







clickhouse
简介
2016年,俄罗斯Yandex开源,列式存储数据库,底层是C++,用于在线分析处理查询(OLAP)。Clickhouse提供了相当丰富的内置函数满足不同业务需求,并且具备高吞吐低延时的特点,官网称简单查询,clickhouse的处理速度大约是1-2亿行每秒。另外,clickhouse的官方文档是我见过最简单明了的开源文档。
行式存储
适合插入、更新和删除场景

列式存储
适合查询场景(想查年龄这列,直接拿出来就行)


clickhouse的缺点:
-
没有完整的事务支持。
-
缺少高频率,低延迟的修改或删除已存在数据的能力,仅能用于批量删除或修改数据,但这符合 GDPR。
-
稀疏索引使得ClickHouse不适合通过其键检索单行的点查询。
-
对于高qps的查询业务,clickhouse不是强项。
性能对比


结论:ck适合宽表,不适合做join操作
数据类型
clickhouse提供了丰富的数据类型,不仅支持简单数据类型Int,String等,还支持复合数据类型Array,Tuple,Map等,详见官网。
注意1:
Decimal,s代表小数点后面保留的位数。


注意2:
clickhouse不建议存空值(null),可以使用一些无意义的值进行代替,如数字的-1或者字符串的“”
表引擎概览
TinyLog
- 列文件形式保存在磁盘上
- 不支持索引
- 没有并发控制
- 一般不用于生产环境
Memory
- 内存引擎
- 读写操作不会相互阻塞
- 不支持索引
- 简单查询下超过10G/s的高性能表现
- 一般不用于生产,用于测试数据量不大(1亿行以内)的场景
MergeTree
- CK最强大的表引擎
- 支持分区和索引
- 相当于innodb之于MySQL
- 众多衍生引擎基于MergeTree
- 注意:主键可以不唯一
更多表引擎参见官网
MergeTree
建表使用MergeTree引擎
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1] [TTL expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2] [TTL expr2],
...
INDEX index_name1 expr1 TYPE type1(...) GRANULARITY value1,
INDEX index_name2 expr2 TYPE type2(...) GRANULARITY value2,
...
PROJECTION projection_name_1 (SELECT <COLUMN LIST EXPR> [GROUP BY] [ORDER BY]),
PROJECTION projection_name_2 (SELECT <COLUMN LIST EXPR> [GROUP BY] [ORDER BY])
) ENGINE = MergeTree()
ORDER BY expr
[PARTITION BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[TTL expr
[DELETE|TO DISK 'xxx'|TO VOLUME 'xxx' [, ...] ]
[WHERE conditions]
[GROUP BY key_expr [SET v1 = aggr_func(v1) [, v2 = aggr_func(v2) ...]] ] ]
[SETTINGS name=value, ...]
PARTITION BY 分区 (可选)
作用:降低扫描范围,优化查询速度
并行:一个分区一个线程进行数据处理
建议:实际生产一般按天为单位进行分区
分区磁盘存储文件结构(/var/lib/clickhouse):
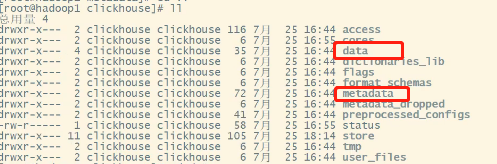
data存储数据,metadata存储表结构。
data/库名/表名/分区目录(eg. 20211009_1_1_0)
数据写入与分区合并
任何一个批次的数据写入都会产生一个临时分区,写入后过大概10-15min,CK会自动执行合并操作,也可手动触发合并。
optimize table *** final
PRIMARY KEY 主键(可选)
CK主键特点:它只提供了数据的一级索引,但却不是唯一约束,这意味着CK的主键是可以出现重复数据的。主键使用稀疏索引,即根据索引粒度(index granularity,默认是8192),间隔地存储对应的数据。

