






目录
前言
t检验,亦称student t检验(Student's t test),主要用于样本含量较小(例如n < 30),总体标准差σ未知的正态分布。t检验是用t分布理论来推论差异发生的概率,从而比较两个平均数的差异是否显著。它与f检验、卡方检验并列。t检验是戈斯特为了观测酿酒质量而发明的,并于1908年在Biometrika上公布。
几个高频面试题目
和正态分布的区别
在概率论和统计学中,t-分布(t-distribution)用于根据小样本来估计呈正态分布且方差未知的总体的均值。如果总体方差已知或者在样本数量足够多时,则应该用正态分布来估计总体均值。 [1]
t分布曲线形态与n(确切地说与自由度df)大小有关。与标准正态分布曲线相比,自由度df越小,t分布曲线愈平坦,曲线中间愈低,曲线双侧尾部翘得愈高;自由度df愈大,t分布曲线愈接近正态分布曲线,当自由度df=∞时,t分布曲线为标准正态分布曲线。
算法原理
什么是t检验
t检验的前提是要求样本服从正态分布或近似正态分布,不然可以利用一些变换(取对数、开根号、倒数等等)试图将其转化为服从正态分布是数据,如若还是不满足正态分布,只能利用非参数检验方法。不过当样本量大于30的时候,可以认为数据近似正态分布。
t检验最常见的四个用途:
- 单样本均值检验(One-sample t-test)
用于检验 总体方差未知、正态数据或近似正态的 单样本的均值 是否与 已知的总体均值相等 - 两独立样本均值检验(Independent two-sample t-test)
用于检验 两对独立的 正态数据或近似正态的 样本的均值 是否相等,这里可根据总体方差是否相等分类讨论 - 配对样本均值检验(Dependent t-test for paired samples)
用于检验 一对配对样本的均值的差 是否等于某一个值 - 回归系数的显著性检验(t-test for regression coefficient significance)
用于检验 回归模型的解释变量对被解释变量是否有显著影响
t 分布的发现使得小样本统计推断成为可能,并且以 t 分布为基础的检验称为t 检验。在医学统计学中,t 检验是应用较多的一类假设检验方法。对于计量资料的假设检验中, t检验是最为简单、常用的方法。
应用条件
-
随机样本。
-
来自正态分布总体。
-
均数比较时,要求两总体方差相等 (即方差齐性)。
适用情况:
2.1 关于样本情况
t检验,适合样本数里<30 或大都可以
但是Z只适应样本数量比较大的时候
2.2 适合检查的情况
2.2.1 单样本均值检验(One-sample t-test)
用于检验 总体方差未知、正态数据或近似正态的 单样本的均值 是否与 已知的总体均值相等
2.2.2 两独立样本均值检验(Independent two-sample t-test)
用于检验 两对独立的 正态数据或近似正态的 样本的均值 是否相等,这里可根据总体方差是否相等分类讨论
2.2.3 配对样本均值检验(Dependent t-test for paired samples)
用于检验 一对配对样本的均值的差 是否等于某一个值
2.2.4 回归系数的显著性检验(t-test for regression coefficient significance)
用于检验 回归模型的解释变量对被解释变量是否有显著影响
分类
①单样本t检验
单样本资料的t检验,实际上是推断该样本来自的总体均数与已知的某一总体均数μ0(常为理论值或标准值)有无差别。零假设为H0:μ = μ0 。而对立假设要视问题的背景而定:双侧的对立假设为H1:μ ≠ μ0﹔单侧的对立假设可以是H1 : μ > μ0或H1:μ < μ0。t检验的统计量计算如下图所示,服从自由度为v=n-1的t分布。
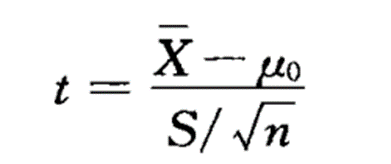
因此,可以根据t值来计算相应的P值,进行统计推断的。事先规定一个“小”的概率α作为检验水准,如果P值小于α,就拒绝零假设,如P值不小于α,则不拒绝零假设.
②配对样本t检验
配对设计 (paired design)是一种比较特殊的设计方式,能够很好地控制非实验因素对结果的影响,有自身配对和非自身配对之分。在医学科学研究中的配对设计主要适用于以下情况:第一,异体配对设计,包括同源配对设计和条件相近者配对设计(两同质受试对象配成对子分别接受两种不同的处理)。第二,自身配对设计(同一受试对象分别接受两种不同处理)。
配对设计资料的分析着眼于每一对中两个观察值之差,这些差值构成一组资料,用检验推断差值的总体均数是否为“0”。检验假设为:
H0:μd = 0,即差数的总体均数为0
H1:μd ≠ 0,即差数的总体均数不为 0
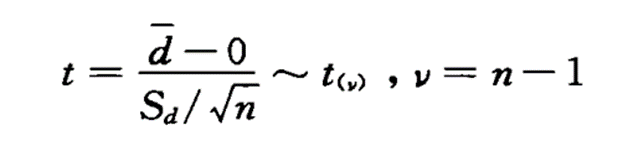
