






题目: On the Security of Machine Leanring in Malware C&C Detection: A Survey
作者: Joseph Gardiner, Shishir Nagaraja
单位: Lancaster University
出版: ACM Computer Survey
问题:C&C(Command and Control)检测系统中ML(Machine Learning)组件的evasion resilience能力
当今在安全方面最重要的挑战之一就是防范恶意攻击。趋势和传闻显示,防范这些攻击,不管是有目标的还是无差别的攻击,都被证实是很困难的:发生入侵,于是设备就被盗用,即使在致力于安全的机构也是如此。因此,人们找到另一条路线,专注于检测并中止跟在最初的盗用之后的,对于攻击的成功是必要的步骤。特别地,人们提出了许多方法技术用来识别命令和控制通道,这种通道是由被盗用的系统建立的,目的是与它的控制者进行通信。
这些检测手段的一个重要的考察方面是它们对于有目的攻击者企图回避检测的意图的弹性(resilience)。C&C检测技术广泛利用一个机器学习组件。因此,为分析这些检测技术的躲避弹性(evasion resilience),我们首先将C&C检测领域的工作系统化,然后利用文献中的现有模型来继续将应对ML组件的攻击方法系统化。
对于C&C通道的检测
- 对恶意软件攻击的防范困难,人们转为对检测与打断攻击的中间步骤,被称为kill chain防范方法,这其中,人们又致力于识别C&C通道
- C&C通道:命令与控制通道,攻击者通过这个通道控制被盗用的设备,并且从这些设备中得到反馈,例如收集敏感信息
- 检测系统包含的三个组成部分:数据收集,特征抽取,和分离模型。数据收集代表了测量步骤,为系统收集输入,例如从网络监测器中获取网络流数据。特征抽取步骤把这些数据处理为能够被分离模型接受的形式。它的输出通常是一个待分离的数据点表示实体(data points representing entities)的集合,例如网络上的主机或观察到的域名。分离模型负责根据数据来做决定。这里有两种方法:一种是将数据标记为正常的或恶意的,另一种方法是将共享某些属性的数据点聚在一起。这个模块通常利用机器学习的方法。这些算法不考虑对抗的环境,利用这些算法的技术不考虑攻击者回避检测的情况。
贡献:
- 提供了一个易于理解的C&C检测技术的概览
- 通过对与ML组件的攻击识别出了C&C检测系统的不足,利用了对抗ML领域的模型
- 解释了为何安全ML算法没有在C&C检测系统中应用
- 给出了利用ML进行C&C检测的研究挑战
恶意软件攻击的危害
目的:
从特定个人或机构获取或泄漏敏感数据
无差别攻击:
- 对金融领域的危害,针对大量机器,例如窃取信用卡密码,网银帐号密码
- DDoS(分布式拒绝服务)
指借助于客户/服务器技术,将多个计算机联合起来作为攻击平台,对一个或多个目标发动DDoS攻击,从而成倍地提高拒绝服务攻击的威力 - 机会主义的攻击造成僵尸网络
指采用一种或多种传播手段,将大量主机感染bot程序(僵尸程序)病毒,从而在控制者和被感染主机之间所形成的一个可一对多控制的网络。攻击者通过各种途径传播僵尸程序感染互联网上的大量主机,而被感染的主机将通过一个控制信道接收攻击者的指令,组成一个僵尸网络的形成
有目标的攻击:
- 窃取特定组织或个人的商业数据,例如合同,商业计划,工业设计等
手段:
- C&C阶段就是攻击者利用被盗用系统的阶段。被盗用系统被强迫与攻击者建立通信通道,通道可以直接被攻击者控制。攻击者可以远程安装其他恶意模块,也可以进行其他恶意行为。通道可以是集中式的,也可以是分散式的。
C&C检测
- 通常在一个网关处进行,收集网络流量
- 问题出在网关处接收的正常的网络流量数量十分巨大(terabytes a day),并且攻击者会采取手段回避检测
- 通常ML组件是检测系统的核心组件。然而给予ML组件安全性的考虑却很少。
C&C检测系统架构
