







目录
一、堆
这里的堆是一种特殊的树结构,跟我们平时使用的物理内存堆没有任何关系。具有以下特点:
1、堆是一个完全二叉树。除了最后一层,其它层节点个数都是满的,最后一层的节点都靠左排列
2、堆中每一个节点的值都必须大于等于(或小于等于)其子树中每个节点的值。对于每个节点的值都大于等于其子树每个节点的值的堆被称为“大顶堆”,相反则为“小顶堆”。
二、堆实现
1、堆存储
完全二叉树比较适合用数组来存储。用数组来存储完全二叉树是非常节省存储空间的。因为我们不需要存储左右子节点的指针,单纯地通过数组的下标,就可以找到一个节点的左右子节点和父节点。
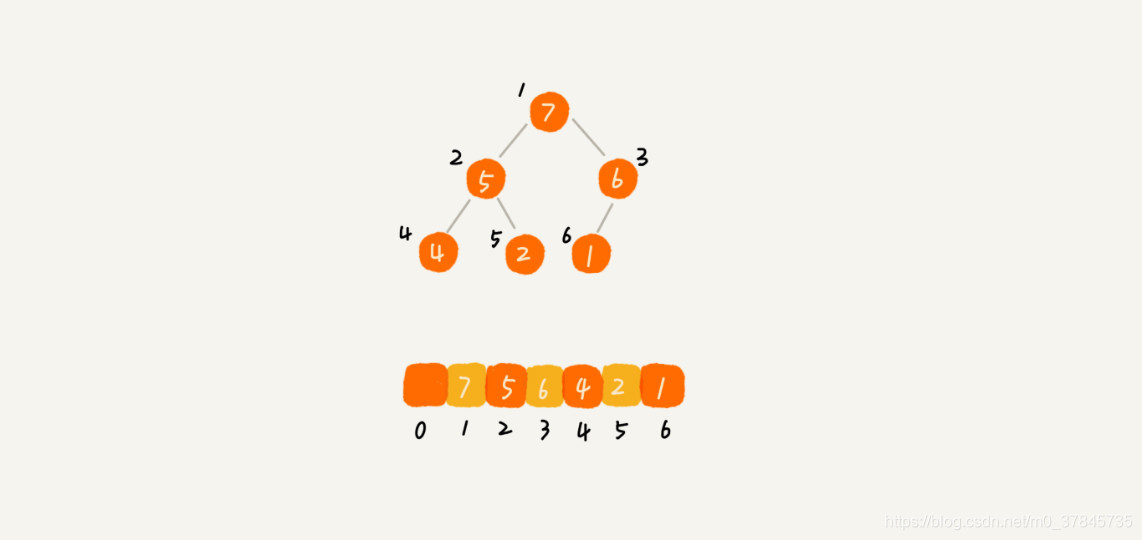
数据是从下表为1开始存储的时,数组中下标为 i 的节点,左子节点就是下标为 i∗2 的节点,右子节点就是下标为 i∗2+1 的节点,父节点就是下标为 i / 2 的节点。
2、堆操作
一个包含 n 个节点的完全二叉树,树的高度不会超过 log2n。堆化的过程是顺着节点所在路径比较交换的,所以堆化的时间复杂度跟树的高度成正比,也就是 O(logn)。插入数据和删除堆顶元素的主要逻辑就是堆化,所以,往堆中插入一个元素和删除堆顶元素的时间复杂度都是 O(logn)
1、插入新的元素
由于堆存储结构为数组,可以将新插入的元素放到堆得最后,往堆中插入一个元素后,还需要满足堆的两个特性,不满足特性的还需要进行调整,这个过程叫 堆化(heapify)
