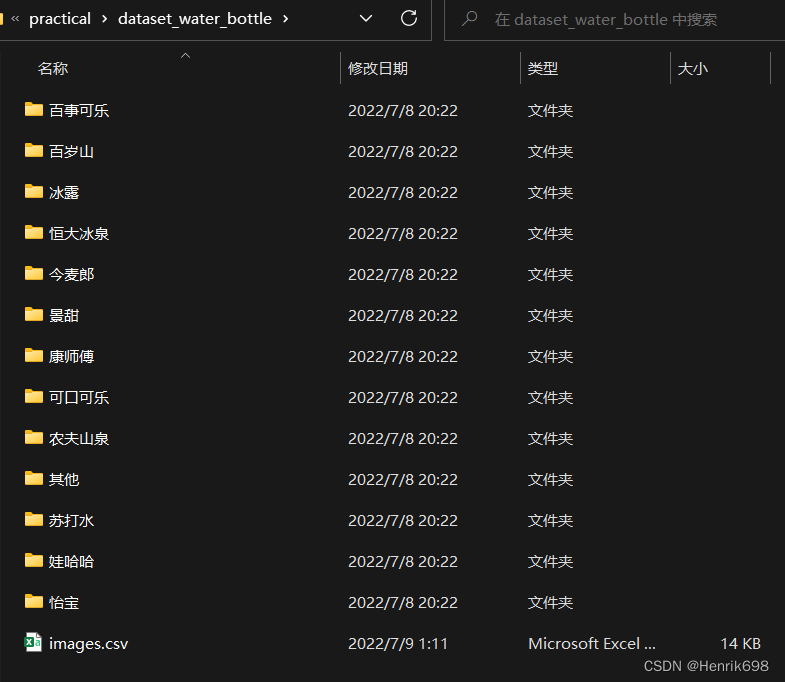
前提:
图片分类存放在文件夹中的目录结构必须是以下这样:
以下代码是通过API快速读取数据的,这样就不需要我们自己手动编写类,来实现数据集的加载了。
import torch
import os, glob
import random, csv
from torch.utils.data import Dataset, DataLoader
from torchvision import transforms
from PIL import Image
import visdom
import time
import torchvision
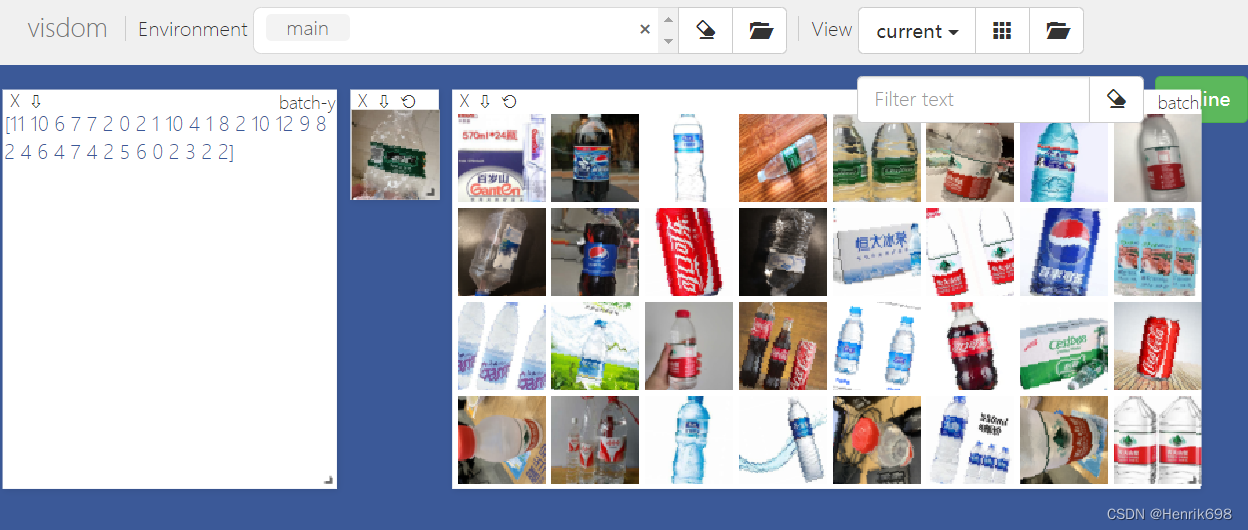
def main():
viz = visdom.Visdom()
tf = transforms.Compose([
transforms.Resize((int(64 * 1.25), int(64 * 1.25))),
transforms.RandomRotation(15),
transforms.CenterCrop(64),
transforms.ToTensor(),
transforms.Normalize([0.557, 0.517, 0.496], [0.210, 0.216, 0.222])
])
db = torchvision.datasets.ImageFolder(root='dataset_water_bottle',transform=tf)
def denormalize(x_hat):
mean = [0.557, 0.517, 0.496]
std = [0.210, 0.216, 0.222]
# normalize的过程:
# x_hat = (x-mean)/std
# x = x_hat*std+mean 这个就是逆操作过程
# x = [c,h,w]
# mean = [3] => boardcasting后
# unsqueeze()函数起升维的作用,参数表示在哪个地方加一个维度
mean = torch.tensor(mean).unsqueeze(1).unsqueeze(1)
std = torch.tensor(std).unsqueeze(1).unsqueeze(1)
print('mean.shape,std.shape:',mean.shape,std.shape)
x = x_hat * std + mean
return x
# num_workers设置cpu工作线程,8个线程,一次加载8张图片,batch为32,那么cpu只需加载32/8=4次,这样可以提高效率。
loader = DataLoader(db, batch_size=32, shuffle=True, num_workers=8)
print(db.class_to_idx) #用于查看编码
for x, y in loader:
viz.images(denormalize(x), nrow=8, win='batch', opts=dict(title='batch'))
viz.text(str(y.numpy()), win='label', opts=dict(title='batch-y'))
time.sleep(20)
if __name__ == '__main__':
main()

二、创建分类器模型
对原来的ResNet18的模型进行稍微的修改:
文件名:resnet.py
import torch
from torch import nn
from torch.nn import functional as F
class ResBlk(nn.Module):
"""
resnet block
"""
def __init__(self, ch_in, ch_out, stride=1):
"""
:param ch_in:
:param ch_out:
"""
super(ResBlk, self).__init__()
self.conv1 = nn.Conv2d(ch_in, ch_out, kernel_size=3, stride=stride, padding=1)
self.bn1 = nn.BatchNorm2d(ch_out)
self.conv2 = nn.Conv2d(ch_out, ch_out, kernel_size=3, stride=1, padding=1)
self.bn2 = nn.BatchNorm2d(ch_out)
self.extra = nn.Sequential()
if ch_out != ch_in:
# [b, ch_in, h, w] => [b, ch_out, h, w]
self.extra = nn.Sequential(
nn.Conv2d(ch_in, ch_out, kernel_size=1, stride=stride),
nn.BatchNorm2d(ch_out)
)
def forward(self, x):
"""
:param x: [b, ch, h, w]
:return:
"""
