







什么是T检验?
T检验是假设检验的一种,又叫student t检验(Student’s t test),主要用于样本含量较小(例如n<30),总体标准差σ未知的正态分布资料。
T检验用于检验两个总体的均值差异是否显著。
一个例子
例1:
“超级引擎”工厂是一家专门生产汽车引擎的工厂,根据政府发布的新排放要求,引擎排放平均值应低于20ppm,如何证明生产的引擎是否达标呢?(排放量的均值小于20ppm)
思路1
一个直接的想法就是,把这个工厂所有的引擎都测试一下,然后求一下排放平均值就好了。比如工厂生产了10个引擎,排放水平如下:
15.6 16.2 22.5 20.5 16.4
19.4 16.6 17.9 12.7 13.9
排放平均值为
(15.6+16.2+22.5+20.5+16.4+19.4+16.6+17.9+12.7+13.9)/10=17.17
小于政府规定的20ppm,合格!
这也太简单了!
然而,随着“超级引擎”工厂规模逐渐增大,每天可以生产出10万个引擎,如果把每个引擎都测试一遍,估计要累死人了……
有没有更好的方法?
思路2
由于引擎数量太多,把所有引擎测试一遍太麻烦了,“智多星”有一个好想法:
可不可以采用“反证法”?先假设所有引擎排放量的均值为
μ
,然后随机抽取10个引擎,看看这10个引擎的排放量均值与假设是否相符,如果相符,则认为假设是正确的,反之认为假设是错误的。这样,就可以通过一小部分数据推测数据的总体,真是太棒了!
具体怎么操作呢?
先建立两个假设,分别为:
H0:μ⩾20
(原假设)
H1:μ<20
(备择假设)
【
μ
代表总体(所有引擎的排放量)均值】
在原假设成立的基础上,求出”取得样本均值或者更极端的均值”的概率,如果概率很大,就倾向于认为原假设 H0 是正确的,如果概率很小,就倾向于认为原假设 H0 是错误的,从而接受备择假设 H1 。
那么如何求这个概率p呢?
这就需要引入一个概念——统计量
简单的讲,统计量就类似于用样本已知的信息(如样本均值,样本标准差)构建的一个“标准得分”,这个“标准得分”可以让我们求出概率p
由于样本服从正态分布,且样本数量较小(10),所以这里要用到的统计量为t统计量,公式如下:
x¯:样本均值
μ:总体均值
S:样本标准差
n:样本容量
该 t 统计量服从自由度为
让我们试验一下!
现在抽取出10台引擎供测试使用,每一台的排放水平如下:
15.6 16.2 22.5 20.5 16.4
19.4 16.6 17.9 12.7 13.9
样本均值
样本方差
样本标准差
我们把原假设
μ⩾20
拆分,先考虑
μ=20
的情况
将数值带入t统计量公式中,可以得出
t=17.17−202.98/10√=−3.00
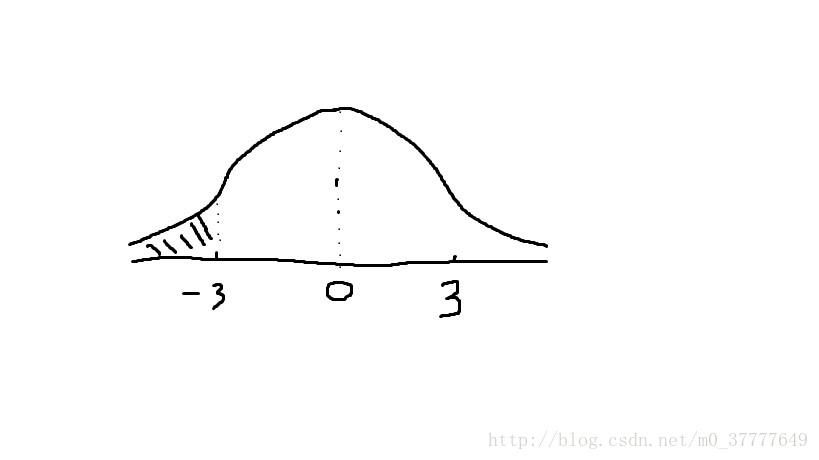
由于t统计量服从自由度为9的t分布,我们可以求出t统计量小于-3.00的概率,即下图阴影部分面积
p值
通过查询t分位数表(见附录),我们可知,当自由度为9时,t统计量小于-2.821的概率为1%,而我们求得的t统计量为-3.00,所以t统计量小于-3.00的概率比1%还要小(因为-3.00在-2.81的左边,所以阴影面积更小)。
这个概率值通常被称作“p值”,即在原假设成立的前提下,取得“像样本这样,或比样本更加极端的数据”的概率。