其中Sd为差值的样本标准差,n是对子数。同样,给定一个小概率α作为检验水准,如果与t值相应的 P 值小于给定的α ,拒绝 H0,否则,不拒绝 H0。
③两独立样本配对t检验
两样本t检验又称成组t检验,或两独立样本t检验,医学研究中常见用于完全随机设计两样本均数的比较,即将受试对象完全随机分配到两个不同处理组,研究者关心的是两样本均数所代表的两总体均数是否不等。此外,在观察性研究中,独立从两个总体中进行完全随机抽样,获得的两样本均数的比较,也可采用两样本t检验。此检验基于t分布,必须假定两个总体服从正态分布,根据是否符合方差齐性,分为以下两个情况:
-
两样本所属总体方差相等,即具有方差齐性。
检验假设为:
H0:μ1 = μ2,即两样本所属的两个总体均数相等。
H1:μ1 ≠ μ2,即两样所属的两个总体均数不相等。
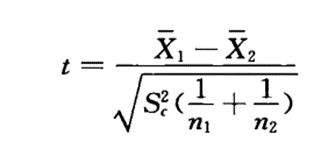
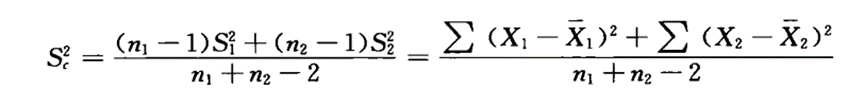
-
两样本所属总体方差不相等。
进行两小样本均数比较,若总体服从正态分布,但两总体方差不等,可采用数据变换(如两样本几何均数的t检验,就是将原始数据取对数后进行检验)或近似t检验--t'检验或秩转换的非参数检验。近似t检验有以下三种方法可供选择·Cochran & Cox法、Satterthwaite 法和 Welch 法。其中第一种和第二种方法较为常用。
检验假设和上面情况相同:
H0:μ1 = μ2,即两样本所属的两个总体均数相等。
H1:μ1 ≠ μ2,即两样所属的两个总体均数不相等。
Satterthwaite近似法的检验统计量如下图所示:
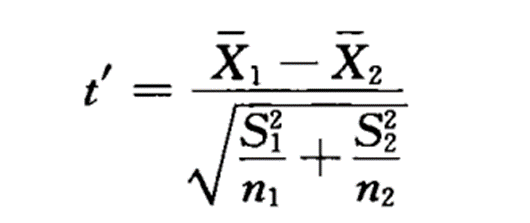
构造T检验量 t-stat
3.1 t 统计量是什么?
3.1.1 t统计量公式
t-stat= t=(average(x)-u) / (s/✔n)
t 检验量,比较的是均值average(x)
单样本t 检验量,比较的是均值average(x) 和u的差异
量样本t 检验量,比较的是均值average(x1) 和average(x2)
3.1.2 几个核心统计量的推导
t 检验量
因为核心是 average(x),所以其标准差为 (s/✔n)
如果 X ~N(u,δ) , 符合正态分布
那么 average(X) ~N(u,δ/✔n) ,符合正态分布,average(x) ~N(u,s✔n)
那么 average(X)-u / (δ/✔n) ~N(0,1) 符合标准正态分布
(n-1)s**2符合k2分布
t = average(X)-u / (δ/✔n) 就是构造的一个符合标准正态分布的t变量
3.2 t 统计量的另外一个公式,线性回归里每个参数的t值
每个回归系数的t值 → t-统计量=回归系数 / 回归系数标准误差
如果有多组样本,SE 标准误是标准差SD的平均值, SE=SD/✔n
回归系数标准误(standard error of regression coefficient)
3.3 构造t 统计量
3.3.1 单样本的t,构造过程
3.3.2 双样本的t,构造过程
3.3.3 配对样本t检验
3.4 t统计量的意义
T统计值是用来判断参数的显著程度的
应用回归预测法时应首先确定变量之间是否存在相关关系。但是如果变量之间不存在相关关系,对这些变量应用回归预测法就会得出错误的结果。
查表要根据,自由度df,显著度α
如果T值,小于查表所得T值,那么就认为落在大概率的区间,接受原假设H0
应用举例
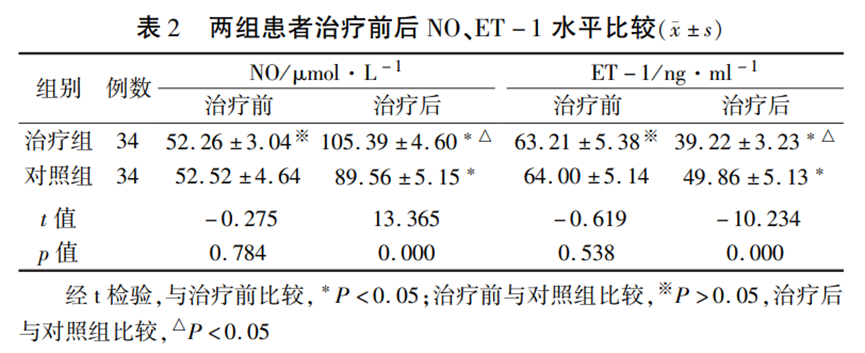
研究者为探索消溶稳斑方对冠脉微循环障碍患者血管内皮功能及炎症因子的影响。采用前瞻性研究,选取 2019年6 月至2020 年6 月符合纳入标准在河南中医药大学第一附属医院就诊的门诊和住院患者共 68 例。按随机数表法分为对照组行常规药物治疗,试验组在对照组基础上加消溶稳斑方治疗。观察两组治疗前后血管内皮功能、炎性因子及心脏功能的变化情况。
运用 SPSS 25.0 统计学软件对数据资料进行统计学分析。计量资料符合正态分布,用表示,组内比较采用配对样本t 检验,组间比较采用独立样本t 检验。P<0.05 表示差异具有统计学意义。
其中一项结果,两组患者治疗前后 NO、ET-1的水平比较,其中组内比较:两组组内治疗前后 NO、ET -1 水平比较采用配对样本 t 检验,结果显示两组患者治疗后 NO 水平均较治疗前增高、ET -1 水平均较治疗前降低,P<0.05,差异具有统计学意义。组间比较:采用独立样本t 检验,治疗后两组间 NO、ET -1 水平比较P<0.05.提示两组差异具有统计学意义,治疗组优于对照组。
1.单样本均值检验
目的:检验单样本的均值是否和已知总体的均值相等。


