







该文章仅用于技术讨论,若有侵权,联系作者删除。
目标是输入一个IP地址后,获取查IP网(http://chaipip.com/ip.php)的查询结果。正常使用我们发现——流程是输入IP地址——进行滑动验证码验证后查询——跳转一个新的窗口——获取新窗口的查询结果。
我们先来看一下最后的流程和结果。

接下来,我们就一步一步讨论如何解决。
一、输入IP地址
第一步时清除输入框中的IP地址,然后输入要查询的地址。并点击验证码按钮,出现滑动式验证码以便进行下一步操作。
#输入数据
def input_message():
browser.get(url)
ip_put = wait.until(EC.presence_of_element_located((By.ID, 'ip')))
ip_put.clear()
ip_put.send_keys(ip)
click_btn=wait.until(EC.presence_of_element_located((By.ID,'embed-captcha')))
#随机延时点击
time.sleep(random.random()*3)
click_btn.click()二、进行滑动验证码验证
此处的思路是将滑动验证码的完整图片、有缺口的图片和缺口图片截取出来,通过比对后发现需要移动的距离后,用selenium模拟用户拖动。
#设置元素的可见性用于截图
def show_element(element):
browser.execute_script("arguments[0].style = arguments[1]", element, "display: block;")
def hide_element(element):
browser.execute_script("arguments[0].style = arguments[1]", element, "display: none;")
#截图
def save_pic(obj, name):
try:
pic_url = browser.save_screenshot('.\\ipaddress.png')