- Data generators:表示能够产生被检测系统评估的数据的实体。通常情况下是一个网络中单独的主机,假设这个主机既生成好的数据点,也生成坏的数据点。data generator也可能是蜜网(honeynets)
是一个网路系统,而并非某台单一主机,这一网路系统是隐藏在防火墙後面的,所有进出的资料都受到监控、捕获及控制。这些被捕获的资料可以对我们研究分析入侵者们使用的工具、方法及动机或沙箱(sandboxes)让疑似病毒文件的可疑行为在虚拟的沙箱里充分表演,沙箱会记下它的每一个动作;当疑似病毒充分暴露了其病毒属性后,沙箱就会执行“回滚”机制:将病毒的痕迹和动作抹去,恢复系统到正常状态 - Data aggregator:将data generator产生的数据汇聚起来,可以是一个网络监控器,也可以是蜜网和沙箱的监控器。在aggregator中会进行数据的初步过滤,例如过滤掉包的载量信息。aggregator是在检测系统之外的。
- Preprocessing:去除掉模型不需要的信息等处理。
- Feature extraction:从数据中抽取ML组件所需要的特征,需要抽取的特征由系统决定。
- (Optional)Data reduction:一些进一步减少数据量,移除FP(false positive)的步骤。
- Separation module:检测系统的核心组件,将输入的数据点分类为“正常”和“恶意”,或者将恶意具体分类。分离模块可以有多种情况,例如可以仅仅进行异常的检测,识别出反常行为。更多时候是一些ML算法,包括监督和无监督(分类和聚类)。若采用分类算法,则模块中应包含已经训练好的分类器,若采用聚类算法,则应包含已经进行过聚类的数据,以方便添加新的数据点。
- Past knowledge:作为分类或聚类的数据集。
- Output:输出分离结果,有时也会输出识别系统需要帮助。
现有的C&C检测方法
主要包括基于签名,基于分类,基于聚类的方法。基于签名的方法试图从新的行为中识别出已知的行为模式,分类模型利用训练好的模型标记样本,聚类将恶意行为划分到正常行为之外。
C&C技术参考Gardiner et al. [2014]
评估标准
TP:恶意软件被标记为恶意软件
FP:正常软件被标记为恶意软件
评估和数据采集
对于需要收集的数据的选择是极其重要的,因为网络规模一般很大,所以很难把整个流量信息储存起来。
高效的监控和数据采集对于检测技术来说是至关重要的。流量监控由路由器进行,通常使用Netflow是一种数据交换方式,其工作原理是:NetFlow利用标准的交换模式处理数据流的第一个IP包数据,生成NetFlow缓存,随后同样的数据基于缓存信息在同一个数据流中进行传输,不再匹配相关的访问控制等策略,NetFlow缓存同时包含了随后数据流的统计信息或sFlow是由InMon, HP 和FoundryNetworks于2001年联合开发的一种网络监测技术,它采用数据流随机采样技术,可提供完整的第二层到第四层,甚至全网络范围内的流量信息,可以适应超大网络流量(如大于10Gbit/s)环境下的流量分析,让用户详细、实时地分析网络传输流的性能、趋势和存在的问题特征。另外还有一些评估设备,它们通过镜像设备或分流器来检测流量,比起用路由器,这些方法更加复杂。这两种方法中网络跟踪都输出到collector中。
基于签名的方法
从恶意样本中抽取出签名,然后新的流量会与这些签名进行对比。数据源可能是蜜网和沙箱,它们能够记录恶意软件的大部分网络行为,包括流量大小到具体包的内容。
通信模式检测
恶意软件通常会具有特殊的通信协议。这就使得基于签名的检测方法在检测已知类型的恶意软件时非常好用。一个流行的方法是根据包的内容来生成签名。尽管一些恶意软件会对包进行加密,但由于加密算法一般比较轻量,因此它们的密文相似度也较高。
- Rieck et al. [2010],生成基于n-gram的签名,95%的检测率,FP几乎为0
- Rossow and Dietrich [2013],通过逆向工程得到密钥,将包破译出来,效果未提及