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
# short cut.
# extra module: [b, ch_in, h, w] => [b, ch_out, h, w]
# element-wise add:
out = self.extra(x) + out
out = F.relu(out)
return out
class ResNet18(nn.Module):
def __init__(self, num_class):
super(ResNet18, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(3, 16, kernel_size=3, stride=3, padding=0),
nn.BatchNorm2d(16)
)
# followed 4 blocks
# [b, 16, h, w] => [b, 32, h ,w]
self.blk1 = ResBlk(16, 32, stride=3)
# [b, 32, h, w] => [b, 64, h, w]
self.blk2 = ResBlk(32, 64, stride=3)
# # [b, 64, h, w] => [b, 128, h, w]
self.blk3 = ResBlk(64, 128, stride=2)
# # [b, 128, h, w] => [b, 256, h, w]
self.blk4 = ResBlk(128, 256, stride=2)
# [b, 256, 7, 7]
self.outlayer = nn.Linear(256*3*3, num_class)
def forward(self, x):
"""
:param x:
:return:
"""
x = F.relu(self.conv1(x))
# [b, 64, h, w] => [b, 1024, h, w]
x = self.blk1(x)
x = self.blk2(x)
x = self.blk3(x)
x = self.blk4(x)
# print(x.shape)
x = x.view(x.size(0), -1)
x = self.outlayer(x)
return x
def main():
blk = ResBlk(64, 128)
tmp = torch.randn(2, 64, 224, 224)
out = blk(tmp)
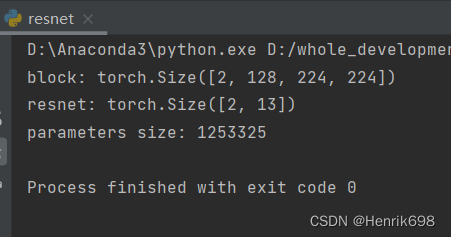
print('block:', out.shape)
model = ResNet18(13)
tmp = torch.randn(2, 3, 224, 224)
out = model(tmp)
print('resnet:', out.shape)
# p.numel()表示参数占据内存的大小
p = sum(map(lambda p:p.numel(), model.parameters()))
print('parameters size:', p)
if __name__ == '__main__':
main()
三、Train and Test
文件名:train_scratch.py
从同开始training的学习的。
import torch
from torch import optim,nn
import visdom
import torchvision
from torch.utils.data import DataLoader
from bottle import Bottle
from resnet import ResNet18
batchsz = 32
lr = 1e-3
epochs = 20
device = torch.device('cuda')
torch.manual_seed(1234) #这个是随机数种子,保证每次都能复现出来。
#这里是需要实例化Pokemon类
#这里之所以使用224,是因为是ResNet最适合的大小。
train_db = Bottle('dataset_water_bottle',224,'train')
val_db = Bottle('dataset_water_bottle',224,'val')
test_db = Bottle('dataset_water_bottle',224,'test')
#批量加载数据
#参数num_workers表示工作线程数:
train_loader = DataLoader(train_db
,batch_size=batchsz
,shuffle=True
,num_workers=6)
#一般情况下validation和test不需要shuffle,因为需要对全部图片做测试。
val_loader = DataLoader(val_db
, batch_size=batchsz
, num_workers=4)
test_loader = DataLoader(test_db
, batch_size=batchsz
, num_workers=4)
#需要把train的进度保存下来,需要用到visdom
viz = visdom.Visdom()
#建立一个测试函数:测试函数针对validation和test功能是一样的
def evalute(model,loader):
#用于统计总的预测正确的数量
correct = 0
#总的测试数量
total = len(loader.dataset)
for x,y in loader:
x,y = x.to(device),y.to(device)
with torch.no_grad():#test和validation是不需要梯度信息的
logits = model(x)
pred = logits.argmax(dim=1) #最大的值所在的位置
#总的预测正确的数量,累加操作
correct += torch.eq(pred,y).sum().float().item()
accuracy = correct/ total
return accuracy
def main():
#实例化模型
model = ResNet18(13).to(device)
#创建一个优化器Adam,这个优化器比较好