#开始获取元素位置信息
left = obj.location['x']
top = obj.location['y']
right = left + obj.size['width']
bottom = top + obj.size['height']
im = Image.open('.\\ipaddress.png')
im = im.crop((left, top, right, bottom))
file_name = 'ipaddress_' + name + '.png'
im.save(file_name)
except BaseException as msg:
print("截图失败:%s" % msg)
def cut():
c_background = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, 'canvas.geetest_canvas_bg.geetest_absolute')))
c_slice = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'canvas.geetest_canvas_slice.geetest_absolute')))
c_full_bg = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'canvas.geetest_canvas_fullbg.geetest_fade.geetest_absolute')))
hide_element(c_slice)
save_pic(c_background, 'back')
show_element(c_slice)
save_pic(c_slice, 'slice')
show_element(c_full_bg)
save_pic(c_full_bg, 'full')
#判断元素是否相同
def is_pixel_equal(bg_image, fullbg_image, x, y):
#bg_image是缺口的图片
#fullbg_image是完整图片
bg_pixel = bg_image.load()[x, y]
fullbg_pixel = fullbg_image.load()[x, y]
threshold = 60
if (abs(bg_pixel[0] - fullbg_pixel[0] < threshold) and abs(bg_pixel[1] - fullbg_pixel[1] < threshold) and abs(bg_pixel[2] - fullbg_pixel[2] < threshold)):
return True
else:
return False
#计算滑块移动的距离
def get_distance(bg_image, fullbg_image):
distance = 57
for i in range(distance, fullbg_image.size[0]):
for j in range(fullbg_image.size[1]):
if not is_pixel_equal(fullbg_image, bg_image, i, j):
return i
#构造滑动轨迹
def get_trace(distance):
#distance是缺口离滑块的距离
trace = []
faster_distance = distance*(4/5)
start, v0, t = 0, 0, 0.3
while start < distance:
if start < faster_distance:
a = 1.5
else:
a = -3
move = v0 * t + 1 / 2 * a * t * t
v = v0 + a * t
v0 = v
start += move
trace.append(round(move))
return trace
#模拟拖动
def move_to_gap(trace):