堆化实际上有两种,从下往上和从上往下。以下是从下往上的堆化方法
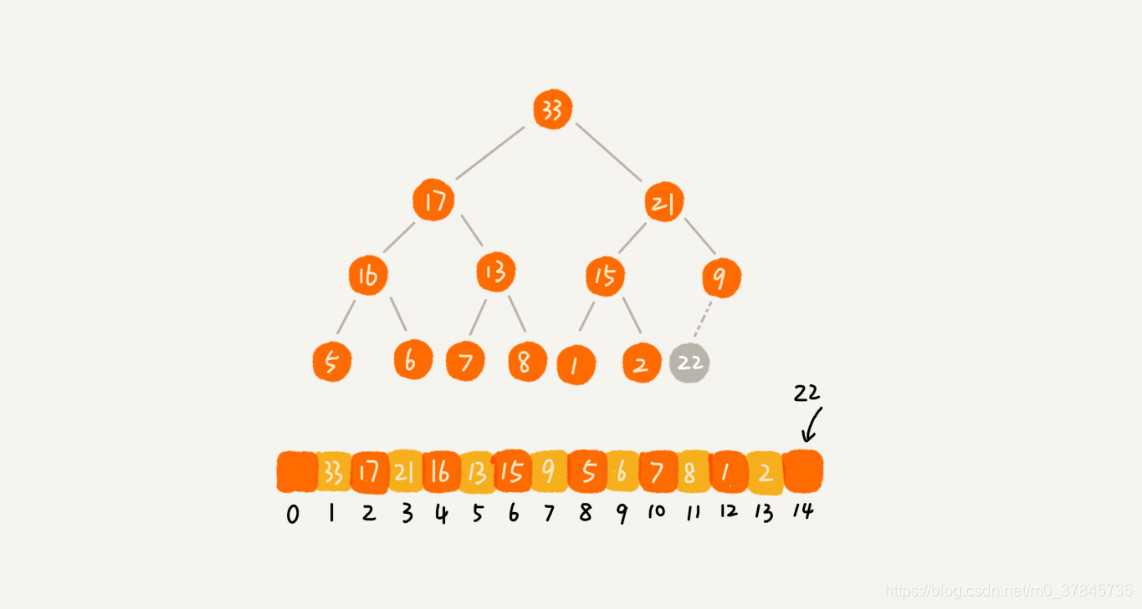
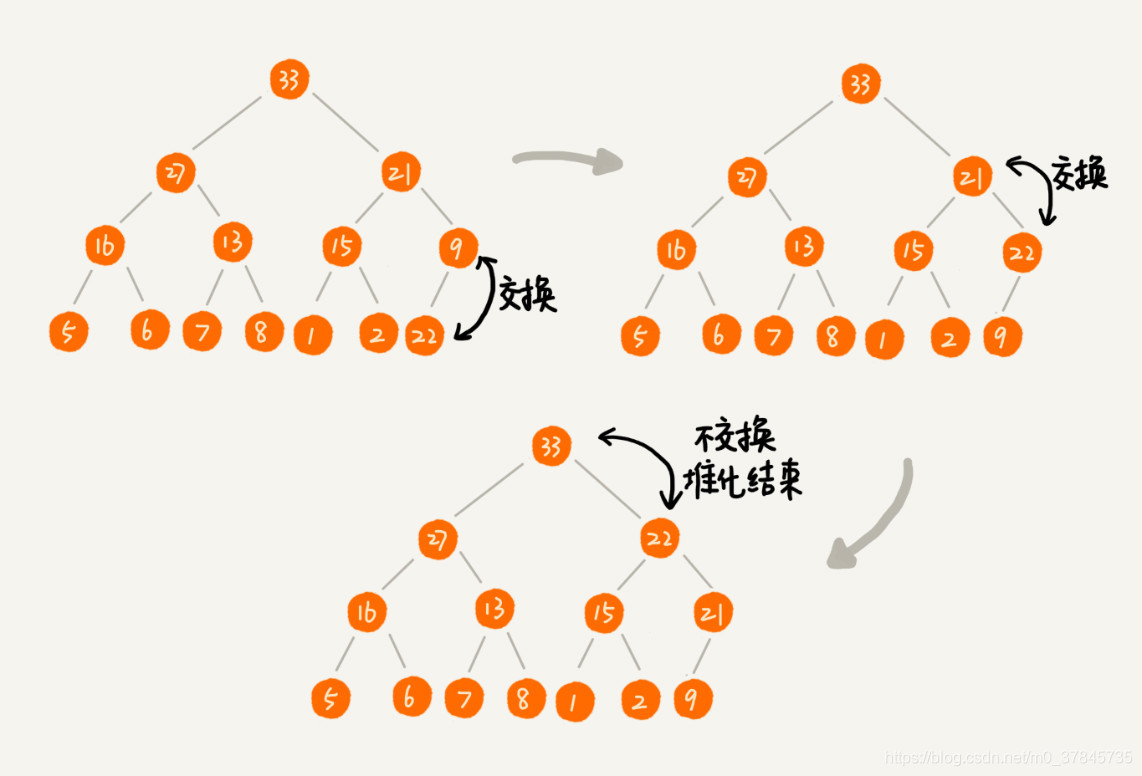
2、删除堆顶元素
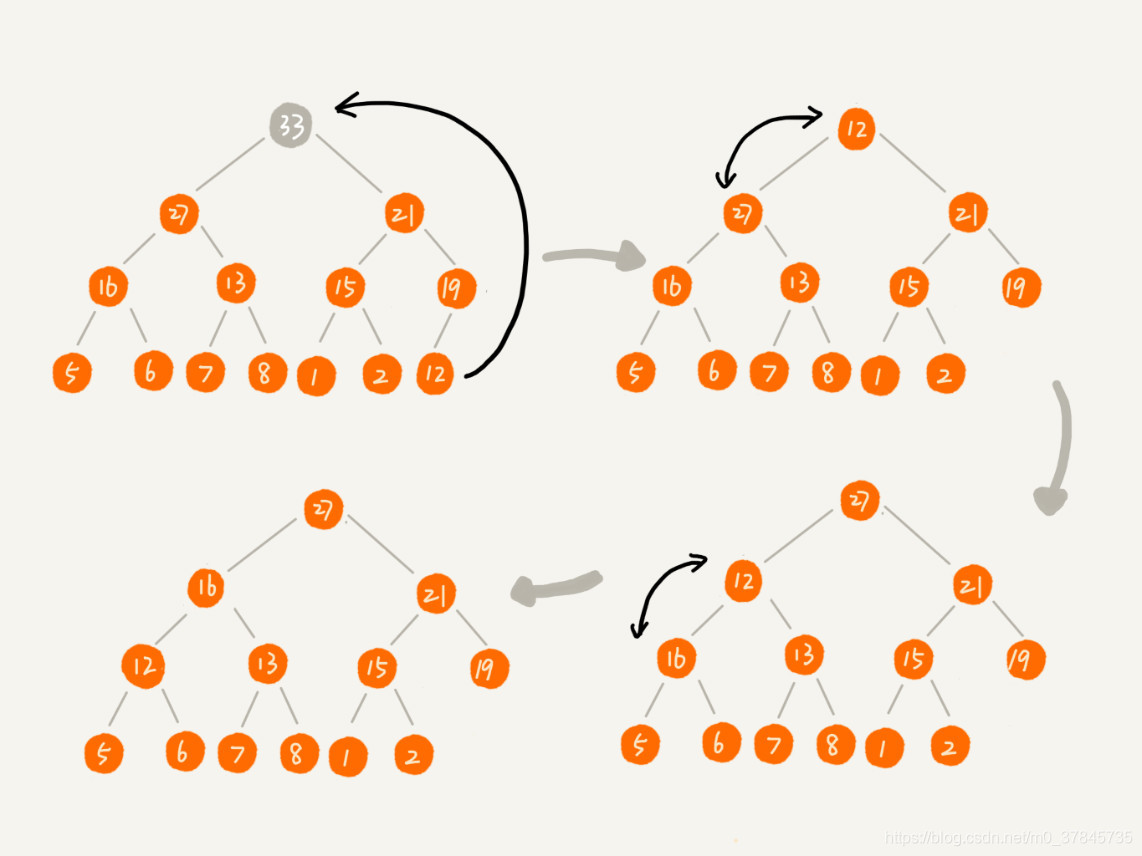
根据堆的第二条特性可知,堆顶元素存放的必定是堆中数据的最大值或最小值。对于大顶堆来说,如果删除了堆顶元素后,堆中第二大的数据肯定在堆顶元素的左右节点中,这是我们需要将第二大的数据放至堆顶,以此类推,直到叶子节点被删除。但这种方法删除堆顶元素后,可能堆化出来的堆并不满足堆的特性了,叶子节点可能为空。
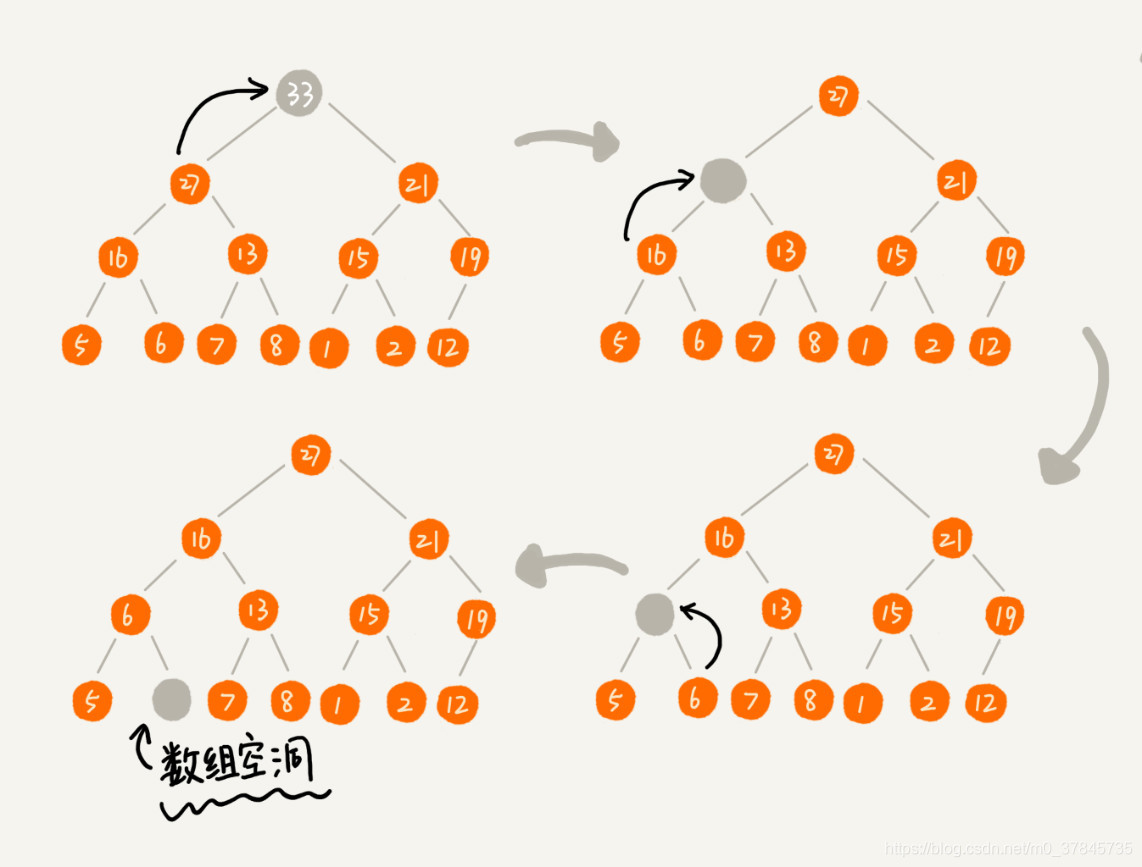
由于堆在堆化过程中只是交换了两个元素的位置,所以如果将堆顶元素删除后,将堆(数组)中的最后一个元素放至堆顶,然后利用同样的父子节点判断方法进行堆化,那么最后删除的位置肯定是最后一个节点,就不会出现“数组空洞”的现象
三、堆的应用
1、堆排序
我们可以把堆排序的过程大致分解成两个大的步骤,建堆 和 排序
1、建堆
方法一:从前往后处理数组数据,在堆中插入一个元素后,依次将下标为1-n的数据插入堆中并进行堆化。每插如一个节点就会进行一次堆化
方法二:从后往前处理数组数据,从第一个非叶子节点开始,依次向前堆化。对下标从 n/2 开始到 1 的数据进行堆化,下标是 n/2+1 到 n 的节点是叶子节点,我们不需要堆化。实际上,对于完全二叉树来说,下标从 n/2+1 到 n 的节点都是叶子节点。这种方法适用于对一个已有的数组进行堆化。