- Zand et al. [2014],针对僵尸网络检测,自动生成基于文本的签名。从观测到的流量中抽取出常见的字符串,然后用这些字符串对网络跟踪进行聚类,根据熵计算出从这些字符串中得到的信息多少,并对这些字符串进行排序。排位较高的字符串用来生成签名,效果未提及
- Rafique and Caballero [2013],提出了一个大型自动签名生成系统。系统利用从沙箱中收集的网络跟踪来为每组相似的恶意软件生成签名,得到了很高的TP和很低的FP。这种方法将要输出到入侵检测系统,例如Snort中
- Gu et al. [2007],BotHunter是一个通过主机行为,特别是感染和第一次与C&C服务器连接的行为,来识别被盗用主机的系统,达到95%的TP和很低的FP
DNS流量分析
- Nelms et al. [2013],提出了ExecScent,一个通过网络流量识别恶意域的系统。系统生成的签名不仅基于域,还基于与它们相关的完整HTTP请求。为降低FP,它们将要用到的网络的背景流量信息也参与到签名的生成中
恶意服务器检测
- Nappa et al. [2014],提出了CypherProbe,一个自动为恶意软件生成签名的系统。系统通过在蜜网中收集流量信息,进行聚类,再为每一类生成一系列签名。然后系统探测IP并将响应与签名匹配,从而识别出恶意服务器,得到了0%的FP
- Xu et al. [2014],改进了上述工作,通过使用动态二进制分析来生成签名,这种方法不需要正在工作的服务器,就可以抽取出签名,FP同样是0%
分类方法
恶意数据可以从蜜网和沙箱中获取,或者可以收集已经被识别为恶意的流量。正常的数据通常是已经移除恶意成分的流量,或者可以从公开的来源中得到,例如Alexa ranking。
通信模式识别
- Rahbarinia et al. [2013],识别参与恶意的P2P行为的主机,首先一个boosted决策树识别出进行P2P行为的主机,然后识别出主机属于哪个P2P网络。对于每个P2P应用都训练出一个分类器,主机流量分别通过每个分类器,如果某一个分类器的输出得分在阈值之上,则认为主机在运行此应用。如果两个应用同时被匹配则利用随机森林进行选择,这种方法对于不同的数据集效果差别较大。
DNS流量分析
- Bilge et al. [2011],EXPOSURE是一个应用在大型的,被动DNS流量分析上面的系统,旨在识别恶意的域(不仅限于C&C行为)。系统抽取了15个特征(基于时间,DNS,TTL和域名),用决策树算法,TP达到98.5%,FP只有1%
- Antonakakis et al. [2011],Kopis利用上层DNS层级的全局视图。在Kopis中,用发送DNS请求的主机来建立分类器而不是域的IP和域名。这种方法利用了一个事实:恶意的域相比起正常的域来说会有更多不一致的,多变的请求主机。另外,用户分布也在权重设定时被考虑。利用随机森林分类器,得到98%的TP和0.5%的FP。
- Ma et al. [2009],利用流行的分类器来识别恶意的域。
恶意服务器检测
- Bilge et al. [2012],提出了DISCLOSURE,一个从netflow数据中识别恶意服务器的系统,系统抽取与流量大小,客户端访问模式,和临时行为相关的特征。得到TP在60%到70%之间,FP在0.5%到1%之间。为降低FP,自治系统的信息也被考虑进来。
聚类方法
基于签名和基于分类的方法的主要缺点在于它们在面对新的或已升级的恶意软件时就变得不那么高效,这主要是因为它们利用的是固定的数据。基于聚类的方法能够识别出未知的行为。在这样的系统中,算法试图分离不同模式的行为,而不去考虑行为是正常或是恶意的。输出经常被用作生成签名。
- Yen et al. [2013],将日志进行了统一,利用K-means算法
- Zhang et al. [2014],提出一个检测P2P僵尸网络的系统,采用无监督的方法。系统首先对流进行聚类,以得到参与P2P活动的主机,然后应用一个两层的过滤,然后进行分层聚类来得到参与恶意P2P的主机,TP达到100%,FP达到0.02%