2.两独立样本均值检验
目的:检验两独立样本的均值是否相等。
要求:两样本独立,服从正态分布或近似正态。
应用场景举例:
- 检验两工厂生产同种零件的规格是否相等(双侧检验)
- 为研究某种治疗儿童贫血新药的疗效,以常规药作为对照,治疗一段时间后,检验施以新药的儿童血红蛋白的增加量是否比常规药的大(单侧检验)
- 检验两种药物对治疗高血压的效果,检验两组药物的降压水平是否相等(双侧检验)




3.配对样本均值检验
这种情况常常出现在生物医学研究中,常见的情形有:
- 配对的受试对象分别接受不同的处理(如将小白鼠配对为两组,分别接受不同的处理,检验处理结果的差异)
- 同一受试对象的两个部分接受不同的处理(如对于一批血清样本,将其分为两个部分,利用不同的方法接受某种化合物的检验,检验结果的差异)
- 同一受试对象的自身前后对照(如检验癌症患者术前、术后的某种指标的差异)
要求:
- 总体方差相等
- 正态数据或近似正态


注意,第2条和第3条两种检验不要误用,否则可能会得到错误的结论,参考文献[1]例7.2.4就是一个典型的例子,在此例中,配对检验消除了每一对自身的差异,若直接利用两独立样本检验,则无法消除这个差异,得到错误的结论。
4.回归系数的显著性检验
目的:检验回归模型的回归系数是否等于给定的值,一般取为0,此时检验的意义是检验该回归系数对应的解释变量对被解释变量是否有显著影响(因为若接受取值为0的假设,则该解释变量的项对被解释变量没有作用了)。
将多元线性回归模型:











 附录2.4 标准正态变量与卡方变量的独立性的证明
附录2.4 标准正态变量与卡方变量的独立性的证明
假设检验的步骤
假设检验可以分为三步:(1)建立检验假设和确定检验水准;(2)选定检验方法和计算检验统计量;(3)确定P值和做出推断结论。
建立检验假设和确定检验水准
检验假设是针对总体特征而言,包括相互对立的两个方面,即两种假设:一种是无效假设或称原假设、零假设,符号为H0,它是要否定的假设;另一种是备择假设,记为H1,它是H0的对立面。二者是从反证法的思想提出的, H1和H0是相互联系、又相互对立的假设。
假设检验还需根据不同研究目的事先设置是否拒绝原假设的判断标准,即检验水准。检验水准也称显著性水准,它指无效假设H0为真,但被错误地拒绝的一个小概率值,一般取检验水准α =0.05。
单侧检验与双侧检验
• 在进行t检验时,如果其目的在于检验两个总体均数是否相等,即为双侧检验。 例如检验某种新降压药与常用降压药效力是否相同?就是说,新药效力可能比旧药好,也可能比旧药差,或者力相同,都有可能。
• 如果我们已知新药效力不可能低于旧药效力,例如磺胺药+磺胺增效剂从理论上推知其效果不可能低于单用磺胺药,这时,无效假设为H0:μ1=μ2, 备择假设为H1: μ1>μ2 , 统计上称为单侧检验。
选定检验方法和计算检验统计量
要根据研究设计的类型和统计推断的目的选用不同的检验方法。如成组设计的两样本均数的比较用t检验,多个样本均数的比较用F检验。
检验统计量是用于抉择是否拒绝H0的统计量(因此在我们确定检验假设H0,H1时,检验方法和检验统计量就已经确定了),其统计分布在统计推断中是至关重要的,不同的检验方法要用不同的方式计算现有样本的检验统计量值。
确定P值和做出推断结论
这里的P值是指由H0成立时的检验统计量出现在由样本计算出来的检验统计量的末端或更末端处的概率值。
当P≤ α时,结论为按所取检验水准拒绝H0,接受H1,这样做出结论的理由是:在H0成立的条件下,出现等于及大于现有检验统计量值的概率P≤ α ,是小概率事件,这在一次抽样中是不大可能发生的,即现有样本信息不支持H0因而拒绝它;若P>α,即样本信息支持H0,就没有理由拒绝它,此时只好接受它。
假设检验的两类错误
Ⅰ型错误,第一类错误、假阳性错误,就是在假设检验作推断结论时,拒绝了实际上是正确的原假设H0,其概率用α表示。(拒绝正确)
Ⅰ型错误是针对原假设而言的, α就是事先规定 的 允 许 犯 Ⅰ 型 错 误 的 概 率 值 , 如 规 定α=0.05,意味着在某特定总体抽样, 100次拒绝H0的假设检验中,最多有5次允许发生第一类错误。与此相应,推断正确的可能性为1-α, 1-α又称为可信度。
Ⅱ型错误,第二类错误、假阴性错误, 即接受实际上是不成立的H0。就是无效假设原本是不正确的,但所算得的统计量不足以拒绝它,错误地得出了无差别的结论。(接受错误)
Ⅱ型错误是针对备择假设而言的,其概率值用β表示。β值的大小一般未知,只有在不
同总体特征已知的基础上,按预定的α和n才能做出估算。
| H0 | H0 | |
|---|---|---|
| True | False | |
| Accept | OK | II Error |
| Reject | I Error | OK |
SPSSAU
-
t 检验(独立样本t 检验),用于分析定类数据与定量数据之间的关系情况.例如研究人员想知道两组学生的智商平均值是否有显著差异.t 检验仅可对比两组数据的差异,如果为三组或更多,则使用方差分析.如果刚好仅两组,建议样本较少(低于100时)使用t 检验,反之使用方差分析。
-
首先判断p 值是否呈现出显著性,如果呈现出显著性,则说明两组数据具有显著性差异,具体差异可通过平均值进行对比判断。
分析项 t 检验说明 性别,网购满意度 不同性别的两类人群,他们网购满意度是否有差异? -
-
分析结果表格示例如下(SPSSAU同时会生成折线图等):
性别(平均值±标准差) t p 男(n=67) 女(n=53) 分析项1 3.23±1.33 2.88±0.73 3.73 0.03* 分析项2 2.62±1.48 2.57±1.21 0.56 0.58 * p <0.05 ** p <0.01 -
特别提示
-
备注:方差分析,t 检验和交叉(卡方),共三个分析方法,均是对比差异性。
X数据类型 X组别 Y 分析方法 定类 2组或者多组 定量 方差 定类 仅仅2组 定量 t 检验 定类 2组或者多组 定类 卡方 -
特别提示
-
t 检验一定只能对比两组数据的差异。如果提示“X的组别只能为两组(比如男和女)!”,说明不是2个组别。
-
检查方法为:将X进行频数分析,即可发现X有几个组别。
-
解决办法为:可使用方差分析,也或者将X多个组别组合成两个组别,使用数据编码功能。
SPSSAU操作截图如下:
-
t 检验案例
-
1、背景
当前有一份数据。想研究不同性别人群对“淘宝客服服务态度”,“淘宝商家服务质量”,这两项的差异性,“淘宝客服服务态度”,“淘宝商家服务质量”这两项均是定量数据,因而可使用t 检验,通过平均值进行差异性对比。
-
2、理论
t 检验时研究X对Y的差异性,其中X为定类数据,Y为定量数据。t 检验时分析时,首先分析p 值,如果此值小于0.05,说明呈现出差异性;具体差异再对比平均值即可。如果p 值大于0.05则说明没有差异性产生。t 值属于中间过程值,想要计算p 值,一定要先计算t 值,因而SPSSAU也将t 值结果输出。
-
特别提示
-
如果X和Y均为定类数据,想对比差异性,此时需要使用卡方分析。