optimizer = optim.Adam(model.parameters(),lr=lr)
#Loss的计算方法:CrossEntropyLoss;
#这个Loss所接受的参数是logits,logits是不需要经过一个softmax的,只需要得到logits即可。
criteon = nn.CrossEntropyLoss()
#用于保存模型的训练状态
best_acc, best_epoch = 0,0
#step每次都是从0开始的,因此这里我们创建一个全局step
global_step = 0
#用visdom工具保存下accuracy和loss
#training和loss的曲线
#x=0,y=-1是初始状态
viz.line([0],[-1],win='loss',opts = dict(title='loss'))
# training和validation accuracy的曲线
viz.line([0],[-1],win='val_acc',opts = dict(title='val_acc'))
#training逻辑
for epoch in range(epochs):
for step,(x,y) in enumerate(train_loader):
#x:[b,3,224,224]; y:[b]
x,y = x.to(device), y.to(device) #x和y都转移到cuda上面
#执行forward函数
logits = model(x) #学出的预测结果
#在pytorch中crossEntropyLoss中,传入的真实值y不需要进行one-hot操作,不需要做one-hot编码,会在内部做one-hot。
#所以我们直接传入y就可以了。
loss = criteon(logits,y) #预测结果与真实值进行交叉熵计算
#前向传播和迭代过程
#优化器
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 用visdom工具保存下accuracy和loss
# 每一个step我都要记录下来
# validation和loss的曲线
# x=loss.item()loss是一个tensor,因此需要通过item转为具体数值,y=-1是初始状态
#参数update为append,表示添加到曲线的末尾。
viz.line([loss.item()], [global_step], win='loss', update='append')
global_step += 1
print('epoch:',epoch,',loss:',loss)
#这里我们每完成两个epoch就做一组validation
if epoch % 1 == 0:
#我们根据validation accuracy来选择要不要保存这个模型的训练状态。
val_acc = evalute(model , val_loader)
#如果当前accuracy大于best_acc,就保存当前的状态:
if val_acc>best_acc:
best_epoch = epoch
best_acc = val_acc
#保存当前模型的状态:
#参数一:模型状态值
#参数二:模型状态保存的文件名,文件名后缀随意
torch.save(model.state_dict(),'best.mdl')
# validation和 accuracy的曲线
# 这里val_acc是数值型,所以不需要转换。
viz.line([val_acc], [global_step], win='val_acc', update='append')
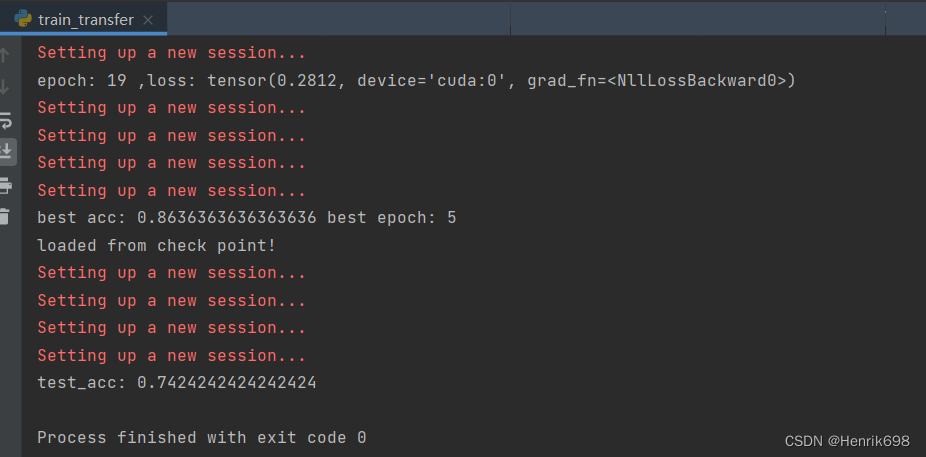
print('best acc:',best_acc,'best epoch:',best_epoch)
#从最好的状态加载模型:
model.load_state_dict(torch.load('best.mdl'))
print('loaded from check point!')
#上面加载了最好的模型状态,这里使用的模型也是最好的状态时的模型
test_acc = evalute(model, test_loader)
print('test_acc:',test_acc)
if __name__ == '__main__':
main()
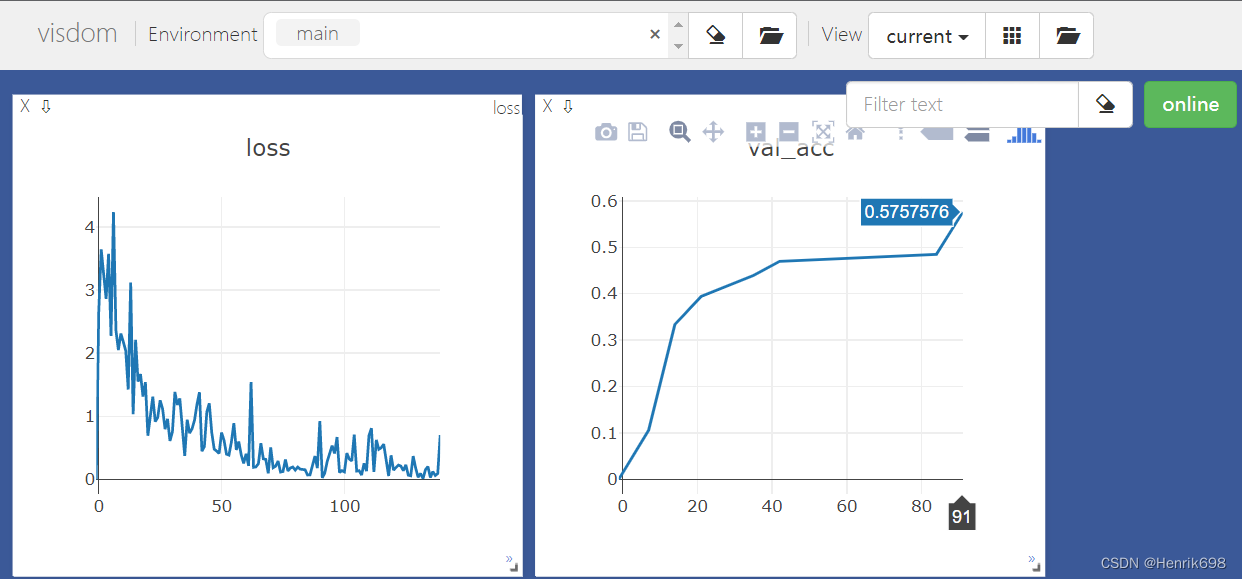
发现效果并不好:

四、Transfer learning迁移学习
文件名:train_transfer.py
这个不是从头开始学习的。是借助imagenet训练后resnet模型,取该模型的前17层对我们的模型进行训练。
import torch
from torch import optim,nn
import visdom
import torchvision
from torch.utils.data import DataLoader
from bottle import Bottle
# 这里不再使用我们之前自己创建的ResNet18
# from resnet import ResNet18
# 利用已有模型API可以直接加载training好的状态,对我们的数据进行training
from torchvision.models import resnet18
from utils import Flatten
batchsz = 32
lr = 1e-3
epochs = 20
device = torch.device('cuda')
torch.manual_seed(1234) #这个是随机数种子,保证每次都能复现出来。
#这里是需要实例化Pokemon类
#这里之所以使用224,是因为是ResNet最适合的大小。
train_db = Bottle('dataset_water_bottle',224,'train')
val_db = Bottle('dataset_water_bottle',224,'val')
test_db = Bottle('dataset_water_bottle',224,'test')
#批量加载数据
#参数num_workers表示工作线程数:
train_loader = DataLoader(train_db
,batch_size=batchsz
,shuffle=True
,num_workers=6)