到这里,我们可以总结出如下结论:
在
μ=20
成立(所有引擎排放均值为20ppm)的前提下,从所有引擎中随机选出10个引擎,这10个引擎排放均值小于17.17的概率小于1%
再考虑
μ>20
的情况:
由t统计量的公式
t=x¯−μS/n√
可以看出,当
μ
增大,其他变量均保持不变时,
t
统计量的值会变小,因此求概率时阴影面积也会变小,总结来看,我们得出如下结论:
在
由于1%的概率很小,所以我们更倾向于认为,原假设 H0:μ⩾20 是错误的,从而接受备择假设 H1 。
综上,我们认为,所有引擎的排放量均值小于20ppm,工厂生产的引擎符合标准。
第一类错误与第二类错误
在例1中,我们认为1%的概率很小,所以更倾向于认为原假设是错误的,从而接受了备择假设。但这样的判断是准确的吗?为了探讨这个问题,我们考虑以下四种情况:
| 事实(右)/判断(下) | H0 成立 | H1 成立 |
|---|---|---|
| H0 成立 | 判断正确 | 第二类错误 |
| H1 成立 | 第一类错误 | 判断正确 |
即:
如果事实为
H0
成立,而我们做出了接受备择假设
H1
的判断,则犯了第一类错误——拒真
如果事实为
H1
成立,而我们做出了接受原假设
H0
的判断,则犯了第二类错误——取伪
所以用另外一种角度来看上面的例子:
在
μ⩾20
成立的前提下,从所有引擎中随机选出10个引擎,这10个引擎排放均值小于17.17的概率小于1%,当我们据此做出“拒绝原假设
H0
,接受备择假设
H1
”的结论时,有小于1%的概率犯第一类错误,因为
H0
仍有小于1%的概率是成立的,虽然这个概率很小。
α 值
所以利用t检验做出的结论并不是百分之百正确的,仍有很小的几率会犯错误。对于上面的例子,有些人会认为1%的概率已经很小了,可以拒绝原假设,还有些人会认为1%的概率虽然很小,但不足以拒绝原假设。为了解决这个问题,统计学家们提出了一个阈值,如果犯第一类错误的概率小于这个阈值,就认为可以拒绝原假设,否则认为不足以拒绝原假设。这个阈值就叫 α 。
另一种流程
现在,让我们尝试引入 α ,用另一种流程解决例1:
建立原假设和备择假设
H0:μ⩾20
H1:μ<20确定α
令 α=0.05 ( α 的值通常为0.01,0.05,0.1,视具体问题而定)确定用于决策的拒绝域
在确定了 α 和t统计量自由度(根据样本容量可以求出,在这个例子中,自由度为[样本容量-1])的前提下,我们可以通过查询t分位数表,找出“拒绝域”,如果t统计量落入拒绝域内,就拒绝原假设,否则接收原假设。
根据t分位数表,我们查出当自由度为9时, t⩽−1.833 的概率为0.05,因此,拒绝域为{ t |t⩽−1.833 }查看样本结果是否位于拒绝域内
将样本均值和样本标准差带入t统计量计算公式,得出t=-3.00,落入拒绝域内做出决策
拒绝原假设 H0 ,接受备择假设 H1 ,认为样本均值与总体均值差异显著,认为所有的引擎排放量平均值小于20ppm
以上就是t检验的标准化流程。
假设形式与拒绝域的推广
在例1中,我们的假设形式为:
H0:μ⩾x0
H1:μ<x0
(
x0
为某一常数)
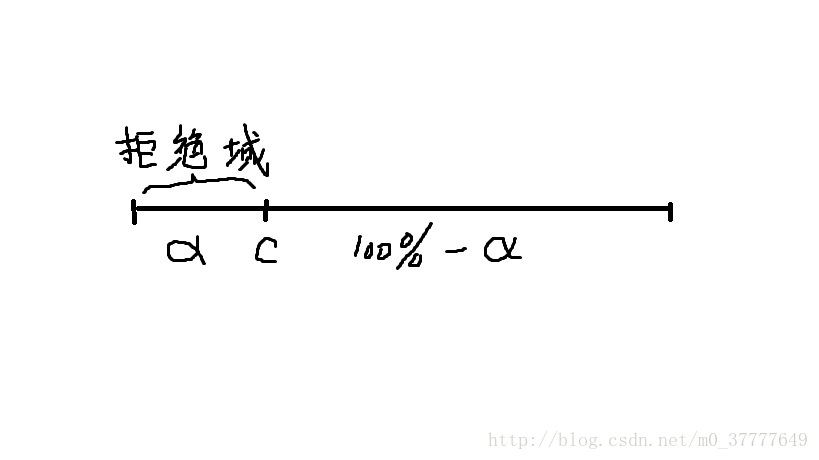
拒绝域的形式为{
t|t⩽c
} (
c
为某一常数),如果用数轴表示,形如:
假设的形式与拒绝域的形式有没有什么联系呢?