-
如果X为定类,Y为定量;且X只能为两组,比如男和女;如果超过三组,比如本科以下,本科,本科以上,此时需要使用方差分析进行差异对比。
-
-
3、操作
本例子中研究X对于Y的差异;X为性别,Y为两项,分别是“淘宝客服服务态度”,“淘宝商家服务质量”。放置如下:
-
-
4、SPSSAU输出结果
性别(平均值±标准差) t p 男(n=40) 女(n=160) 分析项1 3.44±0.65 4.19±0.61 -6.86 0.00* 分析项2 3.53±0.64 4.22±0.64 -6.13 0.00* * p <0.05 **p <0.01 共输出t 值和p 值,以及还有平均值与标准差值。t 值和平均值才更有意义;但需要输出t 值和标准差值,原因在于p 值需要通过t 值计算得到,以及原理上是否有差异会与标准差值有关联性。
-
5、文字分析
-
使用t 检验去研究性别分别与“淘宝客服服务态度”,“淘宝商家服务质量”这两项的差异关系,结果显示,不同性别群体样本对于“淘宝客服服务态度”,“淘宝商家服务质量”均呈现出显著性差异(p <0.05)。具体对比可知:
-
不同性别人群对于“淘宝客服服务态度”呈现出0.01水平的显著性差异差异态度(t =-6.86,p =0.00 <0.01),具体通过平均值对比差异可知:相对男性群体,女性群体对于 “淘宝客服服务态度”的认可态度会越高。
-
不同性别人群对于““淘宝商家服务质量”” 呈现出0.01水平的显著性差异(t =-6.13,p =0.00 <0.01),具体通过平均值对比差异可知:相对男性群体,女性群体对于,他们对于““淘宝商家服务质量””的认可态度会越高。
-
特别提示
-
如果X共有三组,分别是本科以下,本科和本科以上;此时不能使用t 检验,而需要使用方差分析,t 检验仅对比两组间的差异。
-
-
6、剖析
t 检验涉及以下几个关键点,分别如下:
t 检验分析X对Y的差异性;X只能分为两组;如果X为三组,比如本科以下,本科,本科以上;此时需要使用方差分析。
疑难解惑
-
什么样的数据格式才适合?
-
有时候数据是手工录入,如果此时需要进行t 检验,则需要录入数据格式如下:
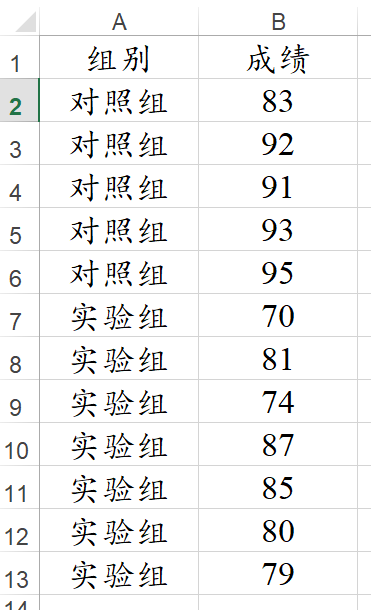
-
一定有1列表示叫‘组别’,而且里面只能为2种文字(或2个数字)。这样X就是‘组别’,Y是‘成绩’。
-
X的组别只能为两组(比如男和女)!?
-
t 检验的原理就是对比两组数据,因此X的数据中只能且一定包括两个数字。如果出现此提示,建议使用频数分析进行检查。如果是多数的差异对比应该使用方差分析。当然如果一定要使用t 检验,可使用‘筛选样本’功能,筛选出两组后进行分析即可。
-
关于效应量(effect size)说明?
-
t 检验分析时,通常使用Cohen's d 值表示效应量,其计算公式为:Cohen's d =|M1-M2| / Sqrt(S2pool),即差值绝对值 / 标准差, 标准差=Sqrt(联合方差)。M1表示第一组数据的平均值,M2表示第二组数据的平均值,联合方差S2pool为中间过程值,Sqrt指开根号;
-
Cohen's d 值介于0~1之间,该值越大说明差异幅度越大;
-
0 < Cohen's d <=0.2时,说明效应较小(差异幅度较小);
-
0.2 < Cohen's d <=0.8时,即 0.5附近时,说明效应中等(差异幅度中等);
-
Cohen's d > 0.8时,说明效应较大(差异幅度较大)。
t检验分析步骤
T检验过比较不同数据的均值,研究两组数据之间是否存在差异。可以分为三种,分别是单样本T检验、配对样本T检验、独立样本T检验。
独立样本t检验
1.研究场景
独立样本t 检验用于分析定类数据与定量数据之间的关系情况。例如研究人员想知道两组学生的智商平均值是否有显著差异。t 检验仅可对比两组数据的差异,如果为三组或更多,则使用方差分析。如果刚好仅两组,建议样本较少(低于100时)使用t 检验,反之使用方差分析。
2.数据格式
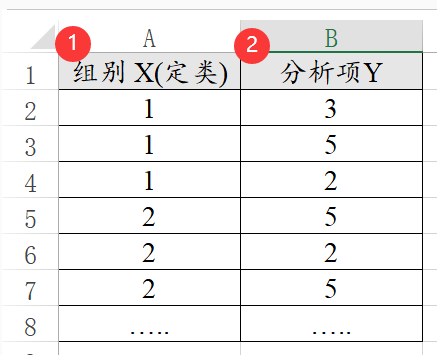
独立样本t 检验是研究2组数据的差异,比如不同性别时满意度的差异。数据格式中需要有组别X(比如性别)和分析项Y(比如满意度)。
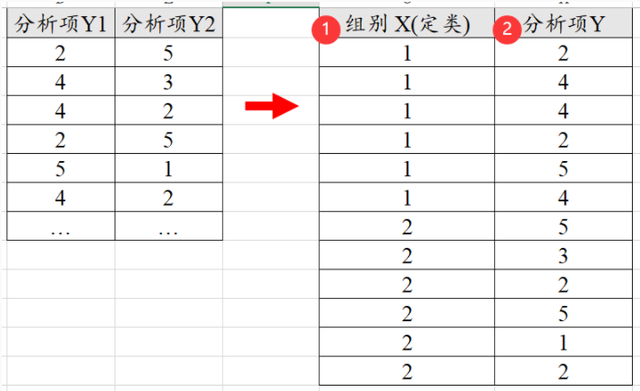
有时候数据格式中只有2列,而没有组别,比如实验组和对照组。那么就需要对数据进行改造,自己加入一列‘组别’,然后把数据重叠起来得到分析项Y,类似如下图:
3.分析前提
(1)正态性检验
独立样本t检验要求两组数据满足正态性检验;正态性检验的方法有很多,例如:正态性检验、直方图、P-P图/Q-Q图等。
补充说明:独立样本t检验具有一定的耐受性,如果数据只是稍稍偏离正态,结果仍然是稳定的,但是如果数据严重偏离,此时均数不能很好的代表数据的集中趋势,这种情况下最好考虑采用变量转化(其中包括:取对数,开根号,BoxCOX变换等)或者使用非参数检验:MannWhitney检验(SPSSAU通用方法->非参数检验)。
(2)方差齐性检验
对于独立样本t检验,除了要满足正态性,还需要满足方差齐的前提条件。即方差齐的情况下,才可以使用t检验。在做t检验时,SPSSAU会自动完成方差齐检验,并根据检验结果,自动判断结果输出哪一种结果,因此研究者不需要再单独检验方差齐性。
4.SPSSAU操作
(1)登录账号后进入SPSSAU页面,点击右上角“上传数据”,将处理好的数据进行“点击上传文件”上传即可。