#一般情况下validation和test不需要shuffle,因为需要对全部图片做测试。
val_loader = DataLoader(val_db
, batch_size=batchsz
, num_workers=4)
test_loader = DataLoader(test_db
, batch_size=batchsz
, num_workers=4)
#需要把train的进度保存下来,需要用到visdom
viz = visdom.Visdom()
#建立一个测试函数:测试函数针对validation和test功能是一样的
def evalute(model,loader):
#用于统计总的预测正确的数量
correct = 0
#总的测试数量
total = len(loader.dataset)
for x,y in loader:
x,y = x.to(device),y.to(device)
with torch.no_grad():#test和validation是不需要梯度信息的
logits = model(x)
pred = logits.argmax(dim=1) #最大的值所在的位置
#总的预测正确的数量,累加操作
correct += torch.eq(pred,y).sum().float().item()
accuracy = correct/ total
return accuracy
def main():
#实例化模型
# model = ResNet18(13).to(device)
#=========这里使用已经train好的模型==========
trained_model = resnet18(pretrained=True)
# trained_model.children()可以获得前17层
model = nn.Sequential(
*list(trained_model.children())[:-1], #这里输出的是torch.Size([b, 512, 1, 1])
Flatten(), #[b,512,1,1]=>[b,512]
nn.Linear(512,13)
).to(device)
# ========================================
# x = torch.randn(2,3,224,224)
# print(model(x).shape)
#创建一个优化器Adam,这个优化器比较好
optimizer = optim.Adam(model.parameters(),lr=lr)
#Loss的计算方法:CrossEntropyLoss;
#这个Loss所接受的参数是logits,logits是不需要经过一个softmax的,只需要得到logits即可。
criteon = nn.CrossEntropyLoss()
#用于保存模型的训练状态
best_acc, best_epoch = 0,0
#step每次都是从0开始的,因此这里我们创建一个全局step
global_step = 0
#用visdom工具保存下accuracy和loss
#training和loss的曲线
#x=0,y=-1是初始状态
viz.line([0],[-1],win='loss',opts = dict(title='loss'))
# training和validation accuracy的曲线
viz.line([0],[-1],win='val_acc',opts = dict(title='val_acc'))
#training逻辑
for epoch in range(epochs):
for step,(x,y) in enumerate(train_loader):
#x:[b,3,224,224]; y:[b]
x,y = x.to(device), y.to(device) #x和y都转移到cuda上面
#执行forward函数
logits = model(x) #学出的预测结果
#在pytorch中crossEntropyLoss中,传入的真实值y不需要进行one-hot操作,不需要做one-hot编码,会在内部做one-hot。
#所以我们直接传入y就可以了。
loss = criteon(logits,y) #预测结果与真实值进行交叉熵计算
#前向传播和迭代过程
#优化器
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 用visdom工具保存下accuracy和loss
# 每一个step我都要记录下来
# validation和loss的曲线
# x=loss.item()loss是一个tensor,因此需要通过item转为具体数值,y=-1是初始状态
#参数update为append,表示添加到曲线的末尾。
viz.line([loss.item()], [global_step], win='loss', update='append')
global_step += 1
print('epoch:',epoch,',loss:',loss)
#这里我们每完成两个epoch就做一组validation
if epoch % 1 == 0:
#我们根据validation accuracy来选择要不要保存这个模型的训练状态。
val_acc = evalute(model , val_loader)
#如果当前accuracy大于best_acc,就保存当前的状态:
if val_acc>best_acc:
best_epoch = epoch
best_acc = val_acc
#保存当前模型的状态:
#参数一:模型状态值
#参数二:模型状态保存的文件名,文件名后缀随意
torch.save(model.state_dict(),'best.mdl')
# validation和 accuracy的曲线
# 这里val_acc是数值型,所以不需要转换。
viz.line([val_acc], [global_step], win='val_acc', update='append')
print('best acc:',best_acc,'best epoch:',best_epoch)
#从最好的状态加载模型:
model.load_state_dict(torch.load('best.mdl'))
print('loaded from check point!')
