







最近看了一篇文章,讲了一大堆,最后得出一些结论。说是在某种情况下,怎么写速度最快。但是自己去实际验证的时候,其实并不是他说的那样,实践出真知,所以自己就把测试的数据整理一下,看看到底哪种情况最快?
一、他们之间的区别
1、cout(*)返回表中的记录数,行为空也会被统计。
2、count(列名)对指定列的行数进行统计,行为null不做统计。
3、count(*)和count(1)两个函数没有区别。通过执行计划查看,他们的执行计划是一样的。
二、执行计划脚本
select count(*) from lc_policy;
select count(1) from lc_policy;
#根据主键
select count(policyId) from lc_policy;
#索引列不可能空
select count(orderNo) from lc_policy;
#非主键列查询(前面字段)
select count(totalPremium) from lc_policy;
#非主键列查询(后面字段)
select count(contEndDate) from lc_policy;
三、执行计划查看
cout(*)的执行计划

count(1)的执行计划

count(policyId)的执行计划

count(orderNo)的执行计划

count(totalPremium)的执行计划

count(contEndDate)的执行计划

通过执行计划,我们知道
count(*)、count(1)、count(policyId)和count(orderNo)的执行计划是一样的。
count(totalPremium)和count(contEndDate)的执行计划是一样的。
四、实践结果
我们通过一张有24万数据的表测试一下他们的性能,正常情况生产环境表都是有主键,所以就不考虑无主键的情况了。
40次统计结果如下

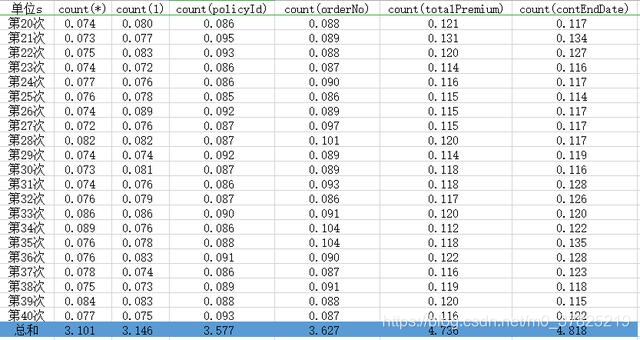
通过上面的结果分析,我们可以得到下面的几个结论:
1、count(*)和count(1)查询速度几乎没有差别,是最快的。
2、count(*)和count(1)的查询速度比根据主键或者索引查询快。
3、根据主键查询比根据索引查询快,但是时间差别不大。
4、根据主键查询count(policyId)速度快于根据普通列查询数据。
5、表结构前面字段的查询速度,和通过后面字段的查询速度差别不大。(相差17个字段)
上面是mysql数据的结果,可能不同的版本、不同的数据库、不同的数据量或者不同的表结构及索引对结果会有一定的影响,有待继续验证。
但是可以肯定的是根据count(*)或者count(1)查询应该是最优方案。
五、扩展
表结构没有主键,但是有索引列,索引列可以为空,这种情况最快的查询是那种呢?
速度应该是count(索引列)最快的。因为索引列可以为空,count(*)和count(索引列)的结果是不一样的,这里不做比对了,个人可以去验证下查询速度。
喜欢的话,可以关注“莫非技术栈”,各种学习资料免费送~
















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









