







一、说说你对kafka的理解
kafka本身是一个流式处理平台,同时也具有消息系统得能力,在我们得系统中更多得是把kafka作为一个消息队列系统来使用
而如果来介绍kafka,大致可以分为这几块:
- kafka集群元数据得管理,集群得协调工作,这部分其实再2.7版本以前都是由zookeeper来负责,zookeeper相当于注册中心,每个kafka服务器启动的时候去连接到Zookeeper,把自己注册到Zookeeper当中(元数据包括:有哪些主题、主题都有哪些分区、分区有哪些副本,分区的Leader副本等信息)
- kafka得核心概念。
record:代表消息;
topic:主题,其实可以理解成消息的一个分类;
partition:分区,主题会由多个分区组成,通常每个分区的消息都是按照顺序读取的,不同的分区无法保证顺序性
broker:kafka服务器
Leader/Follower:分区的副本。为了保证高可用,分区都会有一些副本,每个分区都会有一个Leader主副本负责读写数据,Follower从副本只负责和Leader副本保持数据同步,不对外提供任何服务
offset:偏移量,分区中的每一条消息都会根据时间先后顺序有一个递增的序号,这个序号就是offset偏移量
producer:生产者,负责发送消息;
consumer:消费者,负责消费消息
Consumer group:消费者组,由多个消费者组成,一个组内只会由一个消费者去消费一个分区的消息
Coordinator:协调者,主要是为消费者组分配分区以及重平衡Rebalance操作
Controller:控制器,其实也是一个broker,用于协调和管理整个kafka集群,比如说负责分区leader的选举,主题管理等工作,再zookeeper中第一个创建临时节点的就是控制器 - kafka的核心数据
kafka以segment日志形式写入磁盘,而每个segment都是由log,index,timeindex文件组成,文件名表示的是一个Segment的起始Offset,log、index、timeindex中存储的都是二进制的数据(log中存储的就是上一部分介绍的BatchRecords的内容,而index和timeindex分别是一些索引信息。)
二、消息队列模型知道吗?kafka是怎么做到支持这两种模型的?
传统的消息队列模型包括点对点和发布订阅模式
点对点很好理解,就是一个生产者对应一个消费者,
发布订阅模式表示 消息可以被所有消费者消费
而kafka是通过消费者组Consumer Group的概念来实现
如果说所有的消费者都同属一个消费者组,那么一条消息只会被这个这个消费者下的一个实例消费,这就是点对点模式
而如果每个消费者都对应一个消费者组,那么就是发布订阅模式
三、能说说kafka通信过程原理吗?
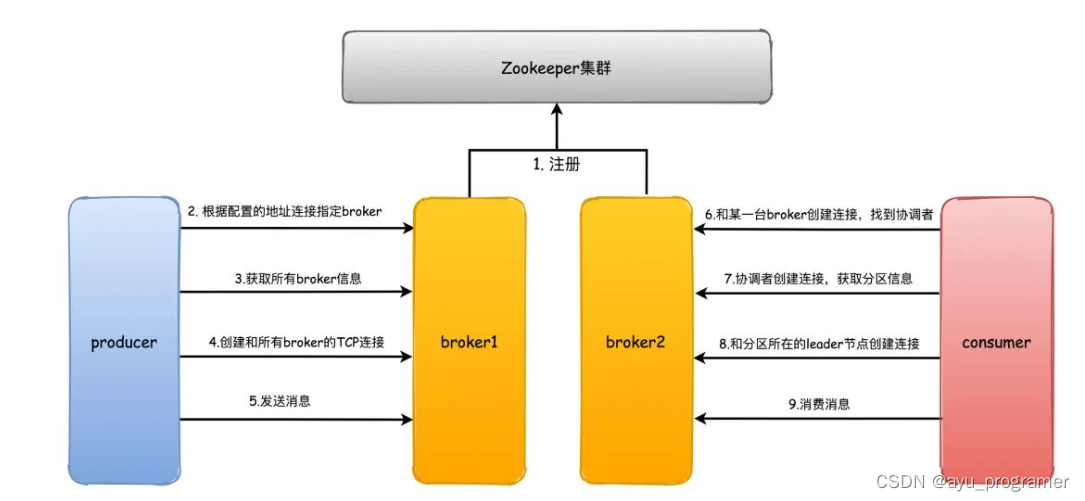
- 首先kafka broker启动的时候,会去向Zookeeper注册自己的ID(创建临时节点),这个ID可以配置也可以自动生成,同时会去订阅Zookeeper的brokers/ids路径,当有新的broker加入或者退出时,可以得到当前所有broker信息
- 生产者启动,而生产者启动的时候会基于你再bootstrap server中配置的broker地址,来与kafka集群创建tcp连接
- 当连接到broker以后,会发送请求获取元数据信息
- 之后就是发送消息的过程
- 消费者和生产者一样,也会指定bootstrap.servers属性,然后选择一台broker创建TCP连接,发送请求找到协调者所在的broker
- 然后会和协调者broker创建TCP连接,获取元数据
- 根据分区Leader节点所在的broker节点,和这些broker分别创建连接
- 最后开始消费消息
四、发送消息时如何选择分区的?