#上面加载了最好的模型状态,这里使用的模型也是最好的状态时的模型
test_acc = evalute(model, test_loader)
print('test_acc:',test_acc)
if __name__ == '__main__':
main()
五、结合迁移学习方法,在ResNet基础上建立新的模型,Bilinear CNN model
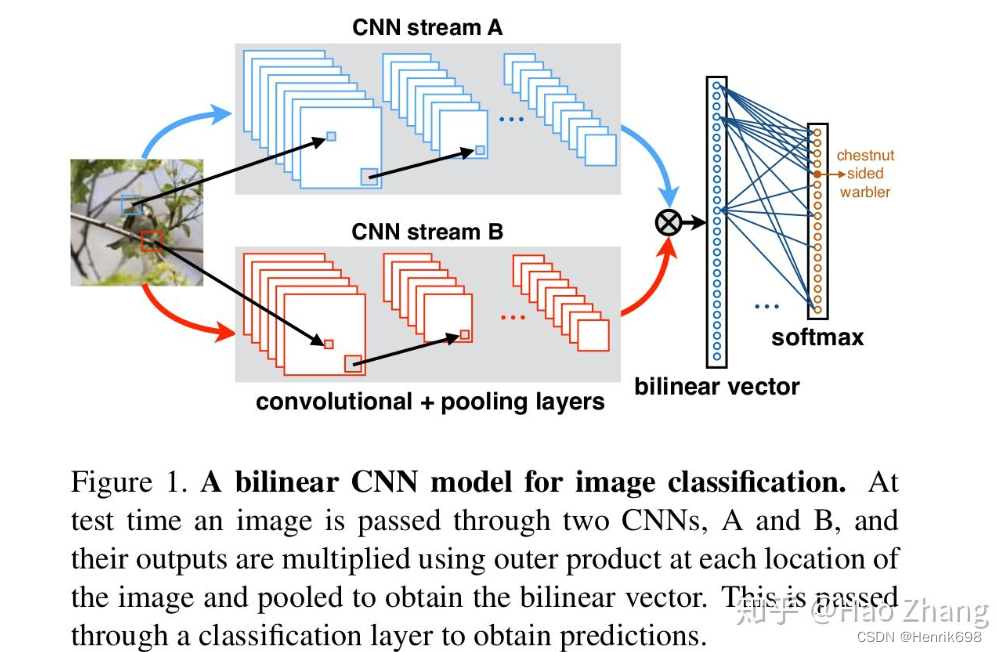
train_transfer_bilinear.py
import torch
from torch import optim,nn
import visdom
import torchvision
from torch.utils.data import DataLoader
from bottle import Bottle
# 这里不再使用我们之前自己创建的ResNet18
# from resnet import ResNet18
# 利用已有模型API可以直接加载training好的状态,对我们的数据进行training
# from torchvision.models import resnet18
from bilinear_CNN import Bilinear
from utils import Flatten
batchsz = 32
lr = 1e-3
epochs = 20
device = torch.device('cuda')
torch.manual_seed(1234) #这个是随机数种子,保证每次都能复现出来。
#这里是需要实例化Pokemon类
#这里之所以使用224,是因为是ResNet最适合的大小。
train_db = Bottle('dataset_water_bottle',224,'train')
val_db = Bottle('dataset_water_bottle',224,'val')
test_db = Bottle('dataset_water_bottle',224,'test')
#批量加载数据
#参数num_workers表示工作线程数:
train_loader = DataLoader(train_db
,batch_size=batchsz
,shuffle=True
,num_workers=6)
#一般情况下validation和test不需要shuffle,因为需要对全部图片做测试。
val_loader = DataLoader(val_db
, batch_size=batchsz
, num_workers=4)
test_loader = DataLoader(test_db
, batch_size=batchsz
, num_workers=4)
#需要把train的进度保存下来,需要用到visdom
viz = visdom.Visdom()
#建立一个测试函数:测试函数针对validation和test功能是一样的
def evalute(model,loader):
#用于统计总的预测正确的数量
correct = 0
#总的测试数量
total = len(loader.dataset)
for x,y in loader:
x,y = x.to(device),y.to(device)
with torch.no_grad():#test和validation是不需要梯度信息的
logits = model(x)
pred = logits.argmax(dim=1) #最大的值所在的位置
#总的预测正确的数量,累加操作
correct += torch.eq(pred,y).sum().float().item()
accuracy = correct/ total
return accuracy
def main():
#实例化模型
# model = ResNet18(13).to(device)
#=========这里使用已经train好的模型==========
# trained_model = resnet18(pretrained=True)
# # trained_model.children()可以获得前17层
# model = nn.Sequential(
# *list(trained_model.children())[:-1], #这里输出的是torch.Size([b, 512, 1, 1])
# Flatten(), #[b,512,1,1]=>[b,512]
# nn.Linear(512,13)
# ).to(device)
# ========================================
# 将迁移部分,写成一个新的类,在新的类中增加bilinear CNN的内容
model = Bilinear(13).to(device)
# x = torch.randn(2,3,224,224).to(device)
# out = model(x)
# print(out.shape)
#创建一个优化器Adam,这个优化器比较好
optimizer = optim.Adam(model.parameters(),lr=lr)
#Loss的计算方法:CrossEntropyLoss;
#这个Loss所接受的参数是logits,logits是不需要经过一个softmax的,只需要得到logits即可。
criteon = nn.CrossEntropyLoss()
#用于保存模型的训练状态
best_acc, best_epoch = 0,0
#step每次都是从0开始的,因此这里我们创建一个全局step
global_step = 0
#用visdom工具保存下accuracy和loss
#training和loss的曲线
#x=0,y=-1是初始状态
viz.line([0],[-1],win='loss',opts = dict(title='loss'))
# training和validation accuracy的曲线
viz.line([0],[-1],win='val_acc',opts = dict(title='val_acc'))
#training逻辑
for epoch in range(epochs):
for step,(x,y) in enumerate(train_loader):
#x:[b,3,224,224]; y:[b]
x,y = x.to(device), y.to(device) #x和y都转移到cuda上面
#执行forward函数
logits = model(x) #学出的预测结果
#在pytorch中crossEntropyLoss中,传入的真实值y不需要进行one-hot操作,不需要做one-hot编码,会在内部做one-hot。
#所以我们直接传入y就可以了。
loss = criteon(logits,y) #预测结果与真实值进行交叉熵计算
#前向传播和迭代过程
#优化器
optimizer.zero_grad()
loss.backward()
optimizer.step()
# 用visdom工具保存下accuracy和loss
# 每一个step我都要记录下来
# validation和loss的曲线
# x=loss.item()loss是一个tensor,因此需要通过item转为具体数值,y=-1是初始状态
#参数update为append,表示添加到曲线的末尾。
viz.line([loss.item()], [global_step], win='loss', update='append')
global_step += 1
print('epoch:',epoch,',loss:',loss)
#这里我们每完成两个epoch就做一组validation
if epoch % 1 == 0:
#我们根据validation accuracy来选择要不要保存这个模型的训练状态。
val_acc = evalute(model , val_loader)
#如果当前accuracy大于best_acc,就保存当前的状态:
if val_acc>best_acc:
best_epoch = epoch
best_acc = val_acc
#保存当前模型的状态:
#参数一:模型状态值
#参数二:模型状态保存的文件名,文件名后缀随意
torch.save(model.state_dict(),'best.mdl')
# validation和 accuracy的曲线
# 这里val_acc是数值型,所以不需要转换。
viz.line([val_acc], [global_step], win='val_acc', update='append')
print('best acc:',best_acc,'best epoch:',best_epoch)
#从最好的状态加载模型:
model.load_state_dict(torch.load('best.mdl'))
print('loaded from check point!')
