







一、常见激活函数总结
激活函数: 就是在神经网络的神经元上运行的函数,负责将神经元的输入映射到输出端。
常见的激活函数包括
- Sigmoid
- TanHyperbolic(tanh)
- ReLu
- softplus
- softmax
- ELU
- PReLU
这些函数有一个共同的特点那就是他们都是非线性的函数。那么我们为什么要在神经网络中引入非线性的激活函数呢?
如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层输出都是上层输入的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了。 正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)。最早的想法是sigmoid函数或者tanh函数,输出有界,很容易充当下一层输入(以及一些人的生物解释balabala)。
1.Sigmoid函数
Sigmoid函数的表达式为
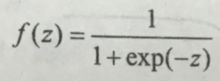
导数为:
![]()
函数曲线如下图所示:
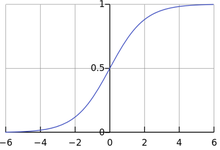
Sigmoid函数是传统神经网络中最常用的激活函数,一度被视为神经网络的核心所在。
从数学上来看,Sigmoid函数对中央区的信号增益较大,对两侧区的信号增益小,在信号的特征空间映射上,有很好的效果。从神经科学上来看,中央区酷似神经元的兴奋态,两侧区酷似神经元的抑制态,因而在神经网络学习方面,可以将重点特征推向中央区,将非重点特征推向两侧区。
在sigmod函数中我们可以看到,其输出是在(0,1)这个开区间内,这点很有意思,可以联想到概率,但是严格意义上讲,不要当成概率。sigmod函数曾经是比较流行的,它可以想象成一个神经元的放电率,在中间斜率比较大的地方是神经元的敏感区,在两边斜率很平缓的地方是神经元的抑制区。
当然,流行也是曾经流行,这说明函数本身是有一定的缺陷的。
1) 当输入稍微远离了坐标原点,函数的梯度就变得很小了,几乎为零。在神经网络反向传播的过程中,我们都是通过微分的链式法则来计算各个权重w的微分的。当反向传播经过了sigmod函数,这个链条上的微分就很小很小了,况且还可能经过很多个sigmod函数,最后会导致权重w对损失函数几乎没影响,这样不利于权重的优化,这个问题叫做梯度饱和,也可以叫梯度弥散。
2) 函数输出不是以0为中心的,这样会使权重更新效率降低。对于这个缺陷,在斯坦福的课程里面有详细的解释。
3) sigmod函数要进行指数运算,这个对于计算机来说是比较慢的。
对比sigmoid类函数主要变化是:
1)单侧抑制
2)相对宽阔的兴奋边界
3)稀疏激活性
Sigmoid 和 Softmax 区别:
sigmoid将一个real value映射到(0,1)的区间,用来做二分类。而 softmax 把一个 k 维的real value向量(a1,a2,a3,a4….)映射成一个(b1,b2,b3,b4….)其中 bi 是一个 0~1 的常数,输出神经元之和为 1.0,所以相当于概率值,然后可以根据 bi 的概率大小来进行多分类的任务。二分类问题时 sigmoid 和 softmax 是一样的,求的都是 cross entropy loss,而 softmax 可以用于多分类问题多个logistic回归通过叠加也同样可以实现多分类的效果,但是 softmax回归进行的多分类,类与类之间是互斥的,即一个输入只能被归为一类;多个logistic回归进行多分类,输出的类别并不是互斥的,即"苹果"这个词语既属于"水果"类也属于"3C"类别。
2.TanHyperbolic(tanh)函数
TanHyperbolic(tanh)函数又称作双曲正切函数,数学表达式为
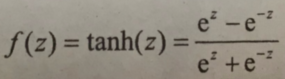
导数为:
![]()
图像为:
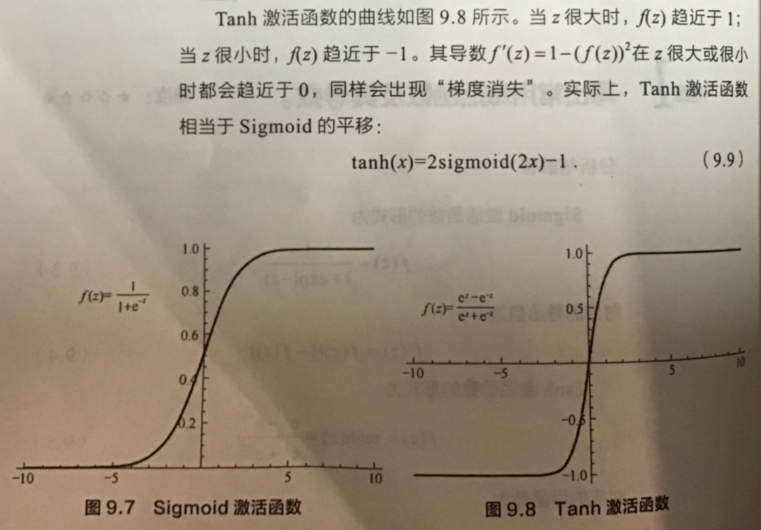
在具体应用中,tanh函数相比于Sigmoid函数往往更具有优越性,这主要是因为Sigmoid函数在输入处于[-1,1]之间时,函数值变化敏感,一旦接近或者超出区间就失去敏感性,处于饱和状态,影响神经网络预测的精度值。而tanh的输出和输入能够保持非线性单调上升和下降关系,符合BP网络的梯度求解,容错性好,有界,渐进于0、1,符合人脑神经饱和的规律,但比sigmoid函数延迟了饱和期.tanh在特征相差明显时的效果会很好,在循环过程中会不断扩大特征效果。与 sigmoid 的区别是,tanh 是 0 均值的,因此实际应用中 tanh 会比 sigmoid 更好。
tanh是双曲正切函数,tanh函数和sigmod函数的曲线是比较相近的,咱们来比较一下看看。首先相同的是,这两个函数在输入很大或是很小的时候,输出都几乎平滑,梯度很小,不利于权重更新;不同的是输出区间,tanh的输出区间是在(-1,1)之间,而且整个函数是以0为中心的,这个特点比sigmod的好。
一般二分类问题中,隐藏层用tanh函数,输出层用sigmod函数。不过这些也都不是一成不变的,具体使用什么激活函数,还是要根据具体的问题来具体分析,还是要靠调试的。
3.ReLu函数
ReLu函数的全称为Rectified Linear Units
函数表达式为:
![]()
导数为:
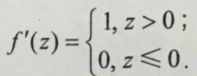
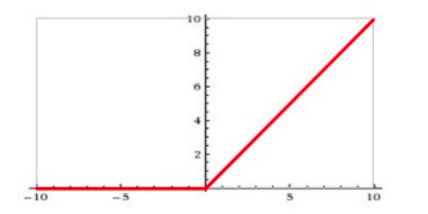
ReLU(Rectified Linear Unit)函数是目前比较火的一个激活函数,相比于sigmod函数和tanh函数,它有以下几个优点:
1) 在输入为正数的时候,不存在梯度饱和问题。
2) 计算速度要快很多。ReLU函数只有线性关系,不管是前向传播还是反向传播,都比sigmod和tanh要快很多。(sigmod和tanh要计算指数,计算速度会比较慢)
当然,缺点也是有的:
1) 当输入是负数的时候,ReLU是完全不被激活的,这就表明一旦输入到了负数,ReLU就会死掉。这样在前向传播过程中,还不算什么问题,有的区域是敏感的,有的是不敏感的。但是到了反向传播过程中,输入负数,梯度就会完全到0,这个和sigmod函数、tanh函数有一样的问题。
2) 我们发现ReLU函数的输出要么是0,要么是正数,这也就是说,ReLU函数也不是以0为中心的函数。
Sigmoid ,tanh与ReLU 比较:
sigmoid,tanh 会出现梯度消失问题,ReLU 的导数就不存在这样的问题。
优点:
(1)从计算的角度上,Sigmoid和Tanh激活函数均需要计算指数,复杂度高,而ReLU只需要一个阈值即可得到激活值;
(2)ReLU的非饱和性溃疡有效地解决梯度消失的问题,提供相对宽的激活边界;
(3)ReLU的单侧抑制提供了网络的稀疏表达能力
缺点:
训练过程中会导致神经元死亡的问题。这是由于函数f(z)=max(0,z)导致负梯度在经过该ReLU单元时被置为0,且在之后也不被任何数据激活,即流经该神经元的梯度永远为0,不对任何数据产生响应。
在实际训练中,如果学习率设置较大,会导致一定比例的神经元不可逆死亡,进而参数梯度无法更新,整个训练过程失败。
第一个问题:为什么引入非线性激励函数?
如果不用激励函数(其实相当于激励函数是f(x) = x),在这种情况下你每一层输出都是上层输入的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(Perceptron)了。
正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络就有意义了(不再是输入的线性组合,可以逼近任意函数)。最早的想法是sigmoid函数或者tanh函数,输出有界,很容易充当下一层输入(以及一些人的生物解释balabala)。
第二个问题:为什么引入Relu呢?
第一,采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
第二,对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失,参见 @Haofeng Li 答案的第三点),从而无法完成深层网络的训练。
第三,Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生(以及一些人的生物解释balabala)。
当然现在也有一些对relu的改进,比如prelu,random relu等,在不同的数据集上会有一些训练速度上或者准确率上的改进,具体的大家可以找相关的paper看。
多加一句,现在主流的做法,会在做完relu之后,加一步batch normalization,尽可能保证每一层网络的输入具有相同的分布[1]。而最新的paper[2],他们在加入bypass connection之后,发现改变batch normalization的位置会有更好的效果。大家有兴趣可以看下。