- Yahyazadeh and Abadi [2015],在BotGrab中利用一个定制的网络流量聚类算法进行聚类,然后应用一个reputation引擎来识别有negative reputation的主机。Reputation是基于对于同步活动的参与,这是主机是僵尸网络一员的证明。Reputaion引擎可以与参加恶意行为的主机相关信息结合起来,TP达到97%,FP达到2.3%
- Yen and Reiter [2008],提出TAMD,通过聚合相似的网络流量来识别被感染的计算机。他们提取的特征包括通信目的地址,包载量,主机平台(OS),利用k-means算法,检测率达到87%,能够检测除IRC僵尸网络外的大部分情况。
DNS流量分析
- Antonakakis et al. [2010],利用域名的评价(reputation)来确定它们是否与恶意行为有关。在Notos中域首先根据IP地址进行聚类,然后根据域名在语法上的相似性进行聚类,TP达到96%,FP很低。
- Schiavoni et al. [2014],提出一种基于域名生成算法(domain generation algorithm, DGA)的方法。首先过滤掉人们能够读出来的域名,剩下的域与黑名单中的域一起进行聚类,利用DBSCAN算法,特征选取与域的IP相关,能够过滤出35%到62%的域名,召回率81%到94%。
fast flux检测
在fast-flux网络(FFSN)中,C&C服务器隐藏在许多被盗用的主机代理之后。在此台服务器的域中进行DNS查询会返回一个很大的且不断变化的IP地址集合。这种行为其实是很容易检测的。
- Holz et al. [2008],检测FFSN是容易的,因为它的两个特性:DNS响应的TTL值很短,以及DNS响应是非重叠的
- Perdisci et al. [2012],利用分层聚类将域根据返回IP地址的重叠,然后这些分组被分为flux或nonflux,得到少于1%的FP
杂交(hybrid)检测系统
- Gu et al. [2008],BotMiner通过聚类显示出相似通信和(被怀疑是)恶意活动的主机来检测被感染的主机。活动通过Snort IDS的签名来监测。系统在插入8个僵尸网络的情况下,其中六个达到了100%的TP,另外两个TP达到99%和75%,FP都很低
- Antonakakis et al. [2012],描述了一个能够识别出以前未见过的域生成算法(DGA)的系统,基于一个事实:DGA导致出现很多不存在的域(NXDomain)的响应,并且在相同僵尸网络中的僵尸会产生相似的NXDomain流量。算法用到ADTree,x-means,以及HMM,找到了以前未发现的DGA,TP达到99.7%,FP达到0.1%
基于图的检测
基于图的检测能够有重要的应用是因为图本身就能够很好地表示通信模式。这些方法同样利用ML,但它们利用了图作为算法的数据组件。
- Collins and Reiter [2007],通过一个僵尸网络控制的流量的特定协议流图(a graph of protocol-specific flows by botnet control traffic)来检测异常。它们认为僵尸网络可以通过观察攻击者行为来检测,攻击者通常会增加连接的图组件的数量,因为一般不会连接的相邻结点间的边数会突然增加。TP达到65%到90%,FP很低
- Illiofotou et al. [2008, 2009],利用流量图的动态性来分类网络流量,从而检测P2P网络。
- Nagaraja et al. [2010],提出一个利用数据挖掘检测P2P网络的技术,基于随机游走来寻找expander graph,TP达到98%,FP达到0.4%
- Nagaraja [2014],通过生成一个通信图的对偶图,应用Laplace-Beltrami操作符来降低数据维度,然后利用随机游走来抽取P2P网络,TP达到99%,FP低于0.1%