为了进一步讨论,我们将假设的形式做如下分类:
类别1:备择假设中包含
1.1
H0:μ=x0
vs
H1:μ≠x0
类别2:备择假设中包含
>或<
2.1
H0:μ=x0
vs
H1:μ>x0
2.2
H0:μ=x0
vs
H1:μ<x0
2.3
H0:μ⩾x0
vs
H1:μ<x0
2.4
H0:μ⩽x0
vs
H1:μ>x0
注意:原假设和备择假设不一定将数轴全部覆盖,在实际生活中,形如2.1和2.2的问题是存在的
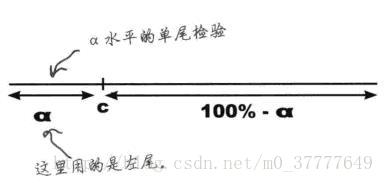
类别1称为双尾检验,由于备择假设中包含
≠
,拒绝域分布在两侧

类别2称为单尾检验
备择假设中包含
>
的情形,拒绝域在数轴右侧

备择假设中包含
t检验的分类
t检验分为单总体t检验和双总体t检验
单总体t检验
检验一个样本平均数与一个已知的总体平均数差异是否显著。
适用条件:
1.总体服从正态分布
2.样本量小于30(当样本量大于30时,用Z统计量)
统计量:
x¯ ——样本均值
μ ——总体均值
S ——样本标准差
例1就是单样本t检验的例子。
双总体t检验
检验两个样本各自所代表的总体的均值差异是否显著,包括独立样本t检验和配对样本t检验
独立样本t检验
检验两个独立样本所代表的总体均值差异是否显著。
适用条件:
1.两样本均来自于正态总体
2.两样本相互独立
3.满足方差齐性(两总体方差相等)
统计量:
其中
x¯ ——第一个样本均值
y¯ ——第二个样本均值
m ——第一个样本容量
S21 ——第一个样本方差
S22 ——第二个样本方差
配对样本t检验
检验两个配对样本所代表的总体均值差异是否显著。
配对样本主要包含以下两种情形:
1.同源配对,也就是同质的对象分别接受两种不同的处理。例如:为了验证某种记忆方法对改善儿童对词汇的记忆是否有效,先随机抽取40名学生,再随机分为两组。一组使用该训练方法,一组不使用,三个月后对这两组的学生进行词汇测验,得到数据。问该训练方法是否对提高词汇记忆量有效?
2.自身配对
2.1某组同质对象接受两种不同的处理。例如:某公司推广了一种新的促销方式,实施前和实施后分别统计了员工的业务量,得到数据。试问这种促销方式是否有效?
适用条件:
每对数据的差值必须服从正态分布
统计量:
两配对样本对应元素做差后形成的新样本
xd¯ ——新样本均值
Sd ——新样本标准差
n ——新样本容量
附录
什么是t分布
t分布的形状与正态分布很相似,都是中间高,两端低的“钟形”,当t分布的自由度为无穷大时,其形状与正态分布相同,随着自由度的减小,t分布的中间变低,两端变高,与正态分布相比更加“平坦”。
为什么t统计量服从t分布
单样本t检验
设
均值
x¯=1n∑ni=1xi
方差
S2=1n−1∑ni=1(xi−x¯)2
且有:
1.
x¯
与
S2
相互独立
2.
x¯∼N(μ,σ2μ)
3.