ORDER BY(必选)
order by设定了分区内的数据按照哪些字段进行有序保存,主键可以不设置,如果设置必须是order by字段的前缀字段。eg. order by(id,sku_id),主键可以是id或者(id,sku_id),但不能是sku_id。
数据TTL
TTL(Time To Live):过期时间,MergeTree提供的可以管理数据表或者列的生命周期的功能。
用途:用户画像,比如用户画像分析只需要用户最近三天的数据
列级TTL
CREATE TABLE example_table
(
d DateTime,
a Int TTL d + INTERVAL 1 MONTH,
b Int TTL d + INTERVAL 1 MONTH,
c String
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(d)
ORDER BY d;
ALTER TABLE example_table
MODIFY COLUMN
c String TTL d + INTERVAL 1 DAY;
注意:1. TTL后面跟的字段必须是日期类型; 2. TTL后面跟的字段不能是主键
表级TTL
CREATE TABLE example_table
(
d DateTime,
a Int
)
ENGINE = MergeTree
PARTITION BY toYYYYMM(d)
ORDER BY d
TTL d + INTERVAL 1 MONTH [DELETE],
d + INTERVAL 1 WEEK TO VOLUME 'aaa',
d + INTERVAL 2 WEEK TO DISK 'bbb';
ALTER TABLE example_table
MODIFY TTL d + INTERVAL 1 DAY;
ReplacingMergeTree
功能:与MergeTree基本一致,比MergeTree多了一个去重的功能,根据order by字段去重。
去重时机:合并的过程中去重,只能保证最终一致性,所以生产环境必须慎重考虑
去重范围:分区内去重,不能跨分区去重
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = ReplacingMergeTree([ver]) --[ver]可选,用于去重时选择保留的记录,保留[ver]最大的记录;不填默认按插入顺序去重
[PARTITION BY expr]
[ORDER BY expr]
[PRIMARY KEY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
SummingMergeTree
- 以SummingMergeTree([columns])指定的列作为汇总的数据列
- [columns]可选,但必须是数值型列,如果不填,默认所有数字列汇总
- order by列作为维度列
- 不能跨分区汇总
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster]
(
name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1],
name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2],
...
) ENGINE = SummingMergeTree([columns])
[PARTITION BY expr]
[ORDER BY expr]
[SAMPLE BY expr]
[SETTINGS name=value, ...]
SQL操作
-
删除操作
alter table table_name delete where column='**' -
修改操作
alter table table_name update column='**' where expr
注意:由于删除和修改操作不支持事务且比较重(Mutation语句分两步,同步执行的部分只进行新增数据新增分区并把旧分区打上逻辑失效标识。直到触发合并分区的操作时才会删除旧数据释放磁盘),一般不开放权限给普通用户,由管理员完成。
解决思路:对于经常需要更新的数据加一个版本号字段,每次查询取版本号最新的数据;对于经常需要删除的数据加一个删除标记字段,每次查询只取没有删除标记的数据。需要同时考虑无用数据删除机制。
-
导出数据
clickhouse-client --query="select * from tablename where expr" --format=CSVWithNames > data.csv
Explain执行计划
20.6.3.28版本才引入Explain,之前的版本不支持
查看执行计划
explain plan ***
查看syntax
// 开启三元运算符优化
set optimize_if_chain_to_multiif = 1;
// 查看语法优化
explain syntax ***
SQL优化
-
字段类型优化
建表时能用数值型或日期时间型表示的字段就不要用字符串
-
空值优化
官方已经指出Nullable类型几乎总是会拖累性能,因为存储Nullable列时需要创建一个额外的文件来存储NULL的标记,并且Nullable列无法被索引。因此除非极特殊情况,应直接使用字段默认值表示空,或者自行指定一个在业务中无意义的值(例如用-1表示没有商品ID)
-
分区颗粒度优化
分区粒度根据业务特点决定,不宜过粗或过细。一般选择按天分区,也可以指定为Tuple(),以单表一亿数据为例,分区大小控制在10-30个为最佳
-
order by索引优化
通常需要满足高级列在前、查询频率大的在前原则;还有基数特别大的不适合做索引列,如用户表的userid字段(必要情况下对userid进行hash也可以);通常筛选后的数据满足在百万以内为最佳
-
表参数优化
Index_granularity是用来控制索引粒度的,默认是8192,如非必须不建议调整
如果表中不是必须保留全量历史数据,建议指定TTL(生存时间值),可以免去手动过期历史数据的麻烦,TTL也可以通过alter table语句随时修改
-
写入和删除优化
1)尽量不要执行单条或小批量删除和插入操作,这样会产生小分区文件,给后台Merge任务带来巨大压力
2)不要一次写入太多分区,或数据写入太快,数据写入太快会导致Merge速度跟不上而报错,一般建议每秒钟发起2-3次写入操作,每次操作写入2w~5w条数据(依服务器性能而定)
-
配置
config.xml的配置项:
https://clickhouse.tech/docs/en/operations/server-configuration-parameters/settings/
users.xml的配置项(主要配置这个):
https://clickhouse.tech/docs/en/operations/settings/settings/