relu引起神经元“死亡”的问题
在对比各种非线性激活函数的时候,大量的文章对于relu的缺陷,只是简单的描述一下,当有大梯度流经某个神经元后,容易导致神经元进入“死亡”状态,对其它梯度不敏感。这里面的原理不知道是怎么回事
答:
如果梯度太大,而学习率又不小心设置得太大,就会导致权重一下子更新过多,(从而导致下一次输出为小于0的数字),就有可能出现这种情况:对于任意训练样本 ,网络的输出都是小于0的,神经元死亡


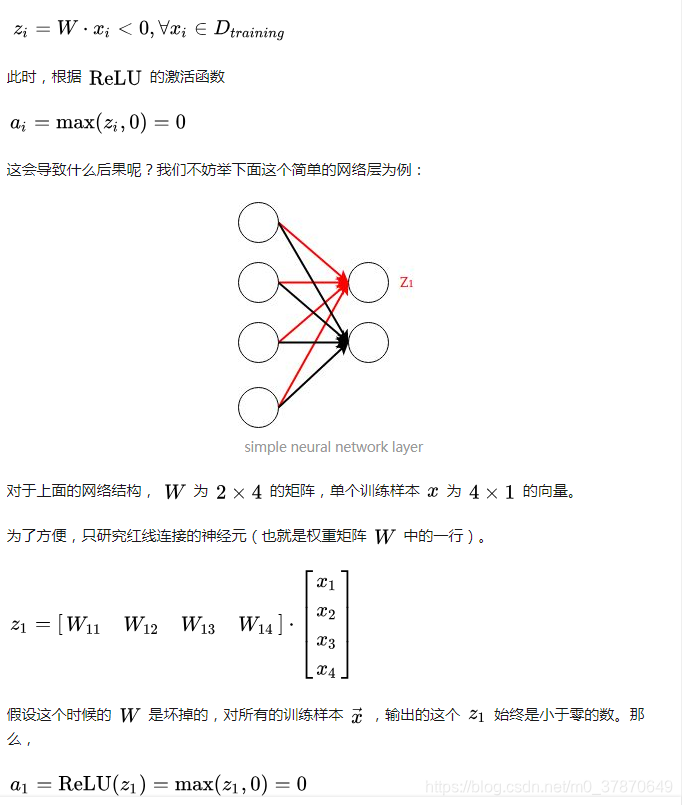

4.softplus函数
softplus函数的数学表达式为: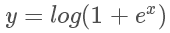
ReLu和softplus的函数曲线如下: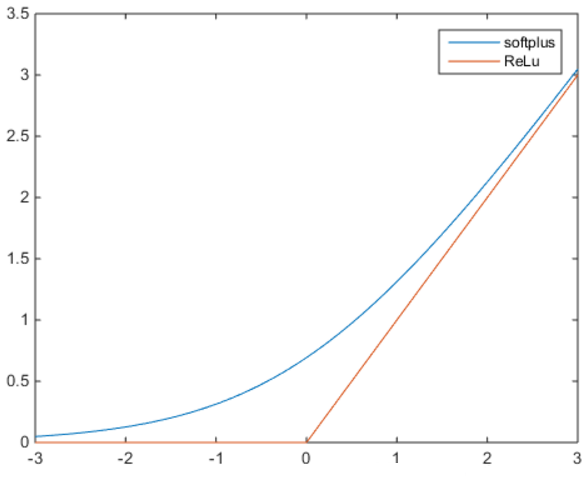
可以看到,softplus可以看作是ReLu的平滑。根据神经科学家的相关研究,softplus和ReLu与脑神经元激活频率函数有神似的地方。也就是说,相比于早期的激活函数,softplus和ReLu更加接近脑神经元的激活模型,
而神经网络正是基于脑神经科学发展而来,这两个激活函数的应用促成了神经网络研究的新浪潮。
softplus和ReLu相比于Sigmoid的优点在哪里呢?
- 采用sigmoid等函数,算激活函数时(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相对大,而采用Relu激活函数,整个过程的计算量节省很多。
- 对于深层网络,sigmoid函数反向传播时,很容易就会出现梯度消失的情况(在sigmoid接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失),从而无法完成深层网络的训练。
- Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生(以及一些人的生物解释balabala)。
5.softmax函数
Sigmoid函数如果用来分类的话,只能进行二分类,而这里的softmax函数可以看做是Sigmoid函数的一般化,可以进行多分类。softmax函数的函数表达式为:
![]()
从公式中可以看出,就是如果某一个Zj大过其他z,那这个映射的分量就逼近于1,其他就逼近于0,即用于多分类。也可以理解为将K维向量映射为另外一种K维向量。用通信的术语来讲,如果Sigmoid函数是MISO,Softmax就是MIMO的Sigmoid函数。