(n−1)S2σ2∼χ2(n−1)
所以:
x¯−μσ/n√∼N(0,1)
(n−1)S2σ2∼χ2(n−1)
所以:
x¯−μσ/n√/(n−1)S2σ2/(n−1)−−−−−−−−−−−−√=x¯−μS/n√∼t(n−1)
独立样本t检验
x1,x2,⋯,xn
来自正态分布总体
N(μ1,σ21)
y1,y2,⋯,yn
来自正态分布总体
N(μ2,σ22)
且两样本是独立的
当
σ1
与
σ2
已知:
x¯−y¯∼N(μ1−μ2,σ21m+σ22n)
当 σ1 与 σ2 未知时:
σ21=σ22=σ2 时, x¯−y¯∼N(μ1−μ2,(1m+1n)σ2)
因为:
1σ2∑mi=1(xi−x¯)2∼χ2(m−1)
1σ2∑ni=1(yi−y¯)2∼χ2(n−1)
所以:
1σ2∑mi=1(xi−x¯)2+1σ2∑ni=1(yi−y¯)2∼χ2(m+n−2)
因卡方分布 χ2 具有可加性
令 S2w=1m+n−2[∑mi=1(xi−x¯)2+∑ni=1(yi−y¯)2]
当假设两总体均值相等,即 μ1=μ2 时:
其中:
配对样本t检验
可将两配对样本对应元素做差,得到新样本,这个新样本可视作单样本,与单样本t检验统计量证明方法相同。
p值参照表
| p值 | 碰巧的概率 | 对原假设 | 统计意义 |
|---|---|---|---|
| P>0.05 | 碰巧出现的可能性不大于5% | 不能否定原假设 | 两组差别无显著意义 |
| P<0.05 | 碰巧出现的可能性小于5% | 可以否定原假设 | 两组差别有显著意义 |
| p<0.01 | 碰巧出现的可能性小于1% | 可以否定原假设 | 两组差别有非常显著意义 |
t分位数表
| 单侧 | 75% | 80% | 85% | 90% | 95% | 97.50% | 99% | 99.50% | 99.75% | 99.90% | 99.95% |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 双侧 | 50% | 60% | 70% | 80% | 90% | 95% | 98% | 99% | 99.50% | 99.80% | 99.90% |
| 1 | 1 | 1.376 | 1.963 | 3.078 | 6.314 | 12.71 | 31.82 | 63.66 | 127.3 | 318.3 | 636.6 |
| 2 | 0.816 | 1.061 | 1.386 | 1.886 | 2.92 | 4.303 | 6.965 | 9.925 | 14.09 | 22.33 | 31.6 |
| 3 | 0.765 | 0.978 | 1.25 | 1.638 | 2.353 | 3.182 | 4.541 | 5.841 | 7.453 | 10.21 | 12.92 |
| 4 | 0.741 | 0.941 | 1.19 | 1.533 | 2.132 | 2.776 | 3.747 | 4.604 | 5.598 | 7.173 | 8.61 |
| 5 | 0.727 | 0.92 | 1.156 | 1.476 | 2.015 | 2.571 | 3.365 | 4.032 | 4.773 | 5.893 | 6.869 |
| 6 | 0.718 | 0.906 | 1.134 | 1.44 | 1.943 | 2.447 | 3.143 | 3.707 | 4.317 | 5.208 | 5.959 |
| 7 | 0.711 | 0.896 | 1.119 | 1.415 | 1.895 | 2.365 | 2.998 | 3.499 | 4.029 | 4.785 | 5.408 |
| 8 | 0.706 | 0.889 | 1.108 | 1.397 | 1.86 | 2.306 | 2.896 | 3.355 | 3.833 | 4.501 | 5.041 |
| 9 | 0.703 | 0.883 | 1.1 | 1.383 | 1.833 | 2.262 | 2.821 | 3.25 | 3.69 | 4.297 | 4.781 |
| 10 | 0.7 | 0.879 | 1.093 | 1.372 | 1.812 | 2.228 | 2.764 | 3.169 | 3.581 | 4.144 | 4.587 |
| 11 | 0.697 | 0.876 | 1.088 | 1.363 | 1.796 | 2.201 | 2.718 | 3.106 | 3.497 | 4.025 | 4.437 |
| 12 | 0.695 | 0.873 | 1.083 | 1.356 | 1.782 | 2.179 | 2.681 | 3.055 | 3.428 | 3.93 | 4.318 |
| 13 | 0.694 | 0.87 | 1.079 | 1.35 | 1.771 | 2.16 | 2.65 | 3.012 | 3.372 | 3.852 | 4.221 |