#上面加载了最好的模型状态,这里使用的模型也是最好的状态时的模型
test_acc = evalute(model, test_loader)
print('test_acc:',test_acc)
if __name__ == '__main__':
main()
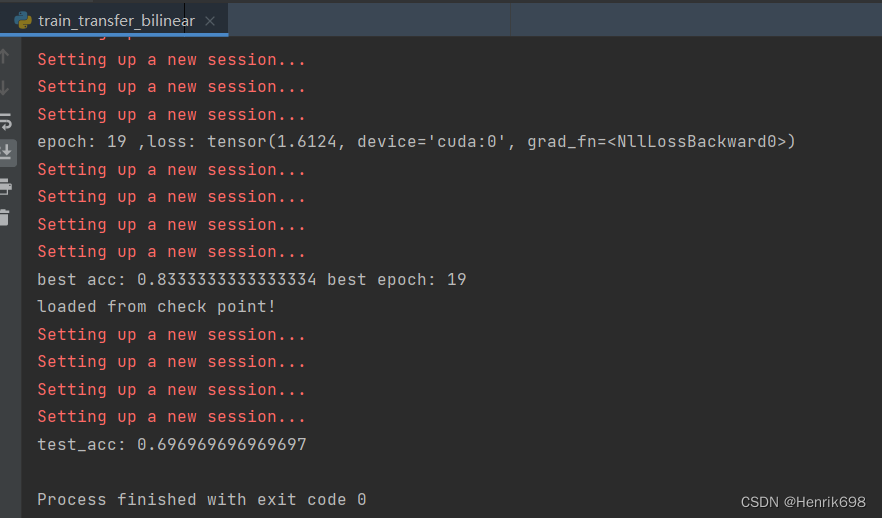
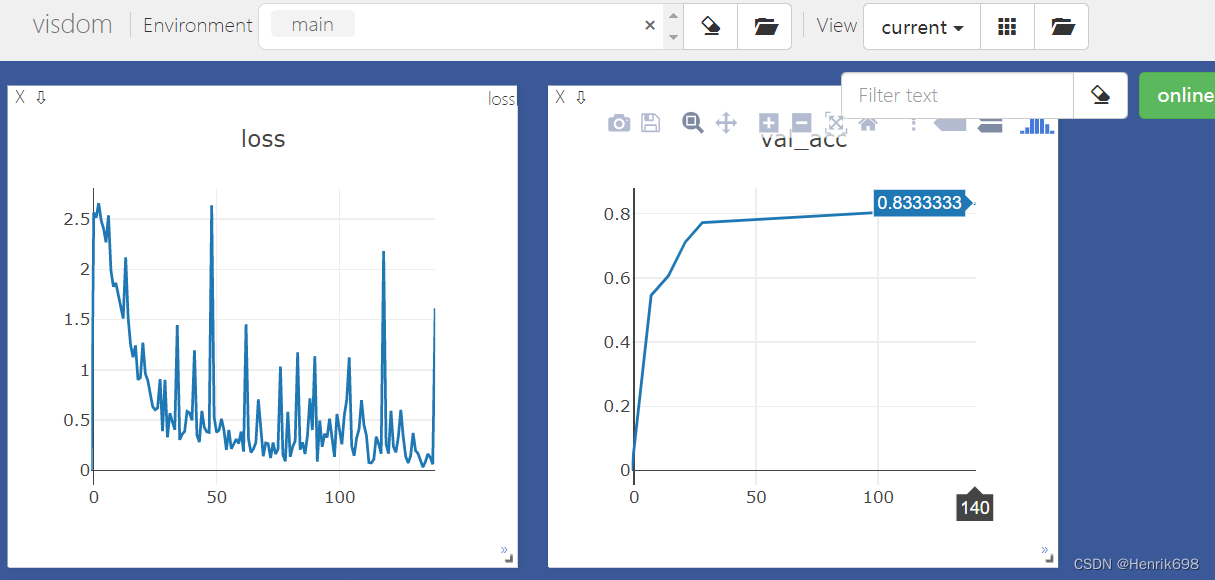
六、检查一下预测的结果,并显示出来
我们先检查一下train_transfer_bilinear.py,bilinear_cnn模型训练的结果预测情况:
check_train_result.py
from PIL import Image
import matplotlib.pyplot as plt
from torchvision.transforms import ToPILImage
from torchvision.models import resnet18
from torch import nn
from utils import Flatten
import torch
from bottle import Bottle
from torch.utils.data import DataLoader
import visdom
import time
import torchvision
from bilinear_CNN import Bilinear
from resnet import ResNet18
# 这里传入的参数x是normalize过后的
def denormalize(x_hat):
mean = [0.557, 0.517, 0.496]
std = [0.210, 0.216, 0.222]
# normalize的过程:
# x_hat = (x-mean)/std
# x = x_hat*std+mean 这个就是逆操作过程
# x = [c,h,w]
# mean = [3] => boardcasting后
# unsqueeze()函数起升维的作用,参数表示在哪个地方加一个维度
mean = torch.tensor(mean).unsqueeze(1).unsqueeze(1)
std = torch.tensor(std).unsqueeze(1).unsqueeze(1)
print('mean.shape,std.shape:', mean.shape, std.shape)
x = x_hat * std + mean
return x
def main():
batchsz = 32
device = torch.device('cuda')
viz = visdom.Visdom()
test_db = Bottle('dataset_water_bottle',224,'test')
test_loader = DataLoader(test_db
, batch_size=batchsz
, num_workers=4)
# 实例化模型
#第一个模型:
# model = ResNet18(13).to(device)
#第二个模型
# =========这里使用已经train好的模型==========
# trained_model = resnet18(pretrained=True)
# # trained_model.children()可以获得前17层
# model = nn.Sequential(
# *list(trained_model.children())[:-1], # 这里输出的是torch.Size([b, 512, 1, 1])
# Flatten(), # [b,512,1,1]=>[b,512]
# nn.Linear(512, 13)
# ).to(device)
# ========================================
# 第三个模型
# 将迁移部分,写成一个新的类,在新的类中增加bilinear CNN的内容
model = Bilinear(13).to(device)
#从最好的状态加载模型:
model.load_state_dict(torch.load('best.mdl'))
print('loaded from check point!')