-
语法优化
-
count优化:不带where条件直接使用select count()
-
谓词下推:CK会自动优化,把where语句添加到子查询中
-
聚合外推:如sum(num*2),CK会自动优化为sum(num)*2
-
聚合函数消除:自动消除聚合函数中无用的函数
-
-
单表查询优化
-
使用prewhere 代替where
-
数据采样

-
列裁剪(只select需要的列)和分区裁剪(where语句加上分区字段)
-
group by 结合where和limit一起用
-
避免构建虚拟列,如income/age 这样的列。建议:先拿出income和age,在业务端进行相除
-
用uniqCombined代替distinct(uniqCombined求出的值是一个近似值,但性能可以提升10倍以上)
 - 使用物化视图
- 使用物化视图 -
批量写入先按分区字段排好
-
-
多表关联优化
【小技巧】只复制表结构,不复制表数据可以这么写↓

- 用IN替代JOIN
数据去重
-
通过replacingMergeTree去重:不推荐,因为去重发生在合并的时候,不可控
-
通过视图+设置删除键+group by在查询时去重(推荐)
-
通过FINAL查询,建议20.5以后的版本使用(20.5前是单线程)
select ** from ** FINAL where **
物化视图
普通视图不保存数据,只保存查询语句。物化视图把查询的结果保存到磁盘或者内存中(根据表引擎而定)
ClickHouse 中的物化视图更像是插入触发器。 如果视图查询中有一些聚合,则它仅应用于一批新插入的数据。 对源表现有数据的任何更改(如更新、删除、删除分区等)都不会更改物化视图。
优缺点
优点:查询速度快
缺点:本质是流式数据,使用累加技术,对历史数据去重、聚合不友好
创建

常见问题排查
-
问题:副本表不一致,某个节点缺失表
解决:在有表的节点show create table ** ,然后复制建表语句到缺失表的节点,CK会自动恢复数据
-
问题:某个数据副本异常无法启动,需要重新搭建副本
解决:清空异常副本节点的metadata和data目录,从正常副本节点将metadata拷贝过来,然后执行 sudo clickhouse touch /data/clickhouse/flags/force_restore_data,启动数据库。
监控及备份
Clickhouse在V20.1.2.4开始,内置对接了Prometheus的功能,可以将其作为Promecheus的Endpoint服务,从而自动将metrics、events和asynchronous_metrics三张系统表的数据发给Prometheus。
Prometheus下载地址:https://prometheus.io/download/
Grafana下载地址:https://grafana.com/get/?plcmt=top-nav&cta=downloads
Prometheus安装
-
下载并解压
-
修改prometheus.yml,加上clickhouse的配置
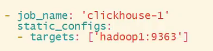
-
启动 nohub ./promrtheus --config.file=prometheus.yml > ./prometheus.log 2>&1 &
-
浏览器打开Prometheus的服务器地址,端口9090
Grafana安装
- 下载并解压
- 启动 nohub ./bin/grafana-serverweb > ./grafana.log 2>&1 &
- 浏览器打开Grafana的服务器地址,端口3000,用户名密码:admin
clickhouse监控配置
编辑/etc/clickhouse-server/config.xml。重启clickhouse restart

Grafana集成Prometheus
- 添加数据源




- 添加监控指标

也可以直接上官网下载监控模板:https://grafana.com/grafana/dashboards/,然后点击上图的Import导入进来即可。
备份
参考:https://clickhouse.com/docs/en/operations/backup/
注意:手动备份目录所属的用户必须是clickhouse
建议:直接使用官网工具备份














 593
593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