分为有key和没有key
- 如果为消息指定key,那么就会根据消息的key对分区数进行取模,来决定消息落在哪个分区上,所以,对于相同key的消息来说,总是会发送到同一个分区上,也是我们常说的消息分区有序性
- 如果没有指定key和具体的分区,那么就会走kafka默认的轮询策略
五、为什么kafka设计中要引入分区,好处是什么?
我们可以反过来想下如果没有分区的概念,那其实意味着消息都会写入到一台机器,这样一来,非常不利于数据的负载均衡和横向扩展。
因此引入分区使得再发消息时可以根据分区的数量落在不同的kafka节点上,这提高并发写消息的性能,同时消费消息的时候是跟消费者组进行绑定,可以从不同节点的不同分区进行消费消息,提高了读消息的能力
另外一点,就是再分区的基础上又引入了副本,冗余的副本保证了kafka的高可用和高持久性
六、如何保证消息可靠性?
消息可靠性的保证基本上我们都要从3个方面
1 生产者发送消息丢失
kafka支持3种方式发送消息,这也是常规的3种方式,发送后不管结果、同步发送、异步发送
- 发送后不管结果,这种直接调用send方法,有丢失消息的可能
- 同步发送,同步发送返回Future对象,我们可以知道发送结果,然后进行处理
- 异步发送,发送消息,同时指定一个回调函数,根据结果进行相应的处理
我们一般采用的是异步发送并且带有回调的方式进行发送消息,再设置参数为发送消息失败不停地重试
而如果做到这样生产端也是需要作一些配置,就是
把acks=all;retries=N
acks可以取的值是0,1 ,all
0表示生产者写入消息不管服务器的响应,有丢失消息风险
1表示至少有一个副本收到消息才认为成功,这样副本也有没同步导致消息丢失风险
all表示所有ISR都写入成功才算成功,那除非所有ISR里的副本全挂了,消息才会丢失
retries=N,设置一个非常大的值,可以让生产者发送消息失败后不停重试
2 kafka自身消息丢失
针对kafka自身丢失的可能设置参数:
- replication.factor>=2;保证至少有两个或者两个以上的副本数
- min.insync.replicas=N ,这个值用来设置同步副本个数的下限,保证至少写入1个或者以上的副本才算写入消息成功
- unclean.leader.election.enable=false,这个设置意味着没有完全同步的分区副本不能成为Leader副本
3 消费者消息丢失
消费者丢失的可能就比较简单,关闭自动提交位移即可,改为业务处理成功手动提交
具体修改参数
enable.auto.commit=false,设置为手动提交
auto.offset.reset=earliest,这个参数代表没有偏移量可以提交或者broker上不存在偏移量的时候,消费者如何处理。earliest代表从分区的开始位置读取,可能会重复读取消息,但是不会丢失,消费方一般我们肯定要自己保证幂等,另外一种latest表示从分区末尾读取,那就会有概率丢失消息
七、详细说说消费者组和消费者重平衡?
消费者组的好处:可以支持多种消息模型,另外的话根据消费者和分区的消费关系,支撑横向扩容伸缩
当消费者数量小于分区数量的时候,那么必然会有一个消费者消费多个分区的消息。
而消费者数量超过分区的数量的时候,那么必然会有消费者没有分区可以消费。
消费者重平衡主要是通过协调者来完成,每一次新的消费者加入都会发送请求给协调者去获取分区的分配,这个分区分配的算法逻辑由协调者来完成
而重平衡Rebalance就是指的有新消费者加入的情况,比如刚开始我们只有消费者A在消费消息,过了一段时间消费者B和C加入了,这时候分区就需要重新分配,这就是重平衡,也可以叫做再平衡,但是重平衡的过程和我们的GC时候STW很像,会导致整个消费群组停止工作,重平衡期间都无法消息消息。
另外,发生重平衡并不是只有这一种情况,因为消费者和分区总数是存在绑定关系的,上面也说了,消费者数量最好和所有主题的分区总数一样。