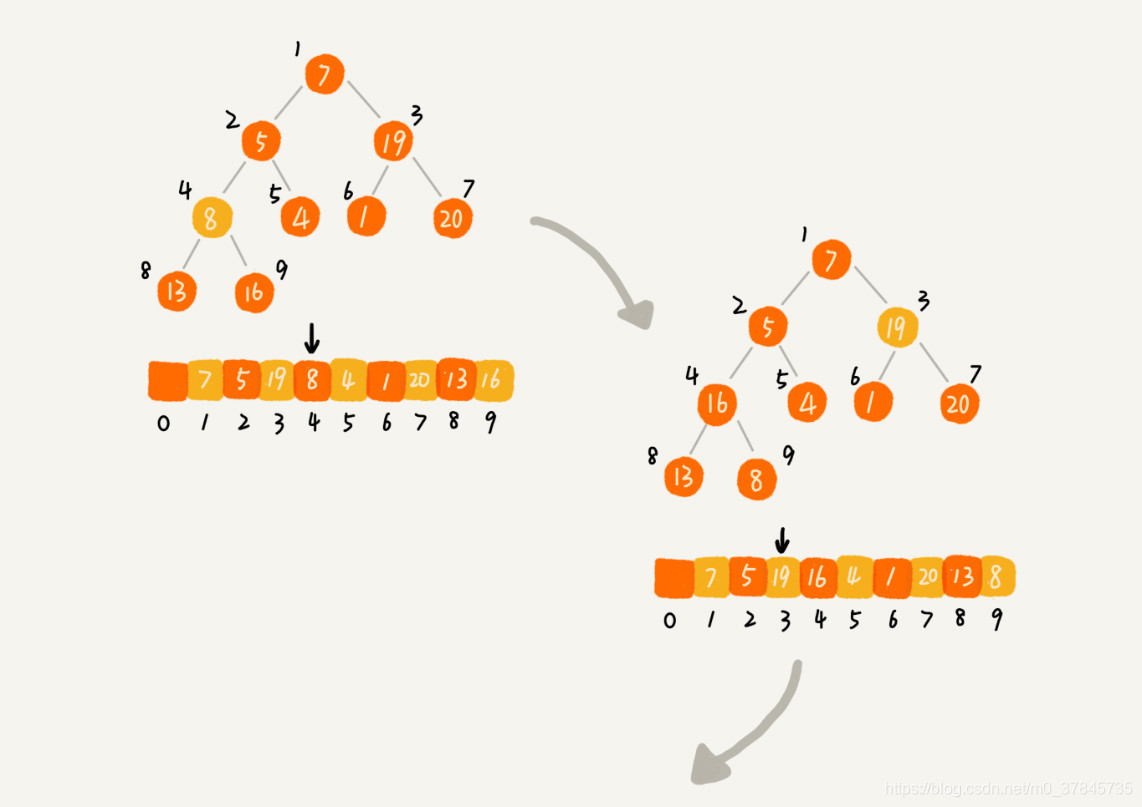
2、排序
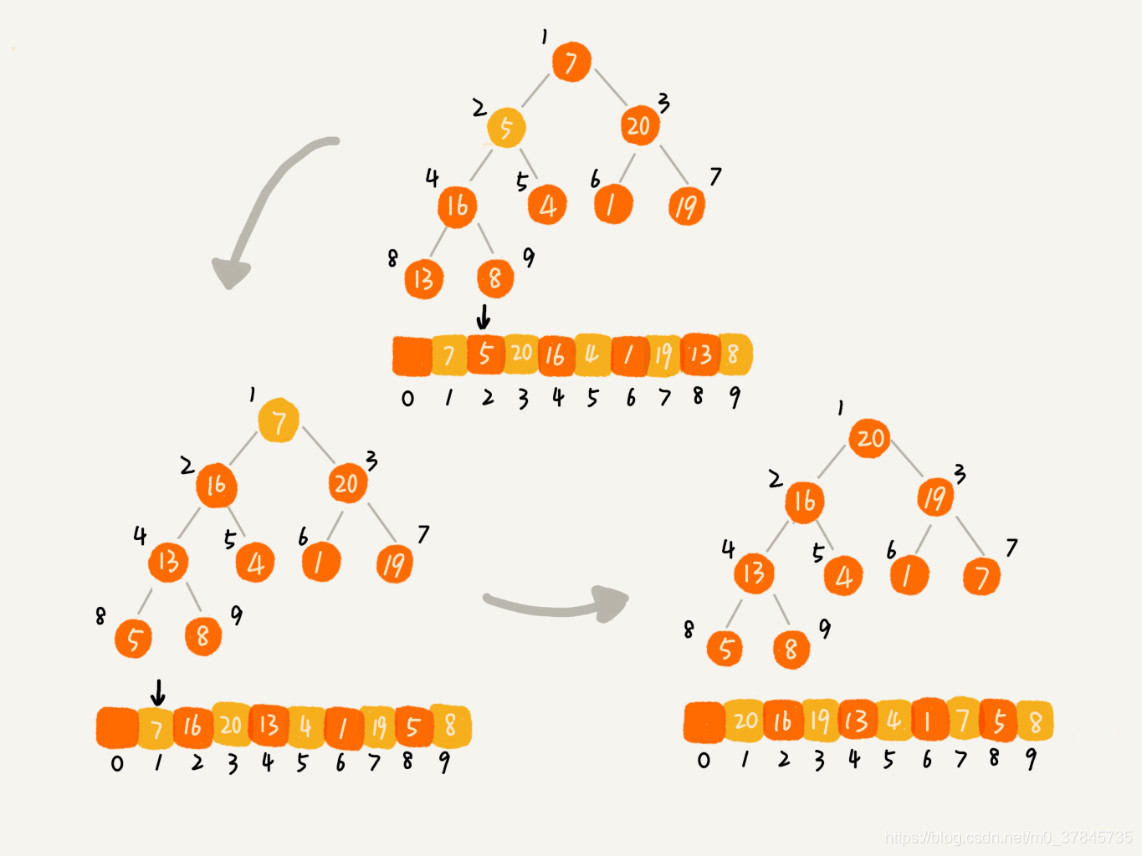
建堆结束之后,数组中的数据已经是按照大顶堆的特性来组织的。数组中的第一个元素就是堆顶,也就是最大的元素。我们把它跟最后一个元素交换,那最大元素就放到了下标为 n 的位置。然后再通过堆化的方法,将剩下的 n−1 个元素重新构建成堆。堆化完成之后,我们再取堆顶的元素,放到下标是 n−1 的位置,一直重复这个过程,直到最后堆中只剩下标为 1 的一个元素,排序工作就完成了
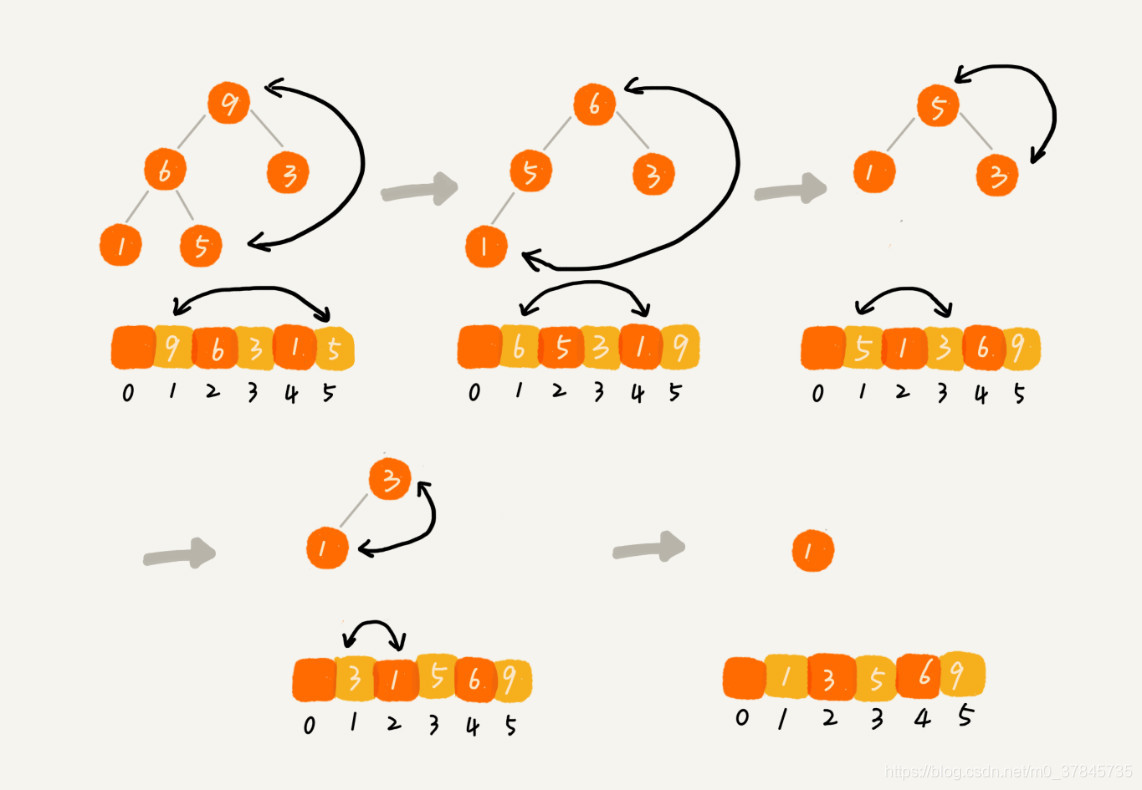
整个堆排序的过程,都只需要极个别临时存储空间,所以堆排序是原地排序算法。堆排序包括建堆和排序两个操作,建堆过程的时间复杂度是 O(n),排序过程的时间复杂度是 O(nlogn),所以,堆排序整体的时间复杂度是 O(nlogn)。
堆排序不是稳定的排序算法,因为在排序的过程,存在将堆的最后一个节点跟堆顶节点互换的操作,所以就有可能改变值相同数据的原始相对顺序。
2、优先级队列
优先级队列是一种特殊的队列,优先级高的数据先出队,而不再像普通的队列那样,先进先出。实际上,堆就可以看作优先级队列,只是称谓不一样罢了。
3、求 Top K