(2)拖拽分析项
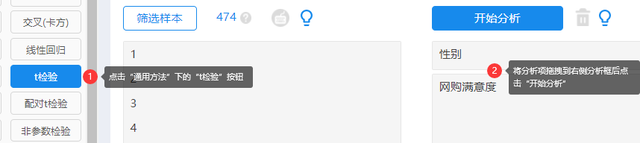
在“通用方法”模块中选择“t检验”方法,将X定类变量(仅两组)放于上方分析框内,Y定量变量放于下方分析框内,点击“开始分析”即可。
5.SPSSAU分析
背景:研究不同性别群体对网购满意度是否有差异。
(1)t 检验分析结果
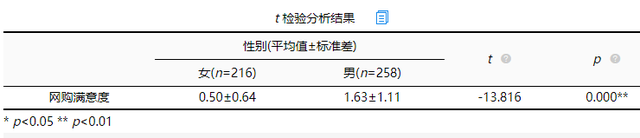
从上表可以看出:不同性别样本对于网购满意度全部均呈现出显著性(p<0.05),意味着不同性别样本对于网购满意度均有着差异性。具体分析可知:性别对于网购满意度呈现出0.01水平显著性(t=-13.816,p=0.000),以及具体对比差异可知, 女的平均值(0.50),会明显低于男的平均值(1.63)。总结可知:不同性别样本对于网购满意度全部均呈现出显著性差异。