# viz.image(test_db.denormalize(x), win='sample_x', opts=dict(title="sample_x"))
for x, y in test_loader:
viz.images(test_db.denormalize(x), nrow=8, win='batch', opts=dict(title='batch'))
viz.text(str(y.numpy()), win='label', opts=dict(title='batch-y'))
x, y = x.to(device), y.to(device)
with torch.no_grad():#test和validation是不需要梯度信息的
logits = model(x)
pred = logits.argmax(dim=1) #最大的值所在的位置
viz.text(str(pred.data.cpu().numpy()),win='pred',opts=dict(title='batch-pred'))
time.sleep(30)
if __name__ == '__main__':
main()
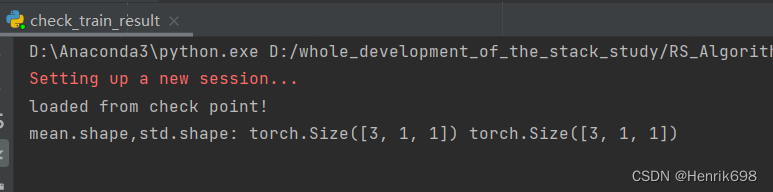
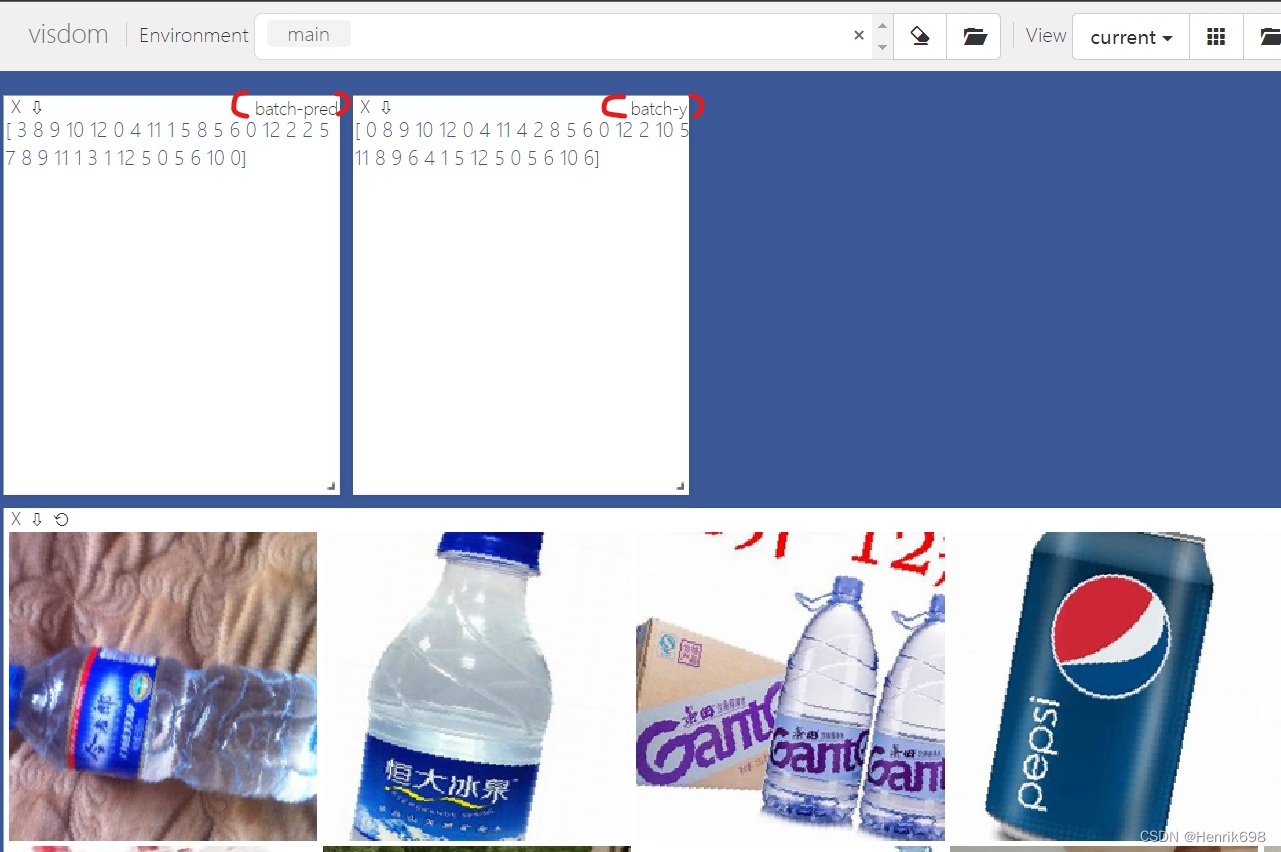
发现效果一般,预测并不是很好。
这里我们选择模型训练结果最好的train_transfer.py迁移学习出来的模型结果,来进行一个模型预测检查。
from PIL import Image
import matplotlib.pyplot as plt
from torchvision.transforms import ToPILImage
from torchvision.models import resnet18
from torch import nn
from utils import Flatten
import torch
from bottle import Bottle
from torch.utils.data import DataLoader
import visdom
import time
import torchvision
from bilinear_CNN import Bilinear
from resnet import ResNet18
# 这里传入的参数x是normalize过后的
def denormalize(x_hat):
mean = [0.557, 0.517, 0.496]
std = [0.210, 0.216, 0.222]
# normalize的过程:
# x_hat = (x-mean)/std
# x = x_hat*std+mean 这个就是逆操作过程
# x = [c,h,w]
# mean = [3] => boardcasting后
# unsqueeze()函数起升维的作用,参数表示在哪个地方加一个维度
mean = torch.tensor(mean).unsqueeze(1).unsqueeze(1)
std = torch.tensor(std).unsqueeze(1).unsqueeze(1)
print('mean.shape,std.shape:', mean.shape, std.shape)
x = x_hat * std + mean
return x
def main():