| 14 | 0.692 | 0.868 | 1.076 | 1.345 | 1.761 | 2.145 | 2.624 | 2.977 | 3.326 | 3.787 | 4.14 |
| 15 | 0.691 | 0.866 | 1.074 | 1.341 | 1.753 | 2.131 | 2.602 | 2.947 | 3.286 | 3.733 | 4.073 |
| 16 | 0.69 | 0.865 | 1.071 | 1.337 | 1.746 | 2.12 | 2.583 | 2.921 | 3.252 | 3.686 | 4.015 |
| 17 | 0.689 | 0.863 | 1.069 | 1.333 | 1.74 | 2.11 | 2.567 | 2.898 | 3.222 | 3.646 | 3.965 |
| 18 | 0.688 | 0.862 | 1.067 | 1.33 | 1.734 | 2.101 | 2.552 | 2.878 | 3.197 | 3.61 | 3.922 |
| 19 | 0.688 | 0.861 | 1.066 | 1.328 | 1.729 | 2.093 | 2.539 | 2.861 | 3.174 | 3.579 | 3.883 |
| 20 | 0.687 | 0.86 | 1.064 | 1.325 | 1.725 | 2.086 | 2.528 | 2.845 | 3.153 | 3.552 | 3.85 |
| 21 | 0.686 | 0.859 | 1.063 | 1.323 | 1.721 | 2.08 | 2.518 | 2.831 | 3.135 | 3.527 | 3.819 |
| 22 | 0.686 | 0.858 | 1.061 | 1.321 | 1.717 | 2.074 | 2.508 | 2.819 | 3.119 | 3.505 | 3.792 |
| 23 | 0.685 | 0.858 | 1.06 | 1.319 | 1.714 | 2.069 | 2.5 | 2.807 | 3.104 | 3.485 | 3.767 |
| 24 | 0.685 | 0.857 | 1.059 | 1.318 | 1.711 | 2.064 | 2.492 | 2.797 | 3.091 | 3.467 | 3.745 |
| 25 | 0.684 | 0.856 | 1.058 | 1.316 | 1.708 | 2.06 | 2.485 | 2.787 | 3.078 | 3.45 | 3.725 |
| 26 | 0.684 | 0.856 | 1.058 | 1.315 | 1.706 | 2.056 | 2.479 | 2.779 | 3.067 | 3.435 | 3.707 |
| 27 | 0.684 | 0.855 | 1.057 | 1.314 | 1.703 | 2.052 | 2.473 | 2.771 | 3.057 | 3.421 | 3.69 |
| 28 | 0.683 | 0.855 | 1.056 | 1.313 | 1.701 | 2.048 | 2.467 | 2.763 | 3.047 | 3.408 | 3.674 |
| 29 | 0.683 | 0.854 | 1.055 | 1.311 | 1.699 | 2.045 | 2.462 | 2.756 | 3.038 | 3.396 | 3.659 |
| 30 | 0.683 | 0.854 | 1.055 | 1.31 | 1.697 | 2.042 | 2.457 | 2.75 | 3.03 | 3.385 | 3.646 |
| 40 | 0.681 | 0.851 | 1.05 | 1.303 | 1.684 | 2.021 | 2.423 | 2.704 | 2.971 | 3.307 | 3.551 |
| 50 | 0.679 | 0.849 | 1.047 | 1.299 | 1.676 | 2.009 | 2.403 | 2.678 | 2.937 | 3.261 | 3.496 |
| 60 | 0.679 | 0.848 | 1.045 | 1.296 | 1.671 | 2 | 2.39 | 2.66 | 2.915 | 3.232 | 3.46 |
| 80 | 0.678 | 0.846 | 1.043 | 1.292 | 1.664 | 1.99 | 2.374 | 2.639 | 2.887 | 3.195 | 3.416 |
| 100 | 0.677 | 0.845 | 1.042 | 1.29 | 1.66 | 1.984 | 2.364 | 2.626 | 2.871 | 3.174 | 3.39 |
| 120 | 0.677 | 0.845 | 1.041 | 1.289 | 1.658 | 1.98 | 2.358 | 2.617 | 2.86 | 3.16 | 3.373 |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