slider=wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'div.geetest_slider_button')))
# 使用click_and_hold()方法悬停在滑块上,perform()方法用于执行
ActionChains(browser).click_and_hold(slider).perform()
for x in trace:
# 使用move_by_offset()方法拖动滑块,perform()方法用于执行
ActionChains(browser).move_by_offset(xoffset=x, yoffset=0).perform()
time.sleep(0.5)
ActionChains(browser).release().perform()
def slide():
distance=get_distance(Image.open('.\\ipaddress_back.png'),Image.open('.\\ipaddress_full.png'))
trace = get_trace(distance-5)
move_to_gap(trace)
time.sleep(1)三、查询
此处就直接获取查询按钮的id,然后用click方法进行模拟点击操作。
#登录
def login():
login_btn=wait.until(EC.presence_of_element_located((By.ID,'embed-submit')))
#passwd.send_keys(Keys.ENTER)
login_btn.click()四、跳转至新的窗口,并获取查询结果
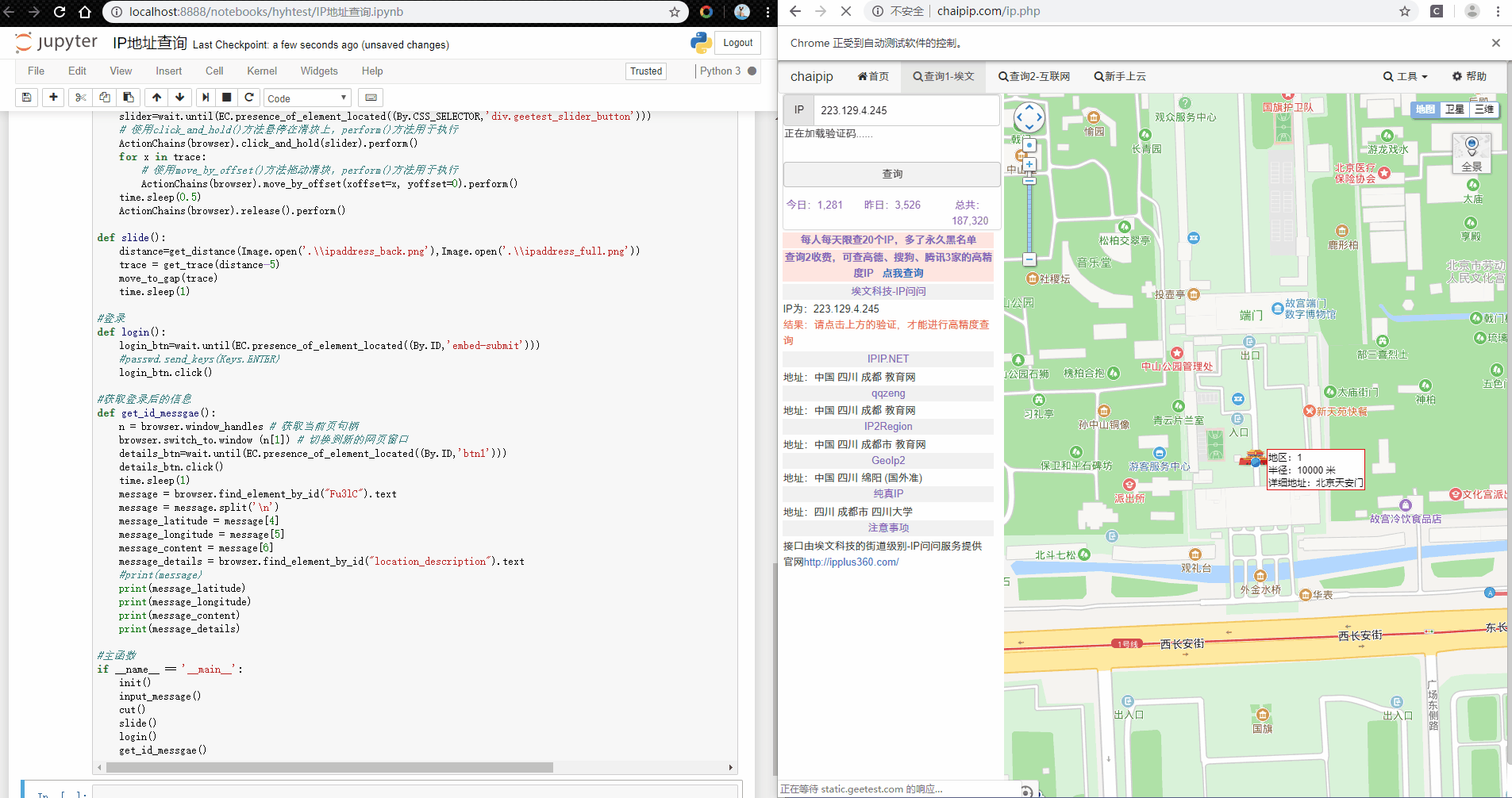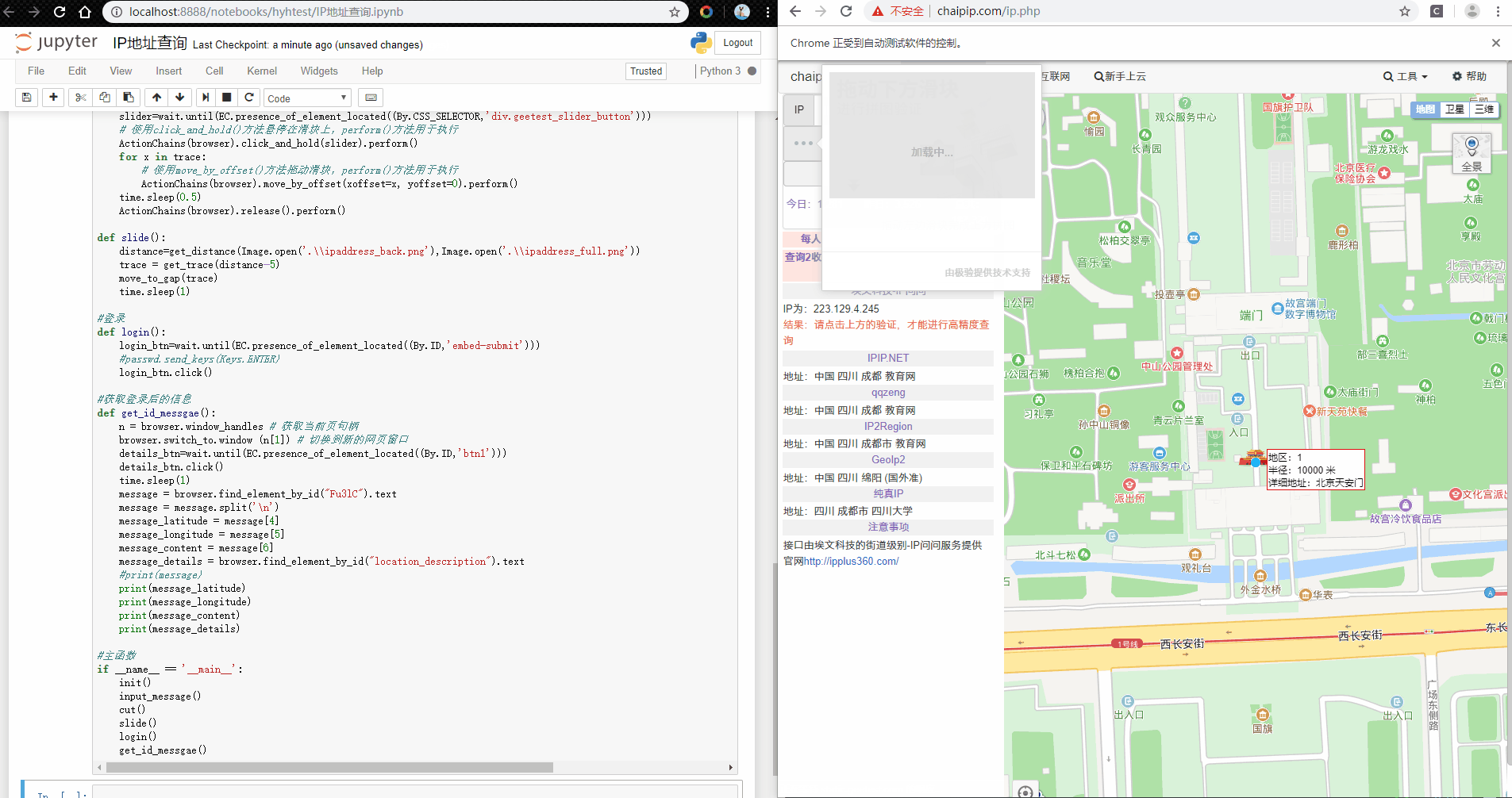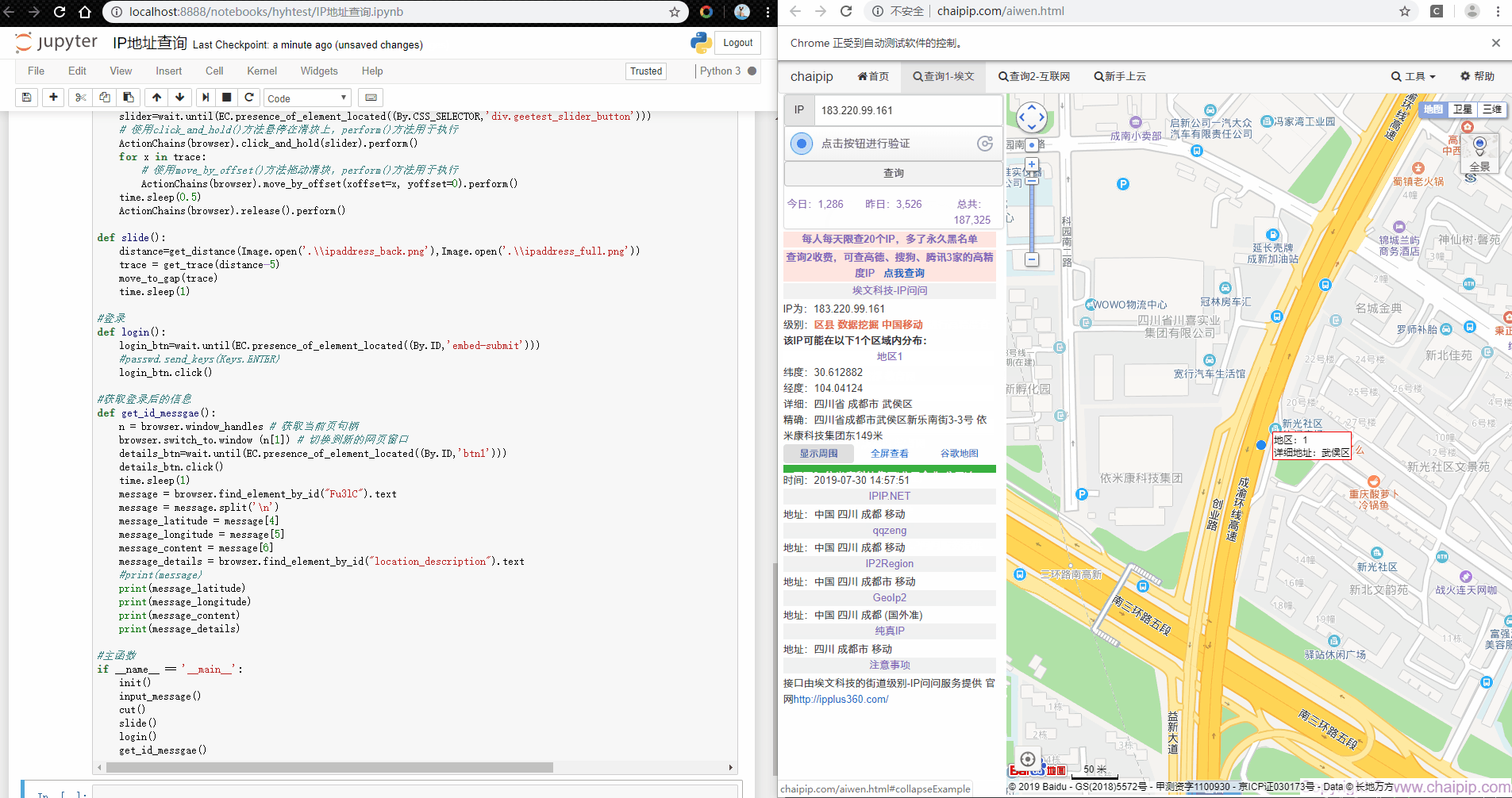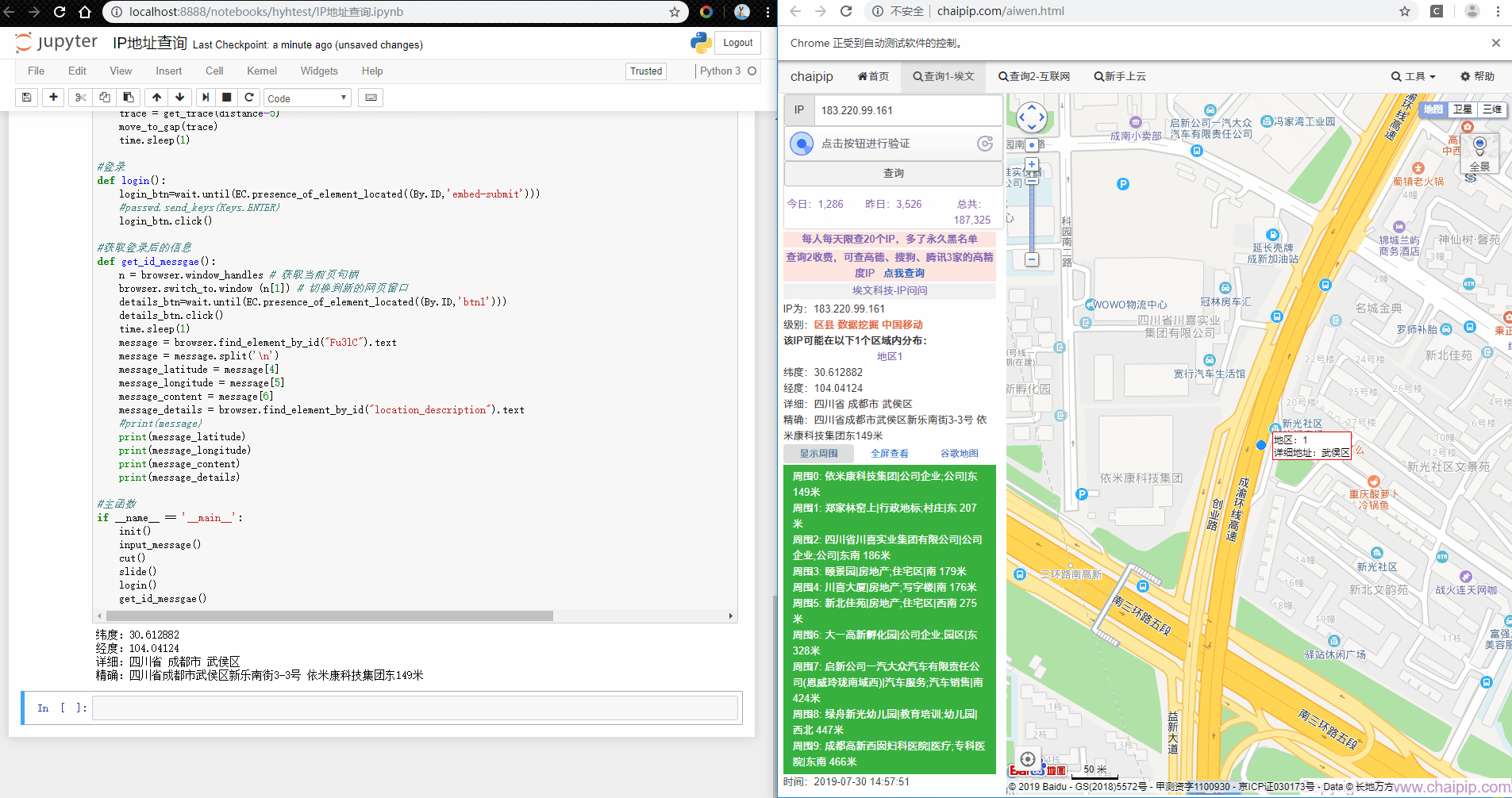