- Invernizzi et al. [2014],利用基于图的方法从大型网络中检测出恶意感染过程中的二进制下载阶段。图的结点表示IP地址,域名,FQDN,URL,URL路径,文件名,以及已下载的文件(表示为哈希)。对于正常下载精确度60%,召回率90%,对于恶意下载精确度99.69%,召回率98.14%
- Manadhata et al. [2014],在图模型中包含了置信度传播来检测恶意域。TP达到95.2%,FP达到0.68%,系统几乎可以实时运行。
- Jiang et al. [2010],利用基于图的方法来对可以的域名进行分组。他们关注DNS失败,在这种情况下域的查询会返回unresolved。
ML算法的弱点
早期的C&C检测系统是设计来检测无差别恶意攻击的。然而这个世界已经改变了(???),更加复杂的,有针对性的攻击方法有所增加,这些攻击会刻意躲避检测/ML系统。早期的ML算法的弱点就存在于它的设计意图上。在ML组件设计前缺少威胁建模,算法的选择多是被TP和FP驱动的,而缺少对于安全的考虑。
攻击者
- 无差别攻击者:攻击目标通常是没有任何检测系统的个人或小公司
- 有目标的攻击者:通常是知识丰富的专业人士,为了获得巨大的利益来进行攻击
攻击形式
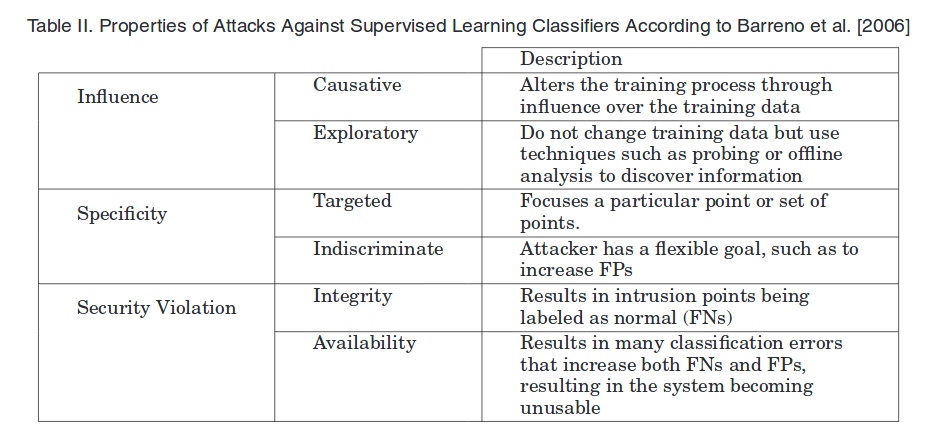
攻击目标
- 攻击者希望能够隐藏自己的存在
- 攻击者企图危害检测系统的完整性而使检测系统不可用
Biggio et al. [2014c]相比Barreno更加精确地描述了攻击形式。
攻击者的知识
可以分为三部分:分类器(及其参数),特征集,训练数据。其中:
- 分类器训练数据可能为publicly available
- 聚类算法的输入较难得到(可能全部是新的流量数据)
fig3
对于不同系统,攻击者能够获得的知识不同,可分为开源(公开数据集,算法和至少一部分特征)和商业系统(只能通过探针或逆向工程获取部分信息)。
有动机的攻击者可以试图获得组织机构和监测系统提供商之间的通信联系。
攻击者能力
对于攻击者能力的四个评估标准(针对分类)
- 攻击者在诱发和探索方面的影响
- 攻击者是否能影响分类的优先级,或是影响到什么程度
- 每个类中多少/哪些样本(训练&测试)可以被控制
- 哪些特征可以被攻击者修改,修改到什么程度
针对聚类也同样适用
针对ML算法的攻击
列出针对Table 1的攻击,攻击按目标分为evasion和poisoning,按针对的算法分为分类和聚类,每种列出几种技术,给出例子,评价其局限性;图留到今后的工作中进行。
evasion attacks: classifier
mimicry attack
目标是设计出一个攻击点,此攻击点(attack point)看似是一个正常的点,实际上是一个exploratory,一种既可以有目的也可以无差别的完整性攻击。攻击试图将攻击点移到正常区域,或是模仿一个特定的正常的点。攻击试图修改攻击点的特征,这样异常检测或是分类其就会将其标注为正常。
能够影响的算法:所有利用攻击点和正常点之间距离进行分类的算法,随机森林,Bayes,SVM,决策树。
实例:
- Wagner and Soto,针对一个基于host的IDS,IDS的目标是识别出被IDS接受,并且依然带有恶意活动的系统调用trace,攻击可以通过添加no-ops,或移除导致警报的系统调用,用能达到同样目的的序列替换掉它。
- Srndic and Laskov,攻击PDFRate,一个检测恶意PDF文件的系统。通过在PDF文件的交叉引用表和trailer之间插入数据,攻击者可以影响PDFRate的输出,但并不影响文件在普通PDF阅读器中的组织,在普通阅读器中。攻击者基于PDFRate中提到的70%特征,能够修改35个特征,最终PDFRate输出的分数能够降低28%到42%
- Biggio et al,通过梯度下降的方法来不断修改攻击点的特征,从而逃过SVM和神经网络。
流量改变(traffic morphing)与mimicry攻击类似,能够逃过Bayes分类。
局限性:攻击者修改特征的能力。这种方法与分类器算法无关,因为它的重点在于利用区分恶意和正常点的知识。