求 Top K 问题又可以分为针对静态数据和针对动态数据,只需要利用一个堆,就可以做到非常高效率的查询 Top K 的数据。
4、求中位数
求中位数实际上还有很多变形,比如求 99 百分位数据、90 百分位数据等,处理的思路都是一样的,即利用两个堆,一个大顶堆,一个小顶堆,随着数据的动态添加,动态调整两个堆中的数据,最后大顶堆的堆顶元素就是要求的数据。
四、堆C语言实现
1、数据结构
#define HEAP_MALLOC(size) pvPortMalloc(size);
#define HEAP_REALLOC(p,size) realloc(p,size);
#define HEAP_CALLOC(n,size) calloc(n,size);
#define HEAP_FREE(p) vPortFree(p);
#define HEAP_MAX_SIZE 100
struct heap_node;
struct heap;
/*
* 堆key比较, key_cmp:传入的要比较的key, key_becmp:被比较的key
* 任意一个节点,其左子树中任意一个节点的值,都要小于这个节点的值
* 任意一个几点,其右子数中任意一个节点的值,都要大于这个节点的值
* 返回值 > 0 : key_cmp > key_becmp
* 返回值 = 0 : key_cmp = key_becmp
* 返回值 < 0 : key_cmp < key_becmp
*/
typedef int (*heap_keycmp)(struct heap *heap, const void *key_cmp, const void *key_becmp);
