







 本文介绍了一种爬取国内医院基本信息的方法,通过Python的requests和BeautifulSoup库,按省份存储医院列表,包括医院名称、地址、联系电话等详细信息。
本文介绍了一种爬取国内医院基本信息的方法,通过Python的requests和BeautifulSoup库,按省份存储医院列表,包括医院名称、地址、联系电话等详细信息。
本博客仅用于技术讨论,若有侵权,联系笔者删除。
此次的目的是爬取国内医院的基本信息,并按省份存储。爬取的黄页是医院列表。以下是结果图:

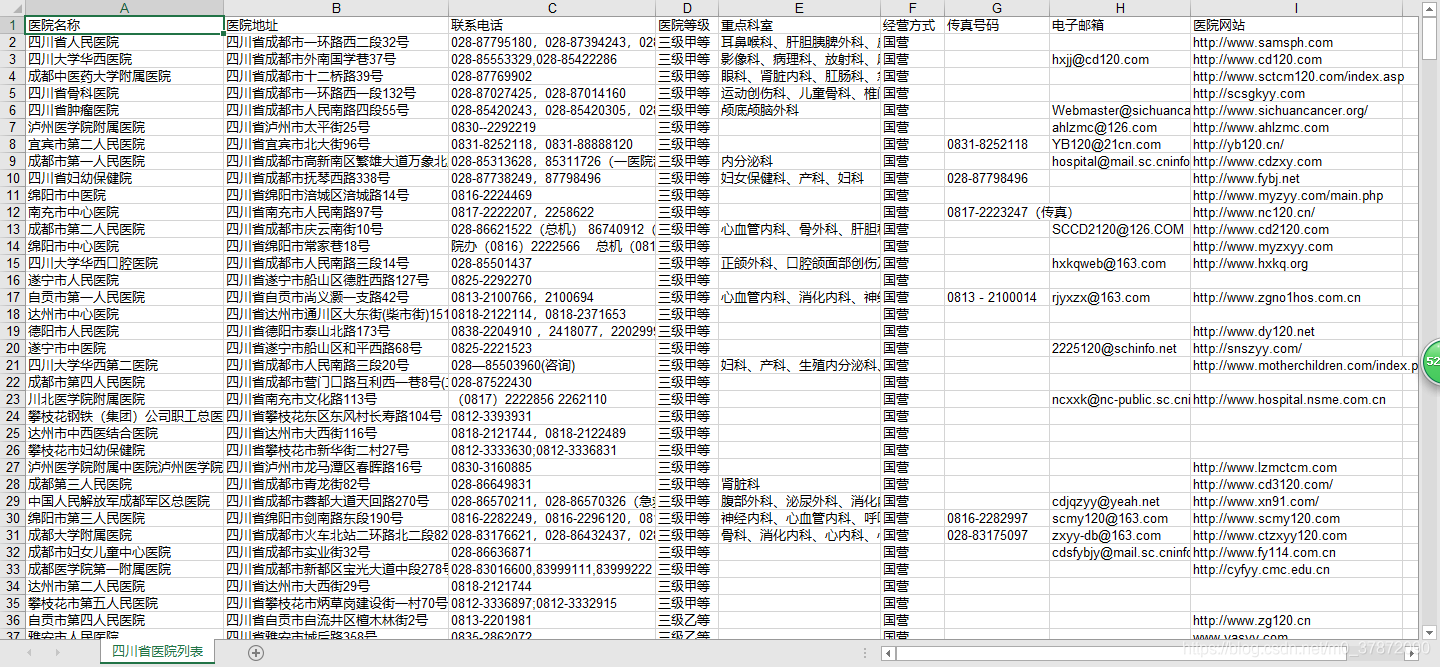
一、初始化数据
初始化基本的数据,包括global变量,省份名称等等。
import requests,re,xlwt,datetime
from bs4 import BeautifulSoup
#初始化
def init():
global url, province_name, headers
url = 'http://www.yixue.com/'
province_name = [
'北京市', '天津市', '河北省', '山西省', '辽宁省', '吉林省', '黑龙江省', '上海市',
'江苏省', '浙江省', '安徽省', '福建省', '江西省', '山东省', '河南省', '湖北省',
'湖南省', '广东省', '内蒙古自治区', '广西壮族自治区', '海南省', '重庆市', '四川省', '贵州省',
'云南省', '西藏自治区', '陕西省', '甘肃省', '青海省', '宁夏回族自治区', '新疆维吾尔自治区'
]
headers = {
'Host':'www.yixue.com',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36'
}二、#获取当前省数据并存入
由于这次的爬虫数据,对于需要的数据都无法通过ID或者CLASS定位,笔者就采用BeautifulSoup中的节点树,通过标签去获取对应信息。另外,由于聘爬虫的数据在规则中具有不规则性,所以对于每一项数据都进行验证,判断数据类型后再存入表中的对应位置。
存储数据
def sav_message(messgae, province_now):
workbook = xlwt.Workbook(encoding='utf-8')
name = province_now + "医院列表"
table=workbook.add_sheet(name)
value=["医院名称", "医院地址", "联系电话", "医院等级", "重点科室", "经营方式", "传真号码", "电子邮箱", "医院网站"]
for i in range(len(value)):
table.write(0,i,value[i])
i = 0
for data in messgae[3]:
table.write(i+1, 0, data.b.a.text)
for data_1 in data.ul:
now_mess = data_1.text.replace('\n', '')
now_data = now_mess.split(':')
count = 0
for tittle in value:
if tittle == now_data[0]:
index = count
count = count + 1
table.write(i+1, index, now_data[1])
i = i + 1
workbook.save('./医院信息爬虫数据/'+province_now+'医院列表.xls')
#获取当前省数据
def get_province_hospital(province_now):
r = requests.get(url+province_now+'医院列表',headers=headers,timeout=10)
soup = BeautifulSoup(r.text, "lxml")
message = soup.find_all('ul')
sav_message(message, province_now)三、主函数
主函数则负责整个逻辑,包括对各省的循环操作。
#主函数
if __name__ == '__main__':
init()
for province in province_name:
get_province_hospital(province)

















 922
922

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