- 有些特征不能被修改
- 有些特征修改不到能够达到效果的程度
梯度下降攻击
适用于分类和聚类。通过梯度下降算法来寻找到一个攻击点能够达到预期的效果,即逃避分类/聚类。常用的方法是生成一个攻击点,然后在surrogate learner上测试它的有效性,如果没有效果就再应用梯度下降生成一个新的点,直到有点满足要求。
影响的算法:几乎所有分类算法。
实例:
- Srndic and Laskov,作为mimicry的对比实验,能够将PDFRate的输出分数减少29%到35%
- Biggio et al,与mimicry结合,见上节。
局限性:
- 局限于攻击者能够修改的特征值
- 局限于攻击者所知的有关分类模型的知识
其他攻击
- Genetic programming,Xu et al.利用遗传(genetic programming)的方法来躲避PDF恶意分类器,特别针对PDFRate和Hidost系统。与之前工作不同,这种攻击把被攻击系统当成一个黑箱,这种方法通过生成代表原文件操作序列的攻击轨迹来导致误分类。轨迹通过迭代方法计算生成,通过随机地对文件进行操作(例如在一个正常的文件中插入一页)。这种修改通过一个fitness function进行评估,其中包括其在目标检测系统中的得分,以及这个文件是否仍旧能够进行恶意行为。攻击从把一系列恶意文件作为初始文件开始,然后进行修改。
- Tree ensemble evasion,分别利用MILP和ICD算法。
Evasion Attacks: Clustering
Mimicry Attacks
通过减少攻击点和正常点之间的距离来进行躲避。对于层次聚类和k-means聚类有效。然而对k-means的限制是,如果k过大,那么输出的聚类就会很紧密,也就意味着攻击点几乎需要完全扮成正常点。
梯度下降攻击
适用于任何基于距离的聚类算法。攻击的限制在于攻击者需要了解其它点的知识,并且真实数据与攻击者假设的数据集之间的区别也会影响到攻击的效果。
聚类算法的参数以及k也会对攻击效果产生影响。
Poisoning Attacks: Classifiers
Label-Flipping Attacks
一种poisoning attack,目标是在训练数据中引入噪声。攻击者能够将一定量的恶意样本标注为良性样本,或将一定量的良性样本标注为恶意,旨在将分类错误最大化。
在实际应用中,攻击者需要在数据收集阶段对数据产生影响。一种方法就是使用蜜罐或沙箱。恶意软件可以被编程为在沙箱中值表现出正常行为,这样就可以创建出被标注为恶意的正常样本。
已被证实对于SVM分类器可行,虽然它应该适用于任何一种能被噪声影响的分类算法。
- Xiao et al. [2012],提出一种针对SVM的诱发性的攻击。攻击者flip训练点的标签,利用选出的攻击点来控制最大损失。在人工制造的数据集中错误率能够达到32%,在10个真实数据集中进行测试时能够将分类变成随机猜测(50%错误率),通过改变10%的训练集的标签。对于RBF kernel的效果比对线性kernel的效果更好。
这种攻击的限制在于budget,以及攻击者对于分类器以及训练数据的知识。
Gradient Descent Attacks
梯度下降攻击将攻击点插入到训练数据中,并使其对分类器的影响最大化,旨在将分类器性能降低到不能用。通常的做法是从一个正常点开始,改变它的标签并且移动它,来使目标函数最大。
已被证明对SVM有影响。
- Biggio et al. [2012],攻击假设具有训练集的知识。攻击者改变目标类的点的标签来获得一个原始的攻击点,然后应用梯度下降来得到一个最理想的攻击点,并将其加入训练集。
攻击的限制在于攻击者能够注入的噪声的量。例如,当攻击一个垃圾邮件过滤系统,系统的标签都由用户产生,攻击者只好祈求神喻,将点按照他们所希望的方式进行标注。
字典攻击
分类特征基于语句。恶意数据中含有正常数据所包含的语句,字典攻击的目的是希望正常数据被误分类为恶意数据。