那只要消费者数量、主题数量(比如用的正则订阅的主题)、分区数量任何一个发生改变,都会触发重平衡。
八、下面说说重平衡的过程
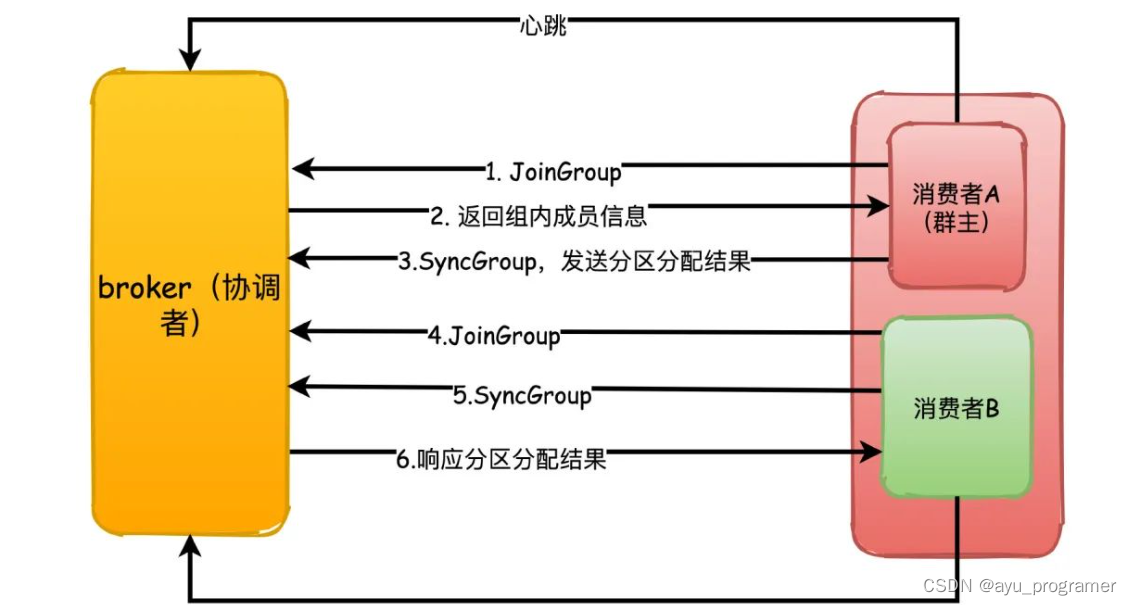
重平衡的机制依赖消费者和协调者之间的心跳来维持,消费者会有一个独立的线程去定时发送心跳给协调者,这个可以通过参数heartbeat.interval.ms来控制发送心跳的间隔时间(默认值 3秒)。
-
每个消费者第一次加入组的时候都会向协调者发送JoinGroup请求,第一个发送这个请求的消费者会成为“群主”,协调者会返回组成员列表给群主
-
群主执行分区分配策略,然后把分配结果通过SyncGroup请求发送给协调者,协调者收到分区分配结果
-
其他组内成员也向协调者发送SyncGroup,协调者把每个消费者的分区分配分别响应给他们
九、kafka的副本和同步原理
Kafka副本的之前提到过,分为Leader副本和Follower副本,也就是主副本和从副本,和其他的比如Mysql不一样的是,Kafka中只有Leader副本会对外提供服务,Follower副本只是单纯地和Leader保持数据同步,作为数据冗余容灾的作用。
在Kafka中我们把所有副本的集合统称为AR(Assigned Replicas),和Leader副本保持同步的副本集合称为ISR(InSyncReplicas)。
ISR是一个动态的集合,维持这个集合会通过replica.lag.time.max.ms参数来控制,这个代表落后Leader副本的最长时间,默认值10秒,所以只要Follower副本没有落后Leader副本超过10秒以上,就可以认为是和Leader同步的(简单可以认为就是同步时间差)。
另外还有两个关键的概念用于副本之间的同步:
HW(High Watermark):高水位,也叫做复制点,表示副本间同步的位置。
LEO(Log End Offset):下一条待写入消息的位移
十、新版本Kafka为什么抛弃了Zookeeper?
- 从运维的复杂度来看,Kafka本身是一个分布式系统,他的运维就已经很复杂了,那除此之外,还需要重度依赖另外一个ZK,这对成本和复杂度来说都是一个很大的工作量。
- 另外Kafka严重依赖ZK来实现元数据的管理和集群的协调工作,如果集群规模庞大,主题和分区数量很多,会导致ZK集群的元数据过多,集群压力过大,直接影响到很多Watch的延时或者丢失。
十一、Kafka为什么快?
首先 Kafka 在写入磁盘文件的时候,可以直接写入这个 os cache 里,也就是仅仅写入内存中,接下来由操作系统自己决定什么时候把 os cache 里的数据真的刷入磁盘文件中。通过这一个步骤,就可以将磁盘文件写性能提升很多了,因为其实这里相当于是在写内存,不是在写磁盘
其次另一个主要功能是 kafka 写数据的时候,是以磁盘顺序写的方式来写的。也就是说,仅仅将数据追加到文件的末尾,不是在文件的随机位置来修改数据
并且kafka再读数据的时候引入零拷贝技术

参考资料
https://kafka.apache.org/documentation/
《kafka核心技术与实战》
https://mp.weixin.qq.com/s/4X5oCIrxxpNf83IV6vwqHQ
https://mp.weixin.qq.com/s/WJ-JnzxVIagzQskN53L__Q
https://www.szzdzhp.com/kafka/qa/acksAndMir#%E6%9C%80%E5%B0%8F%E5%90%8C%E6%AD%A5%E5%89%AF%E6%9C%AC%E6%95%B0-min-insync-replicas















 10万+
10万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