二分类和多分类其实没有多少区别。用的公式仍然是y=wx + b。 但有一个非常大的区别是他们用的激活函数是不同的。 逻辑回归用的是sigmoid,这个激活函数的除了给函数增加非线性之外还会把最后的预测值转换成在【0,1】中的数据值。也就是预测值是0<y<1。 我们可以把最后的这个预测值当做是一个预测为正例的概率。在进行模型应用的时候我们会设置一个阈值,当预测值大于这个阈值的时候,我们判定为正例子,反之我们判断为负例。这样我们可以很好的进行二分类问题。 而多分类中我们用的激活函数是softmax。 为了能够比较好的解释它,我们来说一个例子。 假设我们有一个图片识别的4分类的场景。 我们想从图片中识别毛,狗,鸡和其他这4种类别。那么我们的神经网络就变成下面这个样子的。
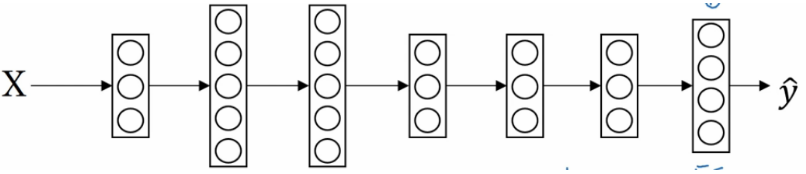
我们最后的一层中使用的激活函数就是softmax。 我们发现跟二分类在输出层之后一个单元不同的是, 使用softmax的输出层拥有多个单元,实际上我们有多少个分类就会有多少个单元,在这个例子中,我们有4个分类,所以也就有4个神经单元,它们代表了这4个分类。在softmax的作用下每个神经单元都会计算出当前样本属于本类的概率。如下:
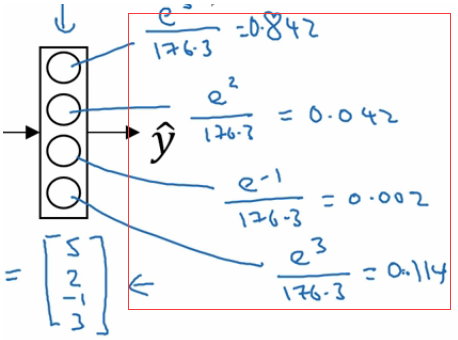
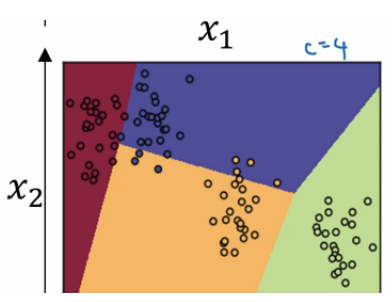
如上图,该样本属于第一个分类的概率是0.842, 属于第二个分类的概率是0.042,属于第三个分类的概率是0.002,属于第四个分类的概率是0.114. 我们发现这些值相加等于一,因为这些值也是经过归一化的结果。 整个效果图可以参考下面的例子, 这是一个比较直观的图。
Softmax的损失函数
既然softmax的输出变成了多个值,那么我们如何计算它的损失函数呢, 有了损失函数我们才能进行梯度下降迭代并根据前向传播和反向传播进行学习。如下图:
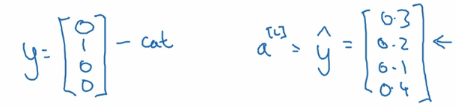
还是假设有4个分类,那么实际的预测向量,也会有4个维度。 如上图左边的样子。 如果是属于第二个分类,那么第二个值就是1, 其他值都是0。 假设右边的向量是预测值, 每个分类都有一个预测概率。 那么我们的损失函数就是。
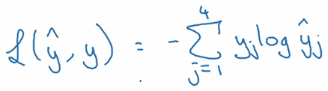
由于实际值得向量只有一个是1,其他的都是0. 所以其实到了最后的函数是下面这个样子的
![]()
有了损失函数,我们就可以跟以前做逻辑回归一样做梯度下降就可以了。
softmax的梯度求解
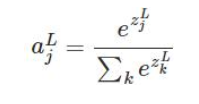