(2)柱形图
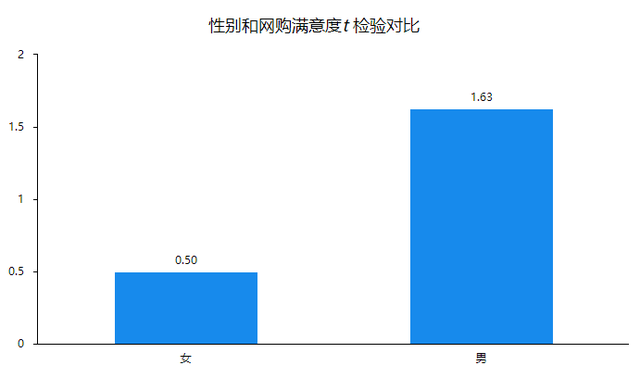
从柱形图中具体对比差异可知, 女性的平均值(0.50),会明显低于男性的平均值(1.63)。
(3)效应量指标

如果t检验显示呈现出显著性差异(p<0.05),可通过平均值对比具体差异,同时还可使用效应量(Effect size)研究差异幅度情况;
第一:t检验时使用Cohen's d 值表示效应量大小(差异幅度大小),该值越大说明差异越大;
第二:t检验使用Cohen's d 值表示效应量大小时,效应量小、中、大的区分临界点分别是:0.20,0.50和0.80;
第三:Cohen's d 值计算公式为差值的绝对值/标准差,标准差=Sqrt(联合方差)。
6.其他说明
(1)提示X的组别只能为两组(比如男和女)!?
t 检验的原理就是对比两组数据,因此X的数据中只能且一定包括两个数字。如果出现此提示,建议使用频数分析进行检查。如果是多数的差异对比应该使用方差分析。当然如果一定要使用t 检验,可使用‘筛选样本’功能,筛选出两组后进行分析即可。
(2)t检验(独立样本t检验)两组样本需不需要一致?
独立样本t检验对样本量没有要求,而配对样本T检验则要求两组样本量一定相等,两组样本需要有对应的关系。
配对t检验

1.研究场景
配对t 检验,用于配对定量数据之间的差异对比关系.例如在两种背景情况下(有广告和无广告);样本的购买意愿是否有着明显的差异性;配对t 检验通常用于实验研究中。
2.数据格式
配对数据的格式相对较为特殊,包括配对t 检验,或者配对卡方等。比如实验组和对照组数据的差异。如下图:
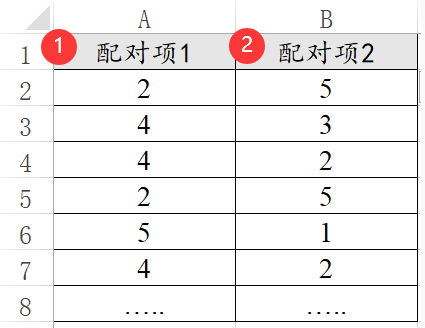
配对数据一般是在实验时使用,而且配对数据的特点为:行数一定完全相等并且只有两列。如果研究数据的行数不相等,那可能不是配对数据,如果还想对比差异,可能需要使用独立t 检验。独立t 检验和配对t 检验的数据格式不一样,需要特别注意。
3.分析前提
配对t检验要求两组数据满足正态性检验;其说明与独立样本t检验大致一样。
4.SPSSAU操作
(1)登录账号后进入SPSSAU页面,点击右上角“上传数据”,将处理好的数据进行“点击上传文件”上传即可。
(2)拖拽分析项
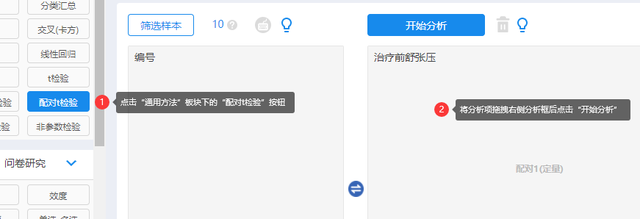
在“通用方法”模块中选择“配对t检验”方法,将配对1(定量)放于上方分析框内,配对2(定量)变量放于下方分析框内,点击“开始分析”即可。
5.SPSSAU分析
背景:以体育疗法治疗高血压,10个高血压患者在施以体育疗法前后测定舒张压,研究体育疗法对高血压是否有效。(案例来源于:SPSS统计分析 第5版)
(1)配对t 检验分析结果

从上表可以看出:总共1组配对数据,均会呈现出差异性(p<0.05) 。具体分析可知:治疗前舒张压和治疗后舒张压之间呈现出0.01水平的显著性(t=5.639,p=0.000),以及具体对比差异可知,治疗前舒张压的平均值(119.50),会明显高于治疗后舒张压的平均值(102.50)。
(2)效应量指标