/* 堆中的节点数据删除函数,如果插入节点为动态分配,则需要在该函数中释放节点空间 */
typedef int (*heap_value_free)(struct heap_node *node);
struct heap_node
{
void *key;
void *value;
};
struct heap
{
int num; /*堆中已经存储的元素个数*/
struct heap_node array[HEAP_MAX_SIZE]; /*堆*/
heap_keycmp keycmp; /*堆key比较*/
heap_value_free valuefree; /*堆节点数据删除*/
};
#define OFFSETOF(TYPE,MEMBER) ((unsigned int)&((TYPE *)0)->MEMBER)
#define container(ptr,type,member) ((type *) ((char *)ptr - OFFSETOF(type,member)))
2、操作函数声明
extern struct heap *heap_creat(heap_keycmp keycmp, heap_value_free valuefree);
extern struct heap *heap_creat_default(heap_value_free valuefree);
extern int heap_insert (struct heap *heap, void *key, void *value);
extern int heap_delete_max(struct heap *heap);
extern int heap_build (struct heap *heap);
extern int heap_sort (struct heap *heap);
extern void heap_empty (struct heap *heap);
extern void heap_destroy (struct heap **heap);
extern void heap_sample(void);3、具体实现
#include "algo_heap.h"
/**
* 堆key比较, key_cmp:传入的要比较的key, key_becmp:被比较的key
*
* @return > 0 : key_cmp > key_becmp
* @return = 0 : key_cmp = key_becmp
* @return < 0 : key_cmp < key_becmp
*
*/
static int heap_keycmp_default(struct heap *heap, const void *key_cmp, const void *key_becmp)
{
return strcmp(key_cmp, key_becmp);
}
/**
* 交换堆两个节点数据.