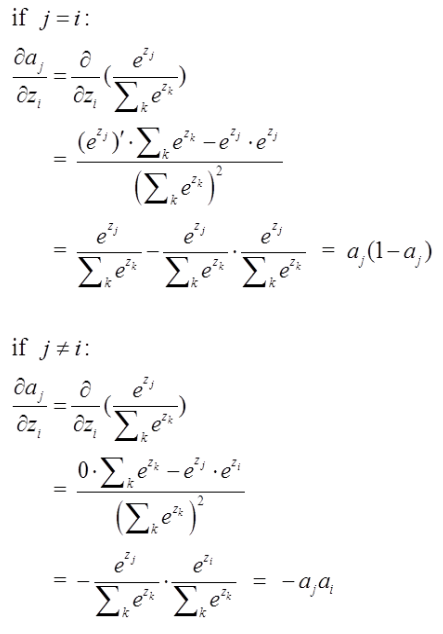
6.ELU函数
ELU函数公式和曲线如下图


ELU函数是针对ReLU函数的一个改进型,相比于ReLU函数,在输入为负数的情况下,是有一定的输出的,而且这部分输出还具有一定的抗干扰能力。这样可以消除ReLU死掉的问题,不过还是有梯度饱和和指数运算的问题。
7.PReLU函数
PReLU函数公式和曲线如下图


PReLU也是针对ReLU的一个改进型,在负数区域内,PReLU有一个很小的斜率,这样也可以避免ReLU死掉的问题。相比于ELU,PReLU在负数区域内是线性运算,斜率虽然小,但是不会趋于0,这算是一定的优势吧。
我们看PReLU的公式,里面的参数α一般是取0~1之间的数,而且一般还是比较小的,如零点零几。当α=0.01时,我们叫PReLU为Leaky ReLU,算是PReLU的一种特殊情况吧。
8.Leaky ReLU

9.SELU(李弘毅老师讲解)
- 形式

其中超参 α 和 λ 的值是 证明得到 的(而非训练学习得到):
α= 1.6732632423543772848170429916717λ= 1.0507009873554804934193349852946
- 特点

即:
-
不存在死区
-
存在饱和区(负无穷时, 趋于 -
αλ) -
输入大于零时,激活输出对输入进行了放大
-
证明

记输入 [ a1..ak...aK] 各维独立同分布, 每一维的分布均值为零,方差为 1, 注意: 该分部不一定是高斯分布,只需满足均值为零,方差为 1 即可。
我们的目标是: 寻找一个激活函数,使得神经元输出的激活值 a 也满足均值为零,方差为 1.
后续的证明视频里跳过去了,很遗憾。

根据 ppt 得出一个不严谨的观察:为了满足输出 a 符合 均值为 0, 标准差为 1 , 权重向量 [w1, w2,...wk, wK] 需满足均值为 0, 标准差为 1/K.
相关参考:
https://www.cnblogs.com/nxf-rabbit75/p/9276412.html
二、激活函数实验
老师搭了一个包含 50 层隐含层的全连接网络。
input不做标准化 +relu函数

训练 3 个 epoch 后, 发现准确率没有提升。

input不做标准化 +selu函数

keras 已内建 selu 函数 ,训练 3 个 epoch 后, 发现准确率依然没有明显提升(只比 relu 好一点)。

input标准化 +selu函数
使用 selu 时,我们假设上一层的神经元输出符合均值为 0 , 方差为 1 的分布 ,所以需要将输入进行标准化。

训练 3 个 epoch 后, 发现网络仍然没有 train 起来:

weight标准化 +selu函数
前面我们有一个不严谨的观察 : 权重需要满足均值为零,方差为 1/K, 在训练过程中我们无法保证权重满足这一条件, 但是我们可以让初始化时的权重满足这一条件,使用 lecunNorm 即可。

训练 3 个 epoch 后, 发现效果惊人!

weight标准化 +relu函数
我们可能有疑问: 训练效果的提升可能应该归功于 lecunNorm, 而非 selu, 所以老师做了一组对照实验:

训练 3 个 epoch 后, 发现网络没有 train 起来。说明 selu + weight lecunNorm 才是真正的大杀器!!(李老师上课真的非常逗比)

Pytorch 实现 SELU
实现链接:【戳我】
import torch.nn.functional as F
def selu(x):
alpha = 1.6732632423543772848170429916717
scale = 1.0507009873554804934193349852946
return scale * F.elu(x, alpha)相关参考:
https://www.jianshu.com/p/3a43a6a860ef

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