- Nelson et al. [2008],攻击SpamBayes,共有两种方法,第一种是无差别攻击,向有SpamBayes的目的地发送包含正常单词的邮件,以增加正常邮件被分类为恶意的几率。第二种攻击是有目的的攻击,攻击者不希望收件人获得邮件里的内容,因此使它出现在了收件人的垃圾箱内。
这种方法的限制是攻击者对于目标邮件的结构知识。
Poisoning attacks: Clustering
Bridging Attacks
攻击在聚类之间插入点,目的是使聚类分裂融合。
受到影响的算法:攻击对于使用intercluster distance的算法非常有效,也会影响到centroid-based算法,例如k-means,虽然程度上可能不大。
- Rieck et al. [2011],提出Malheur,文章假设攻击者攻击优化问题,它的目标函数是聚类之间的距离。攻击的目标是导致聚类融合,直到系统变得不可用。攻击是迭代性的,持续向系统中添加新的点,直到目标函数最大化。
攻击的限制:为得到最大化的结果,攻击者需要目标分类器的PK,而这在实际情况中可能是不真实的假设。攻击者仅仅需要一个其他聚类的知识来进行bridge attack。
Gradient Descent Attacks
诱发性攻击。攻击点插入聚类中使聚类分割,或许可能导致融合。攻击点被创造,并且最有效的攻击点是通过利用梯度下降方法使目标最大化来发现的。
影响的算法:这一类攻击已被证明了对分层聚类有效。对k-means等centroid-based聚类算法也能起到一定的作用,然而需要很多的攻击点。
- Biggio et al. [2014a],攻击点被添加到聚类的边缘,目标是导致聚类分裂,然后可能会与另一个融合。攻击迭代进行,旨在使目标函数(代表受到攻击和没受到攻击时聚类输出的距离)最大化。
攻击的限制:受限于攻击者能够注入的噪声的多少。基于数据密度,攻击者可能需要添加大量的攻击点来使性能下降。
其他攻击
attack on ASG(签名)
- Perdisci et al. [2006a],提出一个攻击Polygraph的方法。Polygraph是一个为检测多态蠕虫(polymorphic worms)自动生成签名的系统。系统假设攻击者控制了主机A,并想要感染主机B,就会发送一个恶意流到B,包含攻击代码。因此系统希望能够能用B来收集流量输入系统。
攻击者向系统发送除恶意流量之外的多余流量,使得签名只包含有关协议框架的数据,而不是有关蠕虫的数据。 - Newsome et al. [2006],提出一种“红色鲱鱼(red herring)”攻击。攻击在攻击样本中包含欺骗性的特征,这些特征随后会被包含到签名中,为躲避检测,攻击者停止对多余特征的包含。
attacks on IDSs
- Fogla et al. [2006],提出多态混合攻击,这种攻击扩展了多态(polymorphic)攻击,通过添加混合组件,类似于mimicry攻击。
新出现的基于主机的躲避技术
躲避签名
例如攻击者能够改变现有的恶意二进制文件,创建一个新的版本,新版本中保留了恶意功能,却能保证不被当前的签名检测到。
躲避动态分析系统
动态分析系统,也叫沙箱,在一个物联化的环境中执行二进制程序,并且依据观察到的行为来将其分类为正常或恶意。为检测沙箱,攻击者利用了真实主机和虚拟环境中执行特性的不同。
躲避信誉系统
恶意软件作者有一个粗鲁却有效的方法。它们用一个服务器或域来进行恶意攻击,并且攻击时间限制到非常短。
为什么安全的ML没有应用到C&C检测
- 缺少安全意识
- 实现的容易程度:安全的ML算法相比起流行的k-means或SVM等算法,可用的软件,API等较少,并且要想应用在希望应用的场景下可能需要大量预处理
- 下降的性能:安全的ML算法无论是从处理时间还是关键矩阵,性能都有所下降
- 缺少清晰的安全矩阵:当使用ML算法时,通常会参考标准性能矩阵(TP/FP,精确度,召回率,计算效率等),然而目前并没有度量ML算法躲避弹性的矩阵
- 缺少攻击的证据:目前来说,对于ML组件的攻击还比较少,攻击者往往喜欢攻击更加简单的组件。然而对与ML组件的攻击变得普遍只是时间的问题