*
* @param array: 堆
* @param child: 节点下标
* @param father: 节点父节点下标
*/
static void heap_swap(struct heap_node *array, int child, int father)
{
struct heap_node temp;
temp = array[child];
array[child] = array[father];
array[father] = temp;
}
/**
* 大顶堆从上往下进行堆化
*
* @param array: 堆
*/
static void heapify(struct heap *heap, int start_pos)
{
int max_pos = start_pos;//根节点和2个子节点3个节点中最大的那个节点下标,从堆顶开始
while (1)
{
/*子节点没有超过堆范围 & 子节点比根节点大,则需要交换根节点和子节点位置并继续向下堆化*/
if ((start_pos * 2 + 1 < heap->num) && (heap->keycmp(heap, heap->array[start_pos].key,heap->array[start_pos * 2 + 1].key) < 0))
{
max_pos = start_pos * 2 + 1;
}
if ((start_pos * 2 + 2 < heap->num) && (heap->keycmp(heap, heap->array[max_pos].key,heap->array[start_pos * 2 + 2].key) < 0))
{
max_pos = start_pos * 2 + 2;
}
if (max_pos == start_pos) break;//最大节点下标没改变,说明跟节点就是最大的节点了,停止向下堆化
heap_swap(heap->array, max_pos, start_pos);
start_pos = max_pos;//继续向下堆化
}
}
/**
* 动态创建一个堆.
*
* @return NULL:创建失败
* !NULL:创建成功
*/
struct heap *heap_creat(heap_keycmp keycmp, heap_value_free valuefree)
{
struct heap *heap = NULL;
int i = 0;
if (keycmp == NULL)
return NULL;
/*申请堆结构空间,数组下标从0 - n-1*/
heap = HEAP_MALLOC(sizeof(*heap));
if (heap == NULL)
return NULL;
heap->keycmp = keycmp;
heap->valuefree = valuefree;
heap->num = 0;
for (i=0; i<HEAP_MAX_SIZE; i++)
{
heap->array[i].key = NULL;
heap->array[i].value = NULL;
}
return heap;
}
/**
* 使用默认 key比较函数 动态创建一个堆.
*
* @return NULL:创建失败
* !NULL:创建成功
*/
struct heap *heap_creat_default(heap_value_free valuefree)
{
return heap_creat(heap_keycmp_default, valuefree);
}
/**
* 向堆中插入一个节点.从下往上堆化
*
* @param heap: 堆
* @param key: 关键值
* @param value: 节点数据
*
* @return 0:插入成功
* -1:堆不存在 或 key为空 或 value为空
* -3:插入失败
*/
int heap_insert(struct heap *heap, void *key, void *value)
{
int n = 0;
if (heap == NULL || key == NULL || value == NULL)
return -1;
/*堆满了*/
if (heap->num >= HEAP_MAX_SIZE)
return -3;
heap->array[heap->num].key = key;//堆下标从0开始
heap->array[heap->num].value = value;
heap->num += 1;
/*1、从下往上进行堆化,(n/2 + 1) - n为叶子节点不需要堆化
*2、n/2节点为n节点的父节点,n节点为n/2节点的2个子节点
*3、子节点大于0,子节点比根节点值大,则继续向上堆化
*/
n = heap->num - 1;
while ( (n > 0) && (heap->keycmp(heap, heap->array[n].key, heap->array[(n - 1) / 2].key) > 0) )
{
heap_swap(heap->array, n, (n-1)/2);//交换节点与根节点数据
n = n / 2;//将下标指向根节点,继续向上堆化
}
return 0;
}
/**
* 大顶堆删除最大节点,从上往下堆化
*
* @param heap: 堆
*
* @return 0:删除成功
* -1:堆不存在
* -3:删除失败
*/
int heap_delete_max(struct heap *heap)
{
if (heap == NULL)
return -1;
/*堆中没有数据*/
if (heap->num < 1)
return -3;
heap->valuefree(&heap->array[0]);
heap->array[0] = heap->array[heap->num - 1];
heap->array[heap->num - 1].key = NULL;
heap->array[heap->num - 1].value = NULL;
heap->num --;
heapify(heap, 0);
return 0;
}
/**
* 对已有数据的堆进行堆化
*
* @param heap: 堆
*
* @return 0:建堆成功
* -1:堆不存在
* -3:堆中没有数据
*/
int heap_build(struct heap *heap)
{
int i = 0;
if (heap == NULL)
return -1;
/*堆中没有数据*/
if (heap->num < 1)
return -3;
for (i=heap->num/2 - 1; i >= 0; i--)
{
heapify(heap, i);
}
return 0;
}
/**
* 对已有数据的堆,对堆得数据进行从小到大排序
*
* @param heap: 堆
*
* @return 0:排序成功
* -1:堆不存在
* -3:堆中没有数据
*/
int heap_sort(struct heap *heap)
{
int num = heap->num;
if (heap == NULL)
return -1;
/*堆中没有数据*/
if (heap->num < 1)
return -3;
/*将堆顶数据放至数组最后,然后从堆顶开始堆化*/
while (heap->num > 1)
{
heap_swap(heap->array, heap->num - 1, 0);//将堆定元素放至数组最后