batchsz = 32
device = torch.device('cuda')
viz = visdom.Visdom()
test_db = Bottle('dataset_water_bottle',224,'test')
test_loader = DataLoader(test_db
, batch_size=batchsz
, num_workers=4)
# 实例化模型
#第一个模型:
# model = ResNet18(13).to(device)
#第二个模型
# =========这里使用已经train好的模型==========
trained_model = resnet18(pretrained=True)
# trained_model.children()可以获得前17层
model = nn.Sequential(
*list(trained_model.children())[:-1], # 这里输出的是torch.Size([b, 512, 1, 1])
Flatten(), # [b,512,1,1]=>[b,512]
nn.Linear(512, 13)
).to(device)
# ========================================
# 第三个模型
# 将迁移部分,写成一个新的类,在新的类中增加bilinear CNN的内容
# model = Bilinear(13).to(device)
#从最好的状态加载模型:
model.load_state_dict(torch.load('best.mdl'))
print('loaded from check point!')
# viz.image(test_db.denormalize(x), win='sample_x', opts=dict(title="sample_x"))
for x, y in test_loader:
viz.images(test_db.denormalize(x), nrow=8, win='batch', opts=dict(title='batch'))
viz.text(str(y.numpy()), win='label', opts=dict(title='batch-y'))
x, y = x.to(device), y.to(device)
with torch.no_grad():#test和validation是不需要梯度信息的
logits = model(x)
pred = logits.argmax(dim=1) #最大的值所在的位置
viz.text(str(pred.data.cpu().numpy()),win='pred',opts=dict(title='batch-pred'))
time.sleep(20)
if __name__ == '__main__':
main()
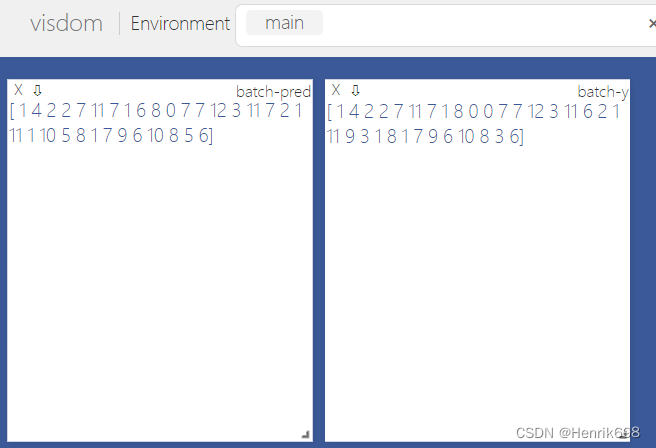
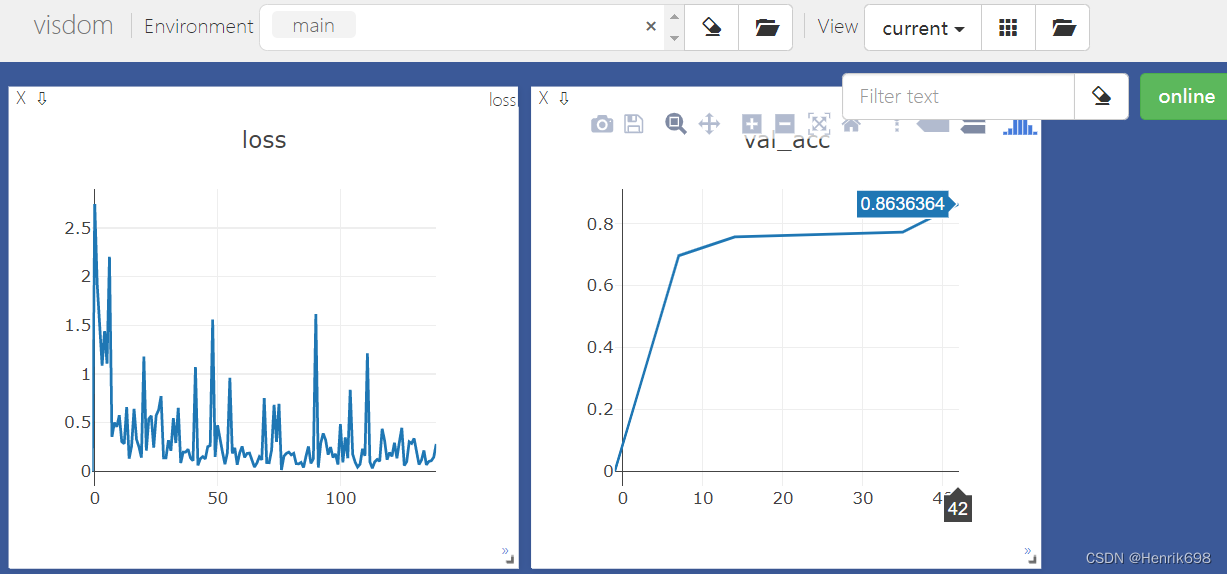
这个预测还是比上面模型预测的要好。
以上所有内容和数据集下载地址:https://download.csdn.net/download/m0_37755995/86002377



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