在C&C中应用攻击的困难性
上面讨论过的几乎所有ML算法都是应用在简化过的场景中,在这些场景中,数据点是容易修改的。然而在恶意软件的C&C场景中,特征可能不如其他场景容易修改。例如一个通过TCP简单发送数据到中心服务器的C&C通道。有些特征,例如包内容长度,n-gram,包的数量和大小,对攻击者来说是易于修改的。然而其他的特征,例如表示IP地址,端口号,或协议标志的不容易被修改,它们或会对攻击效果产生影响,或者修改后就不再受攻击者控制了。
攻击者知识获取知识的可能性
攻击者能够获得多少知识,取决于攻击者的目标。通过社会工程技术(social engineering techniques),攻击者可以破解特定的检测系统,得到算法相关信息,以及相应特征,或是通过出版信息,或是通过逆向工程。如果目标系统是一个现成的产品,攻击者可以购买一份进行利用。
关于训练数据的知识也取决于特定的目标。训练数据有可能不会公开,也有可能为了特定场景而剪裁。在实际场景中,攻击者很难去创建一个surrogate training。
对整个C&C检测系统的有效性
尽管ML是整个系统的核心组件,但却不是唯一的组件。很多系统会对数据进行很多预处理和后处理,包括但不限与黑名单/白名单,噪声消除,以及数据采样。上面提及的攻击通常关注的是测试样本仅通过特征抽取和ML算法的场景。因此,C&C检测的其他步骤能够影响上述攻击到什么程度不得而知。上述组件也可能会对攻击起到帮助作用。
目前检测方法的缺陷
- 缺少数据集
法律需求通常认为数据集在被创建后不能公开,因此每个系统都需要创建自己的数据集。这些数据可能并不是真实场景的表示。 - 缺少数据集的再现性
C&C检测系统利用从真实网络中收集的网络追踪来进行评估。这些数据,出于合同和隐私的考虑,几乎从不会送与他人使用。这就导致了评估结果难以复现。 - 在已知的恶意软件上测试
这个问题在依靠分类器的系统上表现尤其明显。这些系统在一小部分已知的恶意样本上进行测试,这些样本被用来生成签名,然后来自同样样本的流量被用来生成测试集。这相比起真实情况下,检测率会更高。 - 缺少可扩展性测试
由于在数据获取和处理方面资源的有限性,监测系统的测试或是在自然环境下进行小规模的测试,或是利用批处理模式,这需要花很长的时间。很多系统设计的目的是应用在一个公司的网络甚至是一个ISP上,这种环境下数据量会比测试环境大得多,并且要求接近于实时检测。一些在小规模环境中能够正常工作的系统可能在大规模环境中崩溃。
攻击防范
防范针对ML的攻击是困难的。防卫者可以采取回应式或是积极的方法。在回应式的方法中,防卫者观察一个攻击然后在当前系统中包含对于该攻击的对策。积极的方法是防卫者参与攻击者的策略,并且在部署之前想出对策。实际情况下大部分的防卫是积极的。有两种常用的方法,一是多分类系统(MCSs)的使用,二是来自于博弈论,在不利用攻击者数据的情况下预测并模拟攻击。
- Kolcz and Teo [2009],使用了一种防御躲避攻击的手段MCS,即结合了多个分类器的输出来做出决定。不同的分类器或是取了不同的特征子集,或是用了不同的训练数据。
- Biggio et al. [2015], 利用单类分类器进行检测,输出的不是标签,而是一个数据点与目标匹配的程度。这种方法在未受到攻击时效果不如普通分类器,受到攻击时效果比普通分类器要好。
- Zhang et al. [2015],利用前向特征选择和后向特征消去来增强检测系统对躲避攻击的抗性。
开放的挑战
- 我们需要ML技术的干净的基础设计,在此设计过程中就应将攻击对手考虑进来,而不是为已经使用的不考虑攻击对手的ML技术添加层。
- 尽管我们关注检测步骤,一个有准备的攻击者躲避这些评估步骤。
结论
学术界和工业界都已经防范恶意C&C通信通道将近十年。专家们一次又一次声明这个问题已经解决,仅仅为了发现他们的信心又被新的攻击击倒。















 343
343

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