heap->num--;//元素个数减1,最后一个元素已经是最大的了不需要再参与堆化
heapify(heap,0);
}
heap->num = num;
return 0;
}
/**
* 清空堆中所有节点数据
*
* @param heap: 堆
*
* @return NULL
*/
void heap_empty(struct heap *heap)
{
if (heap == NULL || heap->num < 1)
return;
/*将堆顶数据放至数组最后,然后从堆顶开始堆化*/
for (; heap->num > 0; heap->num--)
{
heap->valuefree(&heap->array[heap->num - 1]);
heap->array[heap->num - 1].key = NULL;
heap->array[heap->num - 1].value = NULL;
}
}
/**
* 销毁堆
*
* @param heap: 堆
*
* @return NULL
*/
void heap_destroy(struct heap **heap)
{
heap_empty(*heap);
HEAP_FREE(*heap);
*heap = NULL;
}
/*******************************************************************************************
* 使用示例
*******************************************************************************************/
struct test_node
{
char key[10];
char value[10];
};
static int node_value_free_sample(struct heap_node *node)
{
struct test_node *node_temp = NULL;
/*根据key在test_node结构体中的偏移地址,找到二叉查找树节点实际指向的结构体首地址*/
node_temp = container(node->key, struct test_node, key);
/*如果节点所指向数据空间为动态申请的则需要释放*/
HEAP_FREE(node_temp);
/*将二叉树中指向这块内存的节点key 和 value 赋为空*/
node->key = NULL;
node->value = NULL;
return 0;
}
struct heap *heap_test = NULL;
char heap_node_read[10][10];
void heap_sample(void)
{
int i = 0, key[10] = {0};
struct test_node *node_temp = NULL;
heap_test = heap_creat_default(node_value_free_sample);
for (i=0; i<10; i++)
{
key[i] = rand() % 10;
}
/*插入 -- 查询*/
for (i=0; i<10; i++)
{
node_temp = HEAP_MALLOC(sizeof(*node_temp));
memset(node_temp, 0, sizeof(*node_temp));
sprintf(node_temp->key, "AAA%d", key[i]);
sprintf(node_temp->value, "%d", key[i]);
heap_insert(heap_test, node_temp->key, node_temp->value);
}
for (i=0; i<10; i++)
{
memset(heap_node_read[i], 0, 10);
memcpy(heap_node_read[i], heap_test->array[i].value, 10);
}
/*排序 -- 查询*/
heap_sort(heap_test);
for (i=0; i<10; i++)
{
memset(heap_node_read[i], 0, 10);
memcpy(heap_node_read[i], heap_test->array[i].value, 10);
}
/*建堆 -- 查询*/
heap_build(heap_test);
for (i=0; i<10; i++)
{
memset(heap_node_read[i], 0, 10);
memcpy(heap_node_read[i], heap_test->array[i].value, 10);
}
/*排序 -- 查询*/
heap_sort(heap_test);
for (i=0; i<10; i++)
{
memset(heap_node_read[i], 0, 10);
memcpy(heap_node_read[i], heap_test->array[i].value, 10);
}
/*清空 -- 插入 -- 查询*/
heap_empty(heap_test);
for (i=0; i<10; i++)
{
node_temp = HEAP_MALLOC(sizeof(*node_temp));
memset(node_temp, 0, sizeof(*node_temp));
sprintf(node_temp->key, "AAA%d", key[i]);
sprintf(node_temp->value, "%d", key[i] + 10);
heap_insert(heap_test, node_temp->key, node_temp->value);
}
for (i=0; i<10; i++)
{
memset(heap_node_read[i], 0, 10);
memcpy(heap_node_read[i], heap_test->array[i].value, 10);
}
/*删除最大 -- 查询*/
heap_delete_max(heap_test);
for (i=0; i<10; i++)
{
memset(heap_node_read[i], 0, 10);
memcpy(heap_node_read[i], heap_test->array[i].value, 10);
}
heap_destroy(&heap_test);
}4、调试问题
1、堆中元素是从数组下标 0 开始存储的,对于下标为 i 的节点,其父节点下标为:(i - 1) / 2,左节点下标为:2i + 1,右节点下标为: 2i + 2
2、数组下标与数组元素个数的关系:下标 + 1 = 个数,在堆句柄中有一个num字段,表示的是当前堆中元素的个数,所以对于第num个元素,其下标为:num - 1,其父节点下标为:num / 2 - 1,左节点下标为:2num - 1,右节点下标为: 2num
五、说明
本文部分内容(图片与部分文字)为学习王争老师在极客时间专栏——《数据结构与算法之美》的学习总结。仅仅是个人学习备忘,如有侵犯权益,请联系我,立即修改。














 2894
2894











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