(3)结果的详细格式

对比差异可知,治疗前舒张压的平均值(119.50),会明显高于治疗后舒张压的平均值(102.50)。治疗前舒张压和治疗后舒张压之间呈现出0.01水平的显著性(t=5.639,p=0.000)。
6.其他说明
关于效应量(effect size)说明:
配对t 检验分析, 当呈现出显著差异性(前提)时,可分析差异,同时还可以分析差异幅度(即效应量) (提示:效应量分析为可选,只有深入研究时才需要分析);
配对t 检验分析时,通常使用Cohen's d 值表示效应量,其计算公为:Cohen's d =|M1-M2| / S,即差值绝对值 / 标准差;具体说明如下:
(1)Cohen's d 值介于0~1之间,该值越大说明差异幅度越大;
(2)< Cohen's d <=0.2时,说明效应较小(差异幅度较小);
(3)0.2 < Cohen's d <=0.8时,即 0.5附近时,说明效应中等(差异幅度中等);
(4Cohen's d > 0.8时,说明效应较大(差异幅度较大)。
单样本t检验
1.研究场景
单样本t 检验用于分析定量数据是否与某个数字有着显著的差异性,比如五级量表,3分代表中立态度,可以使用单样本t 检验分析样本的态度是否明显不为中立状态;系统默认以0分进行对比。
2.分析前提
单样本t检验要求两组数据满足正态性检验;其说明与独立样本t检验大致一样。
3.SPSSAU操作
(1)登录账号后进入SPSSAU页面,点击右上角“上传数据”,将处理好的数据进行“点击上传文件”上传即可。
(2)拖拽分析项
在“通用方法”模块中选择“单样本t检验”方法,将分析项拖拽到右侧分析框中,输入对比数字,点击“开始分析”即可。

(3)对比数字
输入对比数字,默认是0,如下图:
4.SPSSAU分析
(1)单样本t 检验分析结果


从上表可以看出:14岁女孩身高全部均呈现出显著性(p<0.05),意味着14岁女孩身高共1项的平均值均与数字150.0有着统计意义上的差异。具体分析可知:14岁女孩身高共1项,它们的平均值会明显的低于数字150.0。
(2)效应量指标


5.其他说明
(1)关于效应量(effect size)说明?
当呈现出显著差异性(前提)时,可分析差异,同时还可以分析差异幅度(即效应量) (提示:效应量分析为可选,只有深入研究时才需要分析);
单样本t 检验分析时,通常使用Cohen's d 值表示效应量,其计算公式为:Cohen's d =差值绝对值 / 标准差;
Cohen's d 值介于0~1之间,该值越大说明差异幅度越大,具体如下:
0 < Cohen's d <=0.2时,说明效应较小(差异幅度较小);
0.2 < Cohen's d <=0.8时,即 0.5附近时,说明效应中等(差异幅度中等);
Cohen's d > 0.8时,说明效应较大(差异幅度较大)。
(2)t检验结果中出现null值?
结果中出现null值,多是由于数据格式错误或某一组数据只包含一个样本(n=1),导致算法无法计算出指标值。
代码实现
JAVA
单样本 t 检验
# Import numpy and scipy
import numpy as np
from scipy import stats
# Create fake data sample of 30 cans from 2 factories
factory_a = np.full(30, 355) + np.random.normal(0, 3, 30)
factory_b = np.full(30, 353) + np.random.normal(0, 3, 30)
# Run a 1 sample t-test for each one
a_stat, a_pval = stats.ttest_1samp(a=factory_a, popmean=355, alternative='two-sided')
b_stat, b_pval = stats.ttest_1samp(a=factory_b, popmean=355, alternative='two-sided')
# Display results
print("Factory A- t-stat: {:.2f} pval: {:.4f}".format(a_stat, a_pval))
print("Factory B- t-stat: {:.2f} pval: {:.4f}".format(b_stat, b_pval))
## Output
# Factory A- t-stat: 0.37 pval: 0.7140
# Factory B- t-stat: -3.96 pval: 0.000双样本 t 检验
# Import numpy and scipy
import numpy as np
from scipy import stats
# Create fake data sample of 30 cans from 2 factories
factory_a = np.full(30, 355) + np.random.normal(0, 3, 30)
factory_b = np.full(30, 353) + np.random.normal(0, 3, 30)
# Run a two sample t-test to compare the two samples
tstat, pval = stats.ttest_ind(a=factory_a, b=factory_b, alternative="two-sided")
# Display results
print("t-stat: {:.2f} pval: {:.4f}".format(tstat, pval))
## Output
# t-stat: 3.15 pval: 0.0026配对 t 检验
# Import numpy and scipy
import numpy as np
from scipy import stats
# Create array of worker bottling rates between 10 and 20 bottles/min
pre_training = np.random.randint(low=10, high=20, size=30)
# Define "training" function and apply
def apply_training(worker):
return worker + np.random.randint(-1, 4)
post_training = list(map(apply_training, pre_training))
# Run a paired t-test to compare worker productivity before & after the training
tstat, pval = stats.ttest_rel(post_training, pre_training)
# Display results
print("t-stat: {:.2f} pval: {:.4f}".format(tstat, pval))
## Output
# t-stat: 2.80 pval: 0.0091# Take differences in productivity, pre vs. post
differences = [x-y for x,y in zip(post_training, pre_training)]
# Run a 1-sample t-test on the differences with a popmean of 0
tstat, pval = stats.ttest_1samp(differences, 0)
# Display results
print("t-stat: {:.2f} pval: {:.4f}".format(tstat, pval))
## Output
# t-stat: 2.80 pval: 0.0091















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