首先要做的是窗口跳转了,要将selenium操作的页面定位到新窗口。此处用到的是句柄,每个窗口都要自己的句柄,通过获取所有句柄后,判断并转入新窗口进行操作。其次就是获取IP地址的查询结果,由于详细信息需要点击查看周围的按钮,所以我们先模拟点击后,再获取相应的值。
#获取登录后的信息
def get_id_messgae():
n = browser.window_handles # 获取当前页句柄
browser.switch_to.window (n[1]) # 切换到新的网页窗口
details_btn=wait.until(EC.presence_of_element_located((By.ID,'btn1')))
details_btn.click()
time.sleep(1)
message = browser.find_element_by_id("Fu3lC").text
message = message.split('\n')
message_latitude = message[4]
message_longitude = message[5]
message_content = message[6]
message_details = browser.find_element_by_id("location_description").text
#print(message)
print(message_latitude)
print(message_longitude)
print(message_content)
print(message_details)到此处,整个功能就已经完成了。但是由于该网址对于同一个用户ID每天只能查20个IP地址,所以想通过这个办法进行大规模数据查询是不可能的。由于使用selenium网页的加载速度本来就慢,再使用代理IP的话只会更慢。这也是一个弊端,目前笔者还没有很好的解决办法。















 666
666











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









